
Adaptive Boosting or AdaBoost is one of the earliest implementations of the boosting algorithm. It forms the base of other boosting algorithms, like gradient boosting and XGBoost. In this post, we are going to explore Adaptive Boosting Algorithm in detail.
Ensemble approaches have shown exceptional capabilities in improving the accuracy of classical machine learning approaches such as Support Vector Machines or decision trees and are often used to overcome the difficulty of training imbalanced data.
An ensemble method combines a number of weak classifiers to generate a machine learning method that is better than its ingredient simple classifiers.
Class-imbalance is considered as one of the most challenging problems in machine learning, and it occurs in a learning task where there are considerably less data instances in one class compared to the other class.
AdaBoost is an ensemble approach which can identify misclassified instances that occur because of the disjunct problem. The disjunct problem is apparent in datasets which contain instances in a class that are clustered in a number of separate small groups, and each group contains a small number of instances that cannot be disregarded and should be trained.
What is AdaBoost?
AdaBoost is one of the boosting algorithms (supervised learning) to have been introduced that can be used in a wide variety of classification and regression tasks, and the base learner.
AdaBoost is a Machine Learning approach that is utilized as an Ensemble Method. AdaBoost’s most commonly used estimator is decision trees with one level, which is decision trees with just one split. These trees are referred as Decision Stumps.
This approach constructs a model and assigns equal weights to all data points. It then applies larger weights to incorrectly categorized points. In the following model, all points with greater weights are given more weight. It will continue to train models until a smaller error is returned.
What is Decision Stamp?
Decision Stamps use a slightly different approach from that of traditional boosting algorithms. A decision stump is a machine learning model consisting of a one-level decision tree. That is, it is a decision tree with one internal node (root) which is immediately connected to the terminal nodes (leaves).
A decision stump makes a prediction based on the value of just a single input feature also called 1-rules.
Depending on feature type, several variations are possible.
For nominal features, one may build a stump which contains a leaf for each possible feature value or a stump with the two leaves, one of which corresponds to some chosen category, and the other leaf to all the other categories.
For continuous features, some threshold feature value is selected, and the stump contains two leaves, for values below and above the threshold. However, rarely, multiple thresholds may be chosen and the stump therefore contains three or more leaves.
For binary features these two schemes are identical. A missing value may be treated as a yet another category.
Decision stumps are often used as components (called weak learners or base learners) in ensemble techniques such as bagging and boosting.
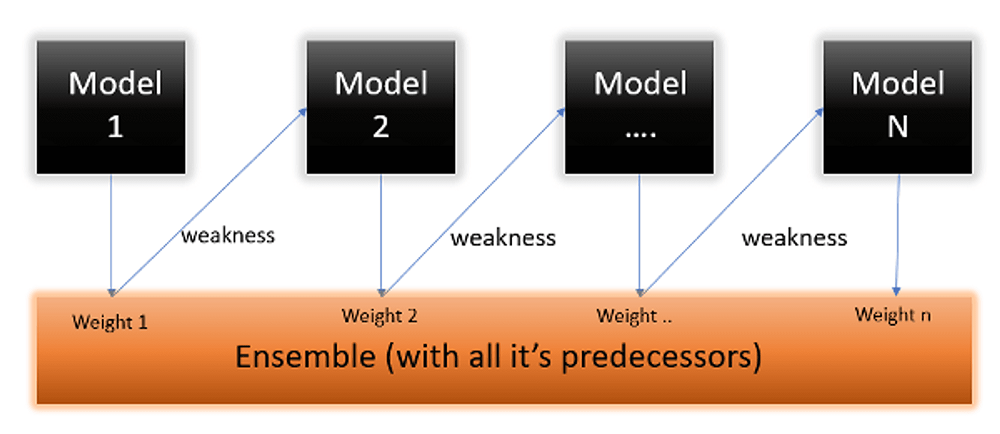
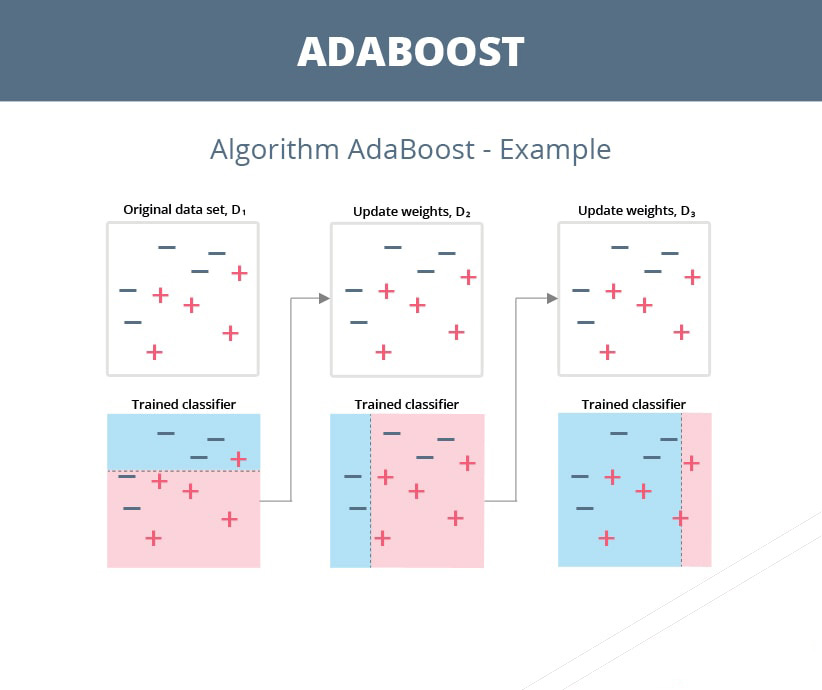
AdaBoost Algorithm
- First, AdaBoost selects a training subset randomly. At first, all of the weights will be equal.
- It iteratively trains the model by selecting the training set based on the accurate prediction of the last training.
- It assigns higher weight to wrong classified observations so that in the next iteration these observations will get high probability for classification.
- It assigns the weight to the trained classifier in each iteration according to the accuracy of the classifier. The more accurate classifier will get high weight.
- This process iterates until the complete training data fits without any error or until reached to the specified maximum number of estimators.
Weights Formula
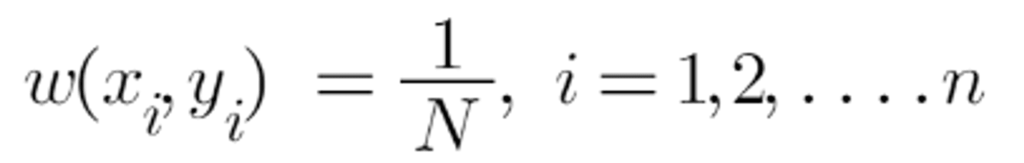
Importance or Influence Formula
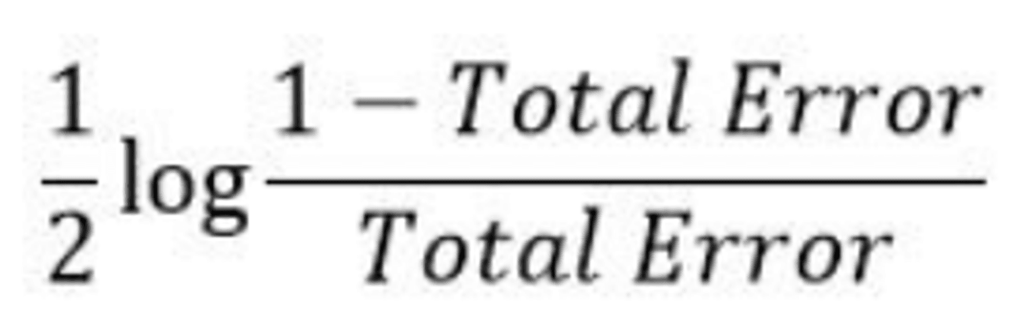
Weights Update Formula
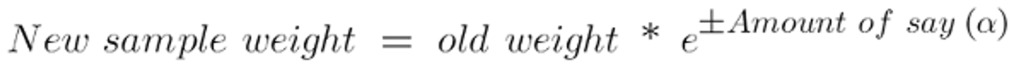
Adaptive Boosting Infographic
Adaptive Boosting Advantages
- Less parameters tweaking.
- It is less prone to overfitting.
- Help in reducing bias and variance.
- AdaBoost is fast, simple to implement.
- It is highly effective in binary classification problems and can be used to solve multi-class problems.
Adaptive Boosting Disadvantages
- Need to quality dataset.
- Hyperparameter optimization is difficult.
- Slower than the other algorithm like XGBoost.
- Adaboost is not suitable for noisy data and is sensitive to outliers.
I hope I’ve given you good understanding of AdaBoost Algorithm.
I am always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Hierarchical Clustering Python
Gradient Descent Machine Learning


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained