



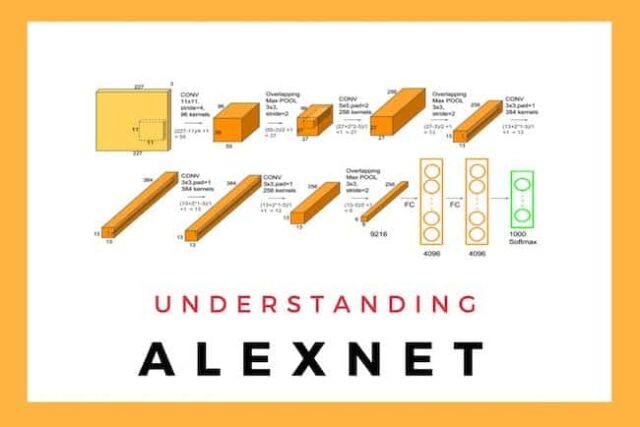

AlexNet is the name of a convolutional neural network (CNN) architecture, designed by Alex Krizhevsky. AlexNet competed in the ImageNet Large Scale Visual Recognition Challenge on September 30, 2012. The network achieved a top-5 error of 15.3%, more than 10.8 percentage points lower than that of the runner up. The original paper’s primary result was that the depth of the model was essential for its high performance, which was computationally expensive, but made feasible due to the utilization of graphics processing units (GPUs) during training.
AlexNet Architecture
- AlexNet architecture consists of 5 convolutional layers, 3 max-pooling layers, 5 normalization layers, 2 fully connected layers, and 1 softmax layer.
- Each convolutional layer consists of convolutional filters and a nonlinear activation function ReLU.
- The pooling layers are used to perform max pooling.
- Input size is fixed due to the presence of fully connected layers.
- AlexNet overall has 60 million parameters.
AlexNet Implementation
AlexNet is probably one of the simplest methods to approach understanding deep learning concepts and techniques. AlexNet is not a complicated architecture when it is compared with some state of the art CNN architectures that have emerged in the more recent years.
AlexNet is simple enough for beginners and intermediate deep learning practitioners to pick up some good practices on model implementation techniques.
At the end of this post is a GitHub link to the python file that includes all code in the implementation section.
Libraries
We begin implementation by importing the following libraries:
- TensorFlow: An open-source platform for the implementation, training, and deployment of machine learning models.
- Keras: An open-source library used for the implementation of neural network architectures that run on both CPUs and GPUs.
- Matplotlib: A visualization python tool used for illustrating interactive charts and images.
Dataset
The CIFAR-10 dataset contains 60,000 colour images, each with dimensions 32x32px. The content of the images within the dataset is sampled from 10 classes.

The CIFAR dataset is partitioned into 50,000 training data and 10,000 test data by default. The last partition of the dataset we require is the validation data. The validation data is obtained by taking the last 5000 images within the training data.
Training Dataset: This is the group of our dataset used to train the neural network directly.
Validation Dataset: This group of the dataset is utilized during training to assess the performance of the network at various iterations.
Test Dataset: This partition of the dataset evaluates the performance of our network after the completion of the training phase.
Model Implementation
Here are the types of layers the AlexNet CNN architecture is composed of, along with a brief description:
Convolutional layer: A convolution is a mathematical term that describes a dot product multiplication between two sets of elements. Within deep learning the convolution operation acts on the filters/kernels and image data array within the convolutional layer. Therefore a convolutional layer is simply a layer the houses the convolution operation that occurs between the filters and the images passed through a convolutional neural network.
Batch Normalisation layer: Batch Normalization is a technique that mitigates the effect of unstable gradients within a neural network through the introduction of an additional layer that performs operations on the inputs from the previous layer. The operations standardize and normalize the input values, after that the input values are transformed through scaling and shifting operations.
MaxPooling layer: Max pooling is a variant of sub-sampling where the maximum pixel value of pixels that fall within the receptive field of a unit within a sub-sampling layer is taken as the output. The max-pooling operation below has a window of 2×2 and slides across the input data, outputting an average of the pixels within the receptive field of the kernel.
Flatten layer: Takes an input shape and flattens the input image data into a one-dimensional array.
Dense Layer: A dense layer has an embedded number of arbitrary units/neurons within. Each neuron is a perceptron.
Other techniques utilized within the AlexNet CNN that are worth mentioning are:
Activation Function: A mathematical operation that transforms the result or signals of neurons into a normalized output. The purpose of an activation function as a component of a neural network is to introduce non-linearity within the network. The inclusion of an activation function enables the neural network to have greater representational power and solve complex functions.
Rectified Linear Unit(ReLU) Activation Function: A type of activation function that transforms the value results of a neuron. The transformation imposed by ReLU on values from a neuron is represented by the formula y=max(0,x). The ReLU activation function clamps down any negative values from the neuron to 0, and positive values remain unchanged. The result of this mathematical transformation is utilized as the output of the current layer and used as input to a consecutive layer within a neural network.
Softmax Activation Function: A type of activation function that is utilized to derive the probability distribution of a set of numbers within an input vector. The output of a softmax activation function is a vector in which its set of values represents the probability of an occurrence of a class or event. The values within the vector all add up to 1.
Dropout: Dropout technique works by randomly reducing the number of interconnecting neurons within a neural network. At every training step, each neuron has a chance of being left out, or rather, dropped out of the collated contributions from connected neurons.
The compilation processes involve specifying the following items:
Loss function: A method that quantifies ‘how well’ a machine learning model performs. The quantification is an output(cost) based on a set of inputs, which are referred to as parameter values. The parameter values are used to estimate a prediction, and the ‘loss’ is the difference between the predictions and the actual values.
Optimization Algorithm: An optimizer within a neural network is an algorithmic implementation that facilitates the process of gradient descent within a neural network by minimizing the loss values provided via the loss function. To reduce the loss, it is paramount the values of the weights within the network are selected appropriately.
Learning Rate: An integral component of a neural network implementation detail as it’s a factor value that determines the level of updates that are made to the values of the weights of the network. Learning rate is a type of hyperparameter.
Epoch: This is a numeric value that indicates the number of time a network has been exposed to all the data points within a training dataset.

One thought on “Alexnet Architecture Code”