
Anomaly detection is the process for find the outliers or noises of a dataset. These anomalies might point to unusual network traffic, uncover a sensor on the fritz, or simply identify data for cleaning, before analysis.
In today’s world, anomaly detection is especially important in industries like finance, retail, and cybersecurity, but every business should consider an anomaly detection solution. It provides an automated means of detecting outliers and protects your data.
Data is the lifeline of your business and compromising it can jeopardize your operation. Without anomaly detection, you could lose revenue and brand equity that took years to cultivate. Your business faces security breaches and the loss of sensitive customer information. If this happens, you stand to lose a level of customer trust that may unrecoverable.
Challenge of Anomaly Detection
Even in these common use cases, above, there are some drawbacks to anomaly detection.
Anomaly detection systems are either manually built by experts setting thresholds on data or constructed automatically by learning from the available data through machine learning. It is tedious to build an anomaly detection system by hand. This requires domain knowledge and even more difficult to access foresight, furthermore it creates a system that cannot adapt or is costly and untimely to adapt.
For an ecosystem where the data changes over time, like fraud, this cannot be a good solution. Building a wall to keep out people works until they find a way to go over, under, or around it.
Anomaly detection for time series data brings its own challenges due to the inherent complexity in separating noise from an anomalous pattern. Knowing if the data is stationary, and considering trends and seasonality are critical for doing time series analysis. Additionally, anomalies can be global outliers, or contextual anomalies, which means that there is a departure from a set of data points in context.
Types of Anomaly Detection
An anomaly can be categorized into three categories:
- Point Anomaly: A tuple in a dataset is said to be a Point Anomaly if it is far off from the rest of the data.
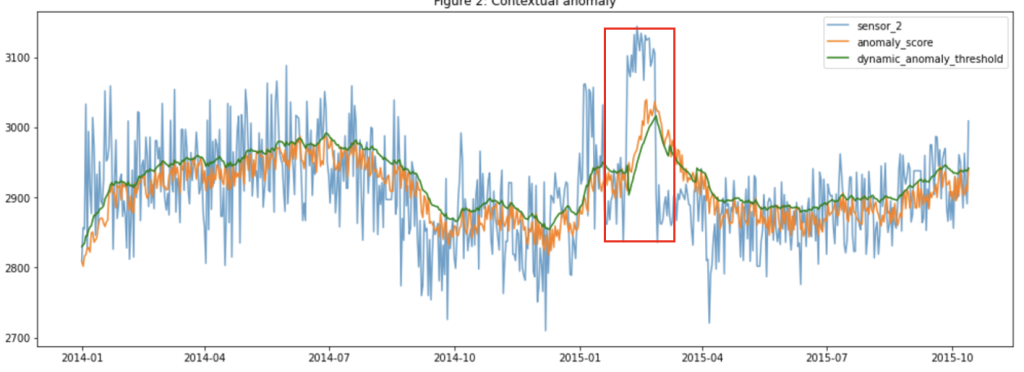
- Contextual Anomaly: An observation is a Contextual Anomaly if it is an anomaly because of the context of the observation.
- Collective Anomaly: A set of data instances help in finding an anomaly.
Anomaly detection can be done using Machine Learning in the following ways:
- Supervised Anomaly Detection: Supervised anomaly detection aims to learn a model by using labeled data that represents previous failures or anomalies.. The most commonly used algorithms for this purpose are supervised Neural Networks, Support Vector Machine learning, K-Nearest Neighbors, etc.
- Unsupervised Anomaly Detection: This method does require any training data and instead assumes two things about the data ie only a small percentage of data is anomalous and any anomaly is statistically different from the normal samples. Based on the above assumptions, the data is then clustered using a similarity measure and the data points which are far off from the cluster are considered to be anomalies.
- Semi-supervised anomaly detection: relies on a small amount of labeled data to validate and select the best performing model trained on normal data. Given the scarcity of labeled failure data, the most applicable use cases are those of unsupervised and semi-supervised anomaly detection.
- AutoOptimizer Package: It uses Interquartile Range, Z-Score, Standard Deviation and Local Outlier Factor (LOF) methods to remove outliers from any dataset.
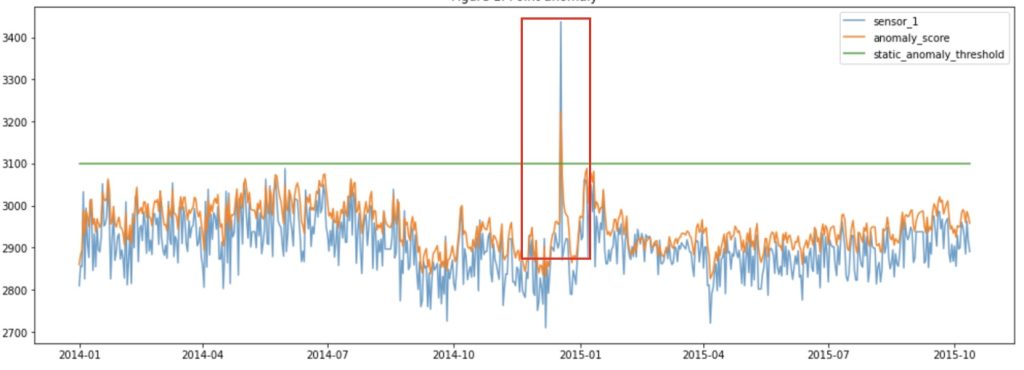
Image source: IBM Developer
Anomaly Detection use cases
Anomaly detection can be performed for a variety of reasons, such as:
- Outlier detection, which is used to detect any outliers that largely varies in range from the normal operating range or state of the system within the training data. In this case, the complete data is analyzed to find outliers outside the range.
- Novelty detection, is a type of anomaly detection where the training data consists of sensors or values operating under normal conditions where an anomaly does not occur, and the goal is to identify if the testing data or new data from the stream contains any novel behavior, therefore, labeling it an anomaly, or a novelty.
- Event extraction, can be done if the data operates under multiple states, and the goal is to identify when the sensors behave in a different way when an event occurs.
Summary:
This post provided an overview of anomaly detection for dataset, challenges associated with it, and techniques that can help identify the best anomaly model for a data set. Thanks for taking the time to read this post.
Recommended for you:
Data PreProcessing
Feature Engineering in Machine Learning


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained