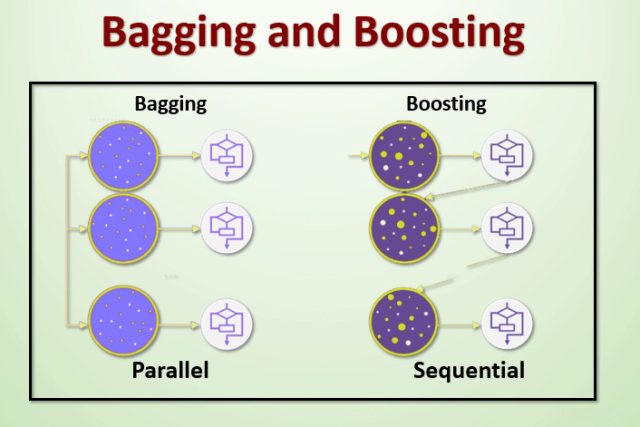
Bagging, boosting are the most popular ensemble learning methods. Each of these techniques offers a unique approach to improving predictive accuracy. Each method is used for a different purpose, with the use of each depending on varying factors.
In this post, We explain the difference between bagging, boosting. we explain their purposes, processes, as well as their advantages and disadvantages.
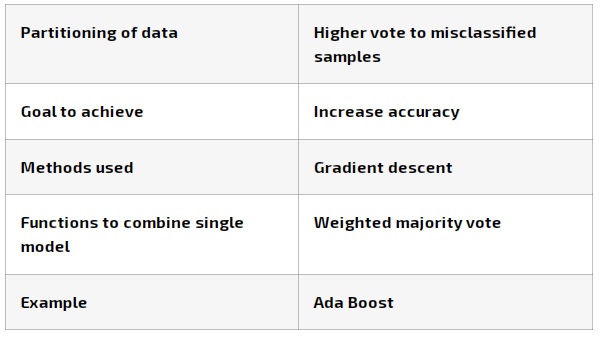
Boosting is one of the most successful ensemble learning methods, which combines a large number of weak learners in an additive form to enhance prediction performance.
Boosting works on the principle of improving mistakes of the previous weak learner through the next learner. In boosting, weak learner is used which perform only slightly better than a random chance.
Boosting focuses on sequentially adding up weak learners and filtering out the observations that a learner gets correct at every step.
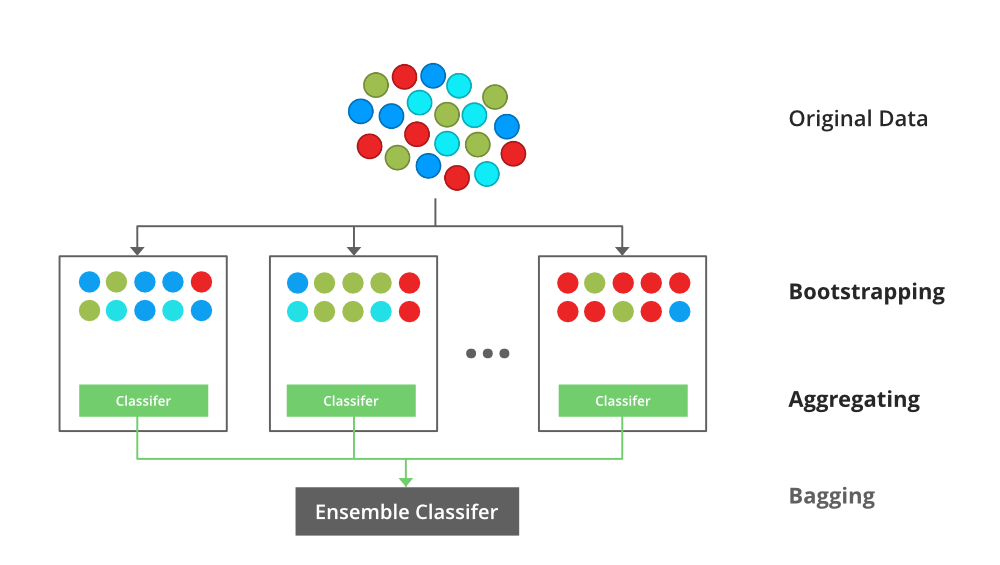
Bagging or Bootstrap Aggregating is an ensemble learning technique that trains several weak models independently on equal sized subsets of dataset obtained through bootstrapping.
Then the predictions of all weak models are combined to obtain a final prediction. Bagging is mostly applied to tree-based algorithms such as decision tree and random forest.
What is Ensemble Learning?
Ensemble learning is a machine learning method that consists of combining multiple models.
By leveraging the diverse strengths of different models, ensemble learning aims to mitigate errors, enhance performance, and increase the overall predictions robustness, leading to improved results across various tasks in machine learning.
The individual models are known as weak learners because they either have a high bias or high variance. Because they either have high bias or variance, weak learners cannot learn efficiently. That is why individual models tend to perform poorly.
To mitigate this problem, we combine multiple models to get one better performance.
Bagging
Bootstrap Aggregating, also known as bagging, is a machine learning ensemble learning designed to improve the stability and accuracy of machine learning algorithms used in classification and regression.
Weak learners are homogenous, meaning they are of the same type. Bagging aims to produce a model with lower variance than the individual weak models.
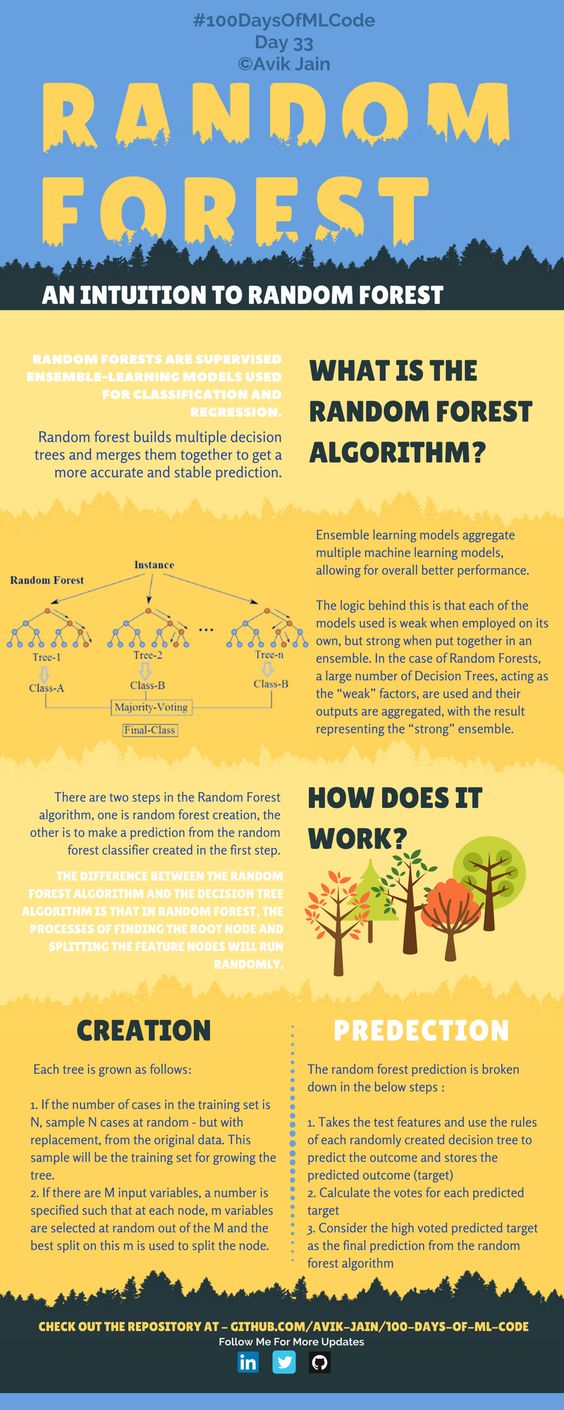
Random Forest Algorithm uses Bagging, where decision tree models with higher variance are present. It makes random feature selection to grow trees. Several random trees make a Random Forest.
- Bootstrapping
- Involves resampling subsets of dataset with replacement from an initial dataset. These subsets of data are called bootstrapped datasets or bootstraps. Each bootstrap dataset is used to train a weak learner. Resampled with replacement means a datapoint can be sampled multiple times.
- Aggregating
- The individual weak learners are trained independently from each other to make independent predictions. The results of the predictions are aggregated at the end to get the overall prediction using either max voting or averaging.
- Max Voting
- It is used for classification problems that consists of taking the mode of the predictions. It is called voting because like in election voting, the premise is that the majority rules.
- Averaging
- It is used for regression problems. It involves taking the average of the predictions. The resulting average is used as the overall prediction for the combined model.
Bagging Steps
- Suppose we have N samples and M features in training dataset. A sample from training dataset is taken randomly with replacement.
- A subset of M features are selected randomly and whichever feature gives the best split is used to split the node iteratively.
- The tree grows larger.
- Steps are repeated n times and prediction is given based on the aggregation of predictions from n number of trees.
Bagging Advantages
- Reduce overfit.
- Handles higher dimensionality data very well.
- Maintains accuracy for missing values.
Bagging Disadvantages
Since final prediction is based on the mode and mean predictions from subset trees, it won’t give precise values for the classification and regression model.
Boosting
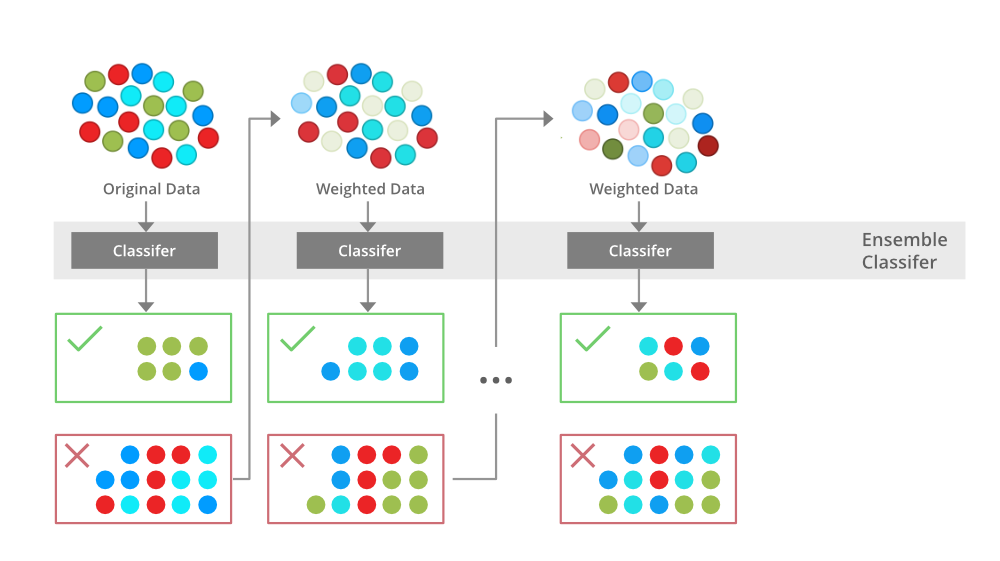
Boosting is another ensemble technique to make a collection of predictors. It involves sequentially training weak learners. Here, each learner improves the errors of previous learners in the sequence.
First a subset is taken from the initial dataset. This subset is used to train the first model, and the model makes prediction. The samples that are wrongly predicted are reused for training the next model.
In Boosting, the results are aggregated at each step using weighted averaging.
Weighted averaging involves giving all models different weights depending on their predictive power. In other words, it gives more weight to the model with highest predictive power.
Boosting aims to produce a model with a lower bias than of the individual models. Like bagging, the weak learners are homogeneous. Gradient Boosting is an expansion of the boosting.
Boosting Steps
- We sample n number of subsets from an initial training dataset.
- We train the first weak learner with the first subset.
- We test weak learner using the training data. As a result of the testing, some data points will be incorrectly predicted.
- Each datapoint with the wrong prediction is sent into the second subset, then this subset is updated.
- We train and test the second weak learner with updated subset.
- We continue with the following subset until the total number of subsets is reached.
- Now we have the total prediction. The overall prediction has already been aggregated at each step, so there is no need to calculate it.
Boosting Advantages
- Supports different loss function.
- Works well with interactions.
Boosting Disadvantages
- Prone to overfit.
- Requires tuning hyperparameters.
Bagging vs. Boosting
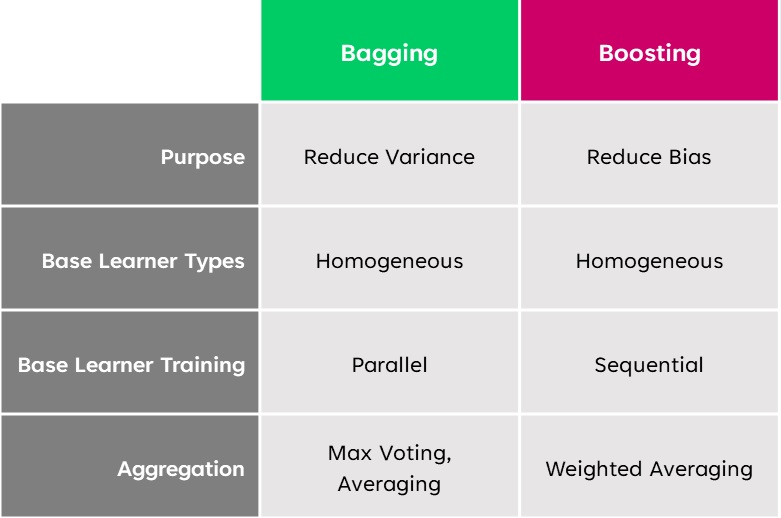
The main difference between bagging and boosting is the way in which they are trained.
In bagging, weak learners are trained in parallel, but in boosting, they learn sequentially.
It means, a series of models are constructed and with each new model iteration, the weights of the misclassified data in the previous model are increased. This redistribution of weights helps algorithm identify the parameters that it needs to focus on to improve its performance.
And also, we explain the similarities between bagging and boosting.
- Both are ensemble methods to get n learners from the same learner.
- Both generate several training datasets by random sampling.
- Both make the final decision by majority voting or averaging the N learners.
- Both provide higher stability by reducing variance.
Random Forest Infographic
Decision Tree Infographic

We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Adaptive Boosting Algorithm Explained
XGBoost Algorithm Explained


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained