Machine learning allows machines to perform data analysis and make predictions. However, if the machine learning model is not accurate, it can make predictions errors, and these prediction errors are usually known as Bias and Variance. In machine learning, these errors will always be present as there is always a slight difference between the model predictions and actual predictions. The main aim data science analysts is to reduce these errors in order to get more accurate results.
What is errors in Machine Learning?
In ML, an error is a measure of how accurately an algorithm can make predictions for the previously dataset. On the basis of these errors, the machine learning model is selected that can perform best on the particular dataset. There are mainly two types of errors in machine learning, which are:
- Reducible errors:
- These errors can be reduced to improve the model accuracy. Such errors can further be classified into bias and Variance.
- Irreducible errors:
- Irreducible Error cannot be reduced irrespective of the models. It is a measure of the amount of noise in our data due to unknown variables and cannot be removed.
What is Bias?
In machine learning, while training the model learns patterns in the dataset and applies them to test data for prediction. While making predictions, a difference occurs between prediction values made by the model and actual values, and this difference is known as bias errors. It can be defined as an inability of machine learning algorithms to capture the true relationship between the data points. Each algorithm begins with some amount of bias because bias occurs from assumptions in the model, which makes the target function simple to learn.
- High Bias
- High bias, also known as underfitting, means the machine learning model did not learn enough from the dataset and happens when a model is not complex enough.
- Low Bias
- A low bias model will make fewer assumptions about the form of the target function.
A linear algorithm has a high bias, as it makes them learn fast. Whereas a nonlinear algorithm often has low bias. Machine learning algorithms with low bias are Decision Trees, k-Nearest Neighbours and Support Vector Machines. At the same time, an algorithm with high bias is Linear Regression and Logistic Regression.
What are Underfitting and Overfitting?
- Overfitting
- It is a Low Bias and High Variance model. Decision tree algorithm is prone to overfitting.
- Underfitting
- It is a High Bias and Low Variance model. Linear and Logistic regressions algorithm are prone to Underfitting.
What is Variance?
Variance is the amount that the prediction will change if different training data sets were used. It measures how scattered are the predicted values from the correct value due to different training data sets. It is also known as Variance Error or Error due to Variance.
Variance tells that how much a random variable is different from its expected value.
- Low variance
- means there is a small variation in the prediction of the target function with changes in the training data set.
- High variance
- means a large variation in the prediction of the target function with changes in the training dataset.
A model with high variance learns a lot and perform well with the training dataset, and does not well with the unseen dataset.
High variance leads to overfitting of the model and increase model complexities.
What are the problems associated with different Bias Variance combinations?
- High Bias and Low Variance (Underfitting)
- Predictions are consistent, but inaccurate on average. This can happen when the model uses very few parameters.
- High Bias and High Variance
- Predictions are inconsistent and inaccurate on average.
- Low Bias and Low Variance
- It is an ideal model.
- Low Bias and High Variance (Overfitting)
- Predictions are inconsistent and accurate on average. This can happen when the model uses a large number of parameters.
How to reduce High Variance?
- Reduce the input features or number of parameters as a model is overfitted.
- Do not use a much complex model.
- Increase the training data and the Regularization term.
Identify High variance or High Bias
High variance can be identified if the model has low training error and high test error.
High Bias can be identified if the model has high training error and the test error is similar to training error.
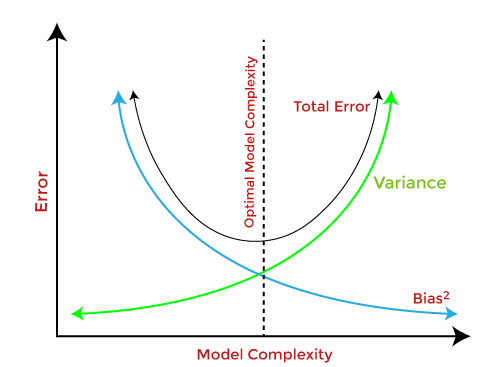
Bias-Variance Trade-Off
While building the machine learning model, If the model is very simple with fewer parameters, it may have low variance and high bias. Whereas, if the model has a large number of parameters, it will have high variance and low bias. So, it is required to make a balance between bias and variance errors, and this balance between the bias error and variance error is known as the Bias-Variance trade-off.
To increase the accuracy of Prediction, we need to have Low Variance and Low Bias model. But, we cannot achieve this due to the following:
1-Decreasing the Variance will increase the Bias.
2-Decreasing the Bias will increase the Variance.
We need to have optimal model complexity between Bias and Variance which would never Underfit or Overfit.

Bias-Variance trade-off is a central issue in supervised learning and it is about finding the sweet spot to make a balance between bias and variance errors.
Recommended for you:
Machine Learning Optimization Techniques

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained