




Machine learning has more to offer than a set of techniques that can be applied to data. Theoretical concepts and principles in machine learning can provide broader insights to research and development.
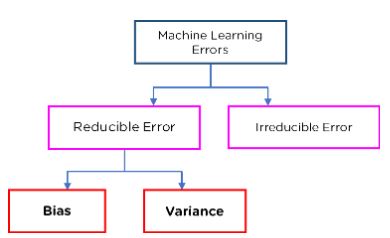
Bias and Variance are the core parameters to tune while training a Machine Learning model. When we discuss models’ prediction, prediction errors can be decomposed into two subcomponents: error due to bias, and error due to variance.
What is Bias?
Bias is the difference between actual values and predicted values. Bias is the simple assumptions that our model makes about our data to be able to predict new data.
When Bias is high, assumptions made by our model are too basic, the model can’t capture the important features of our data. This means, where the model cannot find patterns in our training set and hence fails for unseen data, is called Underfitting.
Errors due to Bias
An error due to Bias is distance between the prediction values and the true values. In this error type, the model pays little attention to training data and oversimplifies the model, therefore doesn’t learn the patterns. The model learns the wrong relations by not taking in account all the features.
Bias describes how well a model matches the training dataset.
What is Variance?
We can define variance as the model’s sensitivity to fluctuations in the dataset. In other words, variance is opposite of Bias.
During training, it allows our model to see data a certain number of times to find patterns in it. If it does not work on the data for long enough, it will not find patterns and bias occurs.
On the other hand, if our model is allowed to view the data too many times, it will learn very well for only that data. It will capture most patterns in the data, but it will also learn from the unnecessary data or noise.
Hence, the model performs really well on testing data and get high accuracy but will fail to perform on unseen data. New data may not have the exact same features and the model won’t be able to predict it well. This is called Overfitting.
Errors due to Variance
Variability of model prediction for a given data point tells us the spread of our data. In this error type, the model pays a lot of attention in training data, to memorize it instead of learning. A model with a high error of variance is not flexible to generalize on the unseen-data.
Variance describes how much a model changes when you train it using different portions of your dataset.
Bias-Variance Tradeoff
The bias-variance tradeoff refers to the fact that when trying to make a statistical prediction, there is a tradeoff between the accuracy of the prediction and its precision, or equivalently between its bias and variance.
For any ML model, we have to find the perfect balance between Bias and Variance. This just ensures that we capture the essential patterns in our model while ignoring the noise present it in. This is called Bias-Variance Tradeoff. It helps optimize the model and keeps error as low as possible.
Actions that you take to decrease bias (leading to a better fit to the training dataset) will simultaneously increase the variance in the model (leading to higher risk of poor predictions).
The inverse is also; actions you take to reduce variance will inherently increase bias.
An optimized machine learning model will be sensitive to the patterns in our data, and at the same time will be able to generalize to new data.
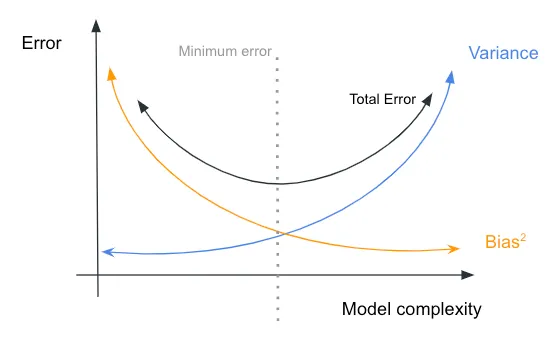
Graph shows how the complexity of the model is related to the values of bias and variance. As model’s complexity increases, the bias decreases (the model fits the training dataset better) but the variance increases (the model becomes more sensitive to the training dataset).
Optimal tradeoff occurs at the point where the error is minimized, which in this case is at a moderate level of complexity.
Fixing Bias-Variance Problems
Fixing high Bias
- Adding more features will help improve the data to fit better.
- Add more polynomial features to improve the complexity of the model.
- Decrease the regularization term.
- High-Bias machine learning algorithms:
- Linear Regression
- Logistic Regression
- Linear Discriminant Analysis
Fixing High Variance
- Use only features with more importance to reduce overfitting the data.
- Getting more training data will help, because the high variance model will not be working for an independent dataset if you have very data.
- High-variance ML algorithms:
- Decision Trees
- K-Nearest Neighbor
- Support Vector Machines
Bias-Variance Tradeoff Infographic

I hope I’ve given you good understanding of bias-variance tradeoff.
I am always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Bias and Variance in Machine Learning
Overfitting and Underfitting

What’s up, of course this paragraph is in fact nice and I have learned lot of things
from it concerning blogging. thanks.