Category: Preprocessing

Feature Generation in Machine Learning
In machine learning, collecting and processing data can be expensive and time-consuming process. Therefore, choosing informative, discriminating features is a crucial step for algorithms in pattern recognition.Furthermore, it has become common to […]
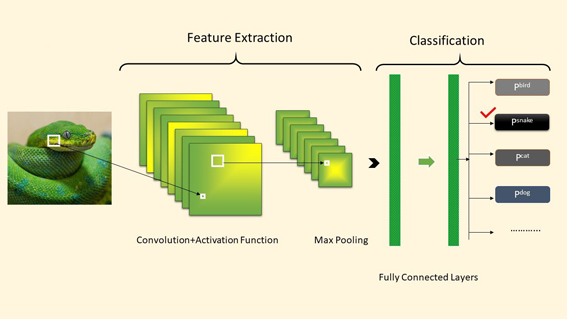
Feature Extraction in Machine Learning
In machine learning projects, we may assume that a more significant number of features means more details on the target variable. But datasets may consist of relevant, irrelevant features.While building a machine […]
Feature Selection in Machine Learning
Data scientists spend a huge amount of time doing data preprocessing like feature engineering. Feature selection is also a very common step in many machine learning projects.In this post, we discuss the […]

Feature Encoding in Machine Learning
The real-world data needs processing before feeding it to a machine learning model. We know that around 80% of a data scientist’s time goes into data preprocessing and 20% of the time […]

Anomaly Detection in Machine Learning
Anomaly detection is the process for find the outliers or noises of a dataset. These anomalies might point to unusual network traffic, uncover a sensor on the fritz, or simply identify data […]
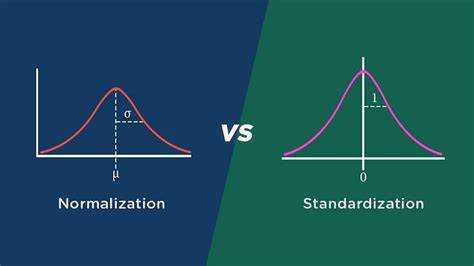
Normalization vs Standardization in ML
Feature engineering is a critical step in building accurate and effective machine learning models. One key aspect of feature engineering is normalization, or standardization, which involves transforming the data to make it […]

Anova Feature Selection
Feature selection is also called variable selection or attribute selection is the process of selecting a subset of relevant features for use in model construction.Feature selection is different from dimensionality reduction. Both […]

Feature Engineering in Machine Learning
All machine learning algorithms use data as the input to calibrate and generate output. Data is initially in its crudest form, requiring enhancement before feeding it to the algorithm. This input data […]

Data Cleaning in Machine Learning
The big problem data scientist face today is dirty data. Today data scientists often end up spending times cleaning and unifying dirty data before they can apply any analytics or machine learning. […]
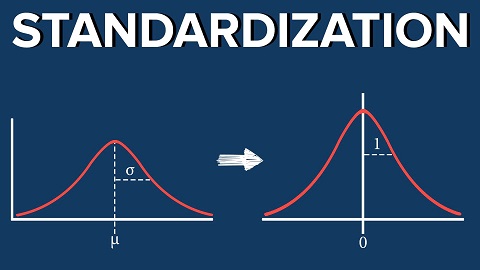
Data Standardization in Machine Learning
What does Feature Scaling mean? Increasing accuracy in machine learning models is often obtained through the first steps of data transformations.In practice, we often encounter different types of variables in the same […]
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained