
Clustering is a common unsupervised machine learning technique, in which the dataset has to be automatically partitioned into “clusters”, such that objects within the same cluster are more similar, while objects in different clusters are more different. The main benefit of using clustering technique is that interesting structures or clusters can be discovered directly from the dataset without utilizing any background knowledge.
Over many years of research, hundreds of clustering algorithms and evaluation metrics have been proposed, each with their merits and drawbacks. Nevertheless, a few seminal methods such as hierarchical clustering, k-means, PAM, and DBSCAN have widespread use.
What is CLARANS Algorithm?
Spatial data mining is the discovery of interesting relationships and characteristics that may exist implicitly in spatial datasets. Some clustering algorithms used in statistics are reported to be inefficient from the computational complexity point of view. As per the efficiency concern, a new algorithm called CLARANS was developed for clustering analysis.
CLARANS stands for ‘Clustering large Application Based on Randomized Search’. It is a partitioning method for clustering of large datasets. CLARANS aims to identify spatial structures that may be present in dataset. CLARANS is very efficient and effective and can handle not only points objects, but also polygon objects efficiently.
CLARANS uses a randomized search instead of considering all possible swaps. For this, it chooses a random pair of a non-medoid object and a medoid, computes whether this improves the current loss, and then greedily performs this swap. Adapting the idea from random exploration approach, we pick only the non-medoid object at random, but consider all medoids for swapping at a similar cost to looking at a single medoid.
This means we can either explore n times as many edges of the graph, or we can reduce the number of samples to draw by a factor of n. In our experiments we opted for the second choice, to make the results comparable to the original CLARANS in the number of edges considered; but as the edges chosen to involve the same non-medoids, we expect a slight loss in quality that should be easily countered by increasing the subsampling rate of non-medoids. By varying the subsampling rate parameter, the user can easily control the tradeoff between computation time and exploration.
How does CLARANS Algorithm work?
CLARANS algorithm search only the subset of the dataset and it does not constraint itself to some sample at any given time. CLARANS draws a sample with some randomness in every phase of the search.
The clustering phase can be presented as searching a graph where each node is a possible solution, i.e, a set of n medoids. The clustering obtained after replacing a single medoid is called the neighbor of the current clustering. The following steps to be performed:
- Take two input parameters, num_local and max_neighbour.
- num_local means number local minima obtained, and max_neighbour means maximum number of neighbors examined.
- Select N object on random basis from the database object D.
- Divide Si and non-selected Si, by Marking these N object as selected Si and rest of all other as non-selected Si.
- Calculate the cost T for selected Si.
- We will get two values of T, Positive and Negative. If T is negative update medoid set. Otherwise selected medoid chosen as local optimum.
- Restart the selection of another set of medoid and find local optimum again.
- CLARANS stops until returns the best.
Advantages of CLARANS
- It is easy to handle outliers.
- CLARANS result is more the effective as compare PAM and CLARA.
Disadvantages of CLARANS
- It does not guarantee to give search to a localized area.
- It uses randomize samples for neighbors.
CLARANS vs K-Means
Sales dataset from UCI machine repository has used for comparison of K-Mean and CLARANS. Research team have executed K-Means and CLARANS algorithm for the above mentioned dataset. After execution, overlapping of clusters using CLARANS is better as compared to K-Means as shown below images.
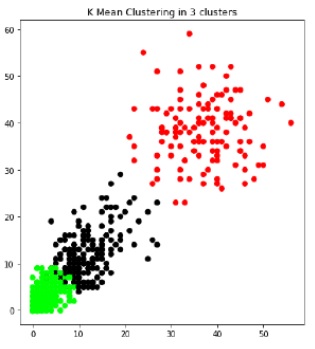
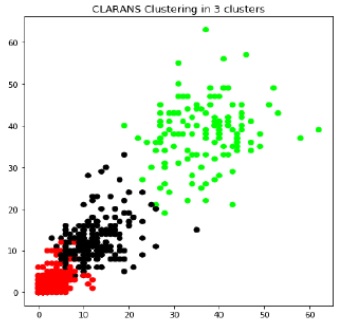
The comparison results show that time taken in cluster formation and overlapping of cluster is better in CLARANS rather than K-Means. Also, the result of dataset shows that CLARANS is better in all aspects such as less execution time, less sensitive noise.
Recommended to you:


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained