
Clustering
Cluster analysis, or clustering, is an unsupervised machine learning task. It involves automatically discovering natural grouping in data. Unlike supervised learning, clustering algorithms only interpret the input data and find natural groups or clusters in feature space.
Clustering can be helpful as a data analysis activity in order to learn more about the problem domain, so-called pattern discovery or knowledge discovery.
For example:
- The phylogenetic tree could be considered the result of a manual clustering analysis.
- Separating normal data from outliers or anomalies may be considered a clustering problem.
- Separating clusters based on their natural behavior is a clustering problem, referred to as market segmentation.
Evaluation of identified clusters is subjective and may require a domain expert, although many clustering-specific quantitative measures do exist. Typically, clustering algorithms are compared academically on synthetic datasets with pre-defined clusters, which an algorithm is expected to discover.
Clustering is an unsupervised learning technique, so it is hard to evaluate the quality of the output of any given method.
A cluster is often an area of density in the feature space where examples from the domain (observations or rows of data) are closer to the cluster than other clusters. The cluster may have a center (the centroid) that is a sample or a point feature space and may have a boundary or extent.
Density-Based Clustering Algorithm
Density based clustering facilitates searches for signals of unknown shape. These algorithm looks for neighbors of those points that have at least a given number of neighboring points within a given distance on the time-frequency plane, and forms clusters of data-points that can be related through their common neighbors.
Graphical Abstract of Density-Based Clustering
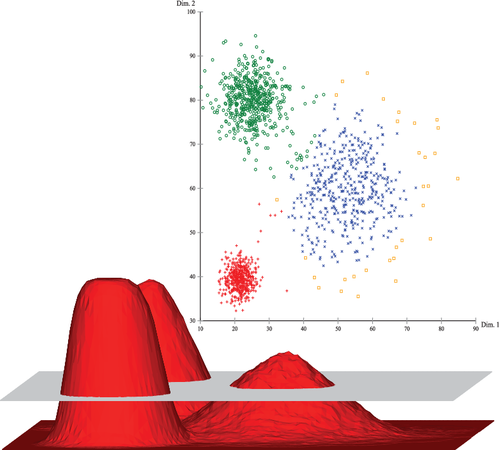
The Density-based Clustering algorithms work by detecting regions in which factors are focused and in which they’re separated via means of regions that might be empty or sparse. Points that aren’t a part of a cluster are categorized as noise.
These algorithms are taken into consideration unsupervised due to the fact they do not require any education on what it means to be a cluster.
Cluster Analysis is a critical trouble in records analysis. Data scientists use clustering to perceive malfunctioning servers, organization genes with comparable expression patterns, and carry out diverse different applications.
There are many households of clustering algorithms, and you’ll be acquainted with the most famous of them.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN is a popular unsupervised learning method utilized in machine learning model building, and it is used to separate clusters of high density from clusters of low density. Given that DBSCAN is a density based clustering algorithm, it does a great job of seeking areas in the data that have a high density of observations, versus areas of the data that are not very dense with observations. DBSCAN can sort data into clusters of varying shapes as well.
How does the DBSCAN work?
Algorithms start by picking a point (x) from your dataset at random and assign it to a cluster 1. Then it counts how many points are located within the “epsilon” distance from x. If this quantity is greater than or equal to minPoints(m), then considers it as core point, then it will pull out all these neighbours to the same cluster 1. It will then examine each member of cluster 1 and find their respective neighbours. If some member of cluster 1 has m or more neighbours, it will expand cluster 1 by putting those neighbours to the cluster. It will continue expanding cluster 1 until there are no more examples to put in it.
In the other case, it will pick another point from the dataset not belonging to any cluster and put it to cluster 2. It will continue like this until all examples either belong to some cluster or are marked as outlier.
We can observe three different instances(points) as a part of DBSCAN clustering.
- Core Point: Data point that has at least minPoints within epsilon distance.
- Border Point: Data point that has at least one core point within epsilon distance and lower than minPoints within epsilon distance from it.
- Noise Point: Data point that has no core points within epsilon distance.
OPTICS (Ordering Points to Identify the Clustering Structure)
OPTICS is an algorithm for density based clustering. It’s quite an old algorithm already. Nevertheless, it is still a good algorithm today. It is similar to the DBSCAN algorithm for clustering, an extension even, and hence borrows some of its components as well as its algorithmic components. The outcome of this algorithm is a dendrogram (which shows the tree like structure of the data by means of the reachability distance).
OPTICS Components
- Epsilon parameter:
- The first parameter is the epsilon. It is a distance parameter in the sense that for any point, the epsilon defines a distance around the point.
- MinPts parameter:
- Another parameter is the minimum amount of points. It is used together with epsilon because it illustrates how many points must be within the distance of a point (including the point) in order to form a cluster.
- Core distance
- The core distance is undefined if the number of points in the neighborhood is lower than the minimum number of points required. This makes sense: if the point is no core point, it does not have a core distance.
- Reachability distance
- While the core distance expresses the minimum distance to keep a point a core point, the reachability distance expresses the distance which is reachable from a core point.
OPTICS can be used for clustering when the density of your clusters is different. This is something that DBSCAN cannot do so well.
Similar to DBSCAN, OPTICS also works with epsilon and a minimum number of points, which specifies a distance around a point and a minimum number of points (including the itself point) to be within this distance in order to classify the point as a core point. Core points represent dense points, and using the core distance and reachability distance, OPTICS is capable of grouping samples together.
OPTICS works by ordering based on reachability distance while expanding the clusters at the same time. The output of the OPTICS algorithm is therefore an ordered list of reachability distances, which by means of thresholds or different techniques we can split into clusters. This way, we’re able of generating clusters for groups of data that have varying densities.
Recommended for you:

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained