Machine Learning is the modern technology to allow applications to model and predict the outcomes of a problem. It uses advanced artificial intelligence algorithms, techniques and works on their bases to create and analyze situations to predict its consequence.
There are different approaches to machine learning, depending on the dataset. You can go with supervised learning, semi-supervised learning, or unsupervised learning.
In supervised learning you have labeled data, that you know for sure are the correct values for your inputs. With semi-supervised learning, you have a large dataset where just some of the data is labeled.
Unsupervised learning means you have a dataset that is completely unlabeled. You don’t know if there are any hidden patterns in the dataset, so you leave it to the algorithm to find any patterns can. That’s where clustering algorithms come in.
What is Clustering in Machine Learning?
Clustering is a type of unsupervised machine learning method that involves the grouping of datapoints. Provided a set of datapoints, to classify each datapoint into a specific group we can use clustering algorithms. Theoretically, datapoints that are in the same group need to have very similar properties or features, while datapoints in different groups must have highly dissimilar properties or features. Clustering is a common method for statistical data analysis used in several fields.
It is a collection of objects based on similarity and dissimilarity between them. In the past decade, Data had been increasing rapidly, when it comes to different forms of images, texts, files, videos, audio, etc. Clustering in machine learning uses the data to solve the questions.
In data science, clustering analysis can be used to gain valuable insights from our data by seeing in which group the datapoint falls into when we apply a clustering algorithm.
Working of Clustering in Machine Learning
In clustering, we group an unlabeled dataset. When we initially group unlabeled data, we have to find a similar group. When we make a group, we have to recognize the features of datasets i.e. data which is similar. In case we make a group by one or more features, it’s easy to evaluate similarity. There are no criteria for a good cluster, it totally depends on the users i.e. what parameters they may use that satisfy their needs.
Types of clustering algorithms
There are different types of clustering algorithms to handle unique data.
Density-based
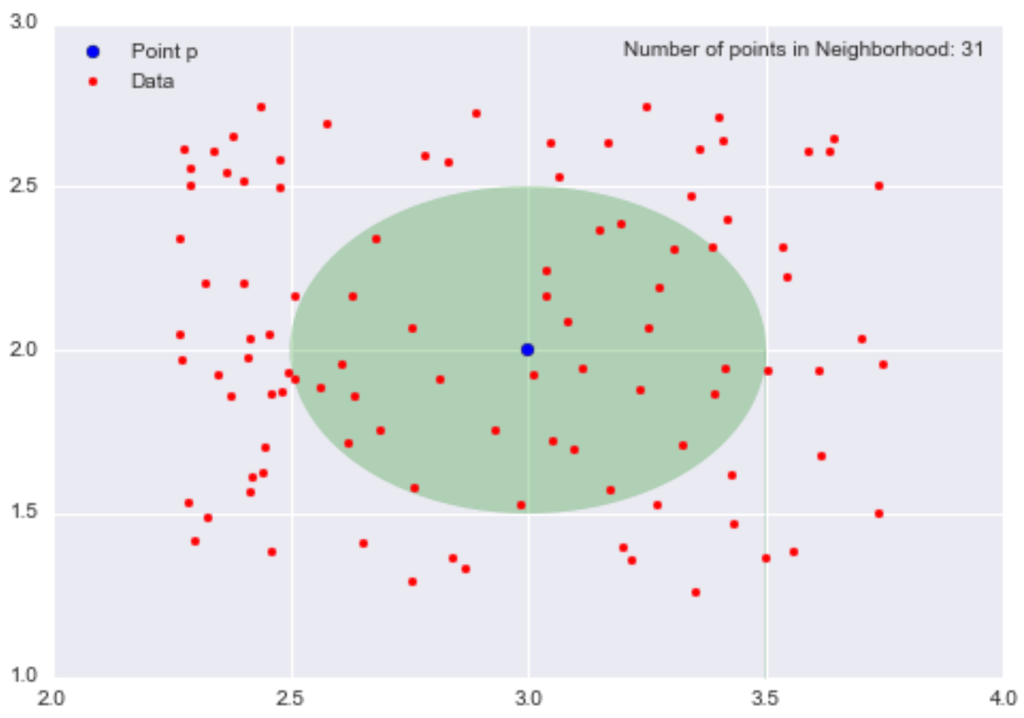
In density-based clustering, data is grouped by areas of high concentrations of datapoints surrounded by areas of low concentrations of datapoints. The algorithm finds the places that are dense with datapoints and calls those clusters.
Density-based clustering algorithms don’t try to assign outliers to clusters, so they get ignored.
Distribution-based
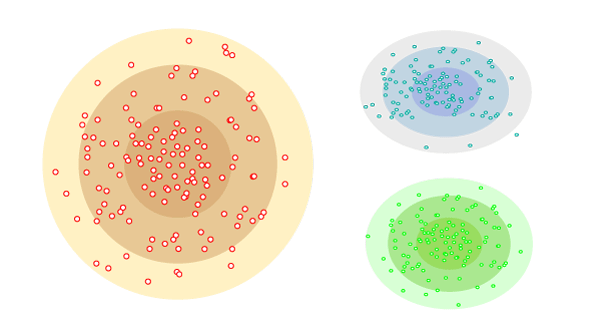
With a distribution-based clustering approach, the data is divided based on the probability of how a dataset belongs to a particular distribution. The grouping is done by assuming some distributions commonly Gaussian Distribution.
If you aren’t sure of how the distribution in your data might be, you should consider a different type of algorithm.
In simple words: there is a center point, and as the distance of a datapoint from the center increases, the probability of it being a part of that cluster decreases.
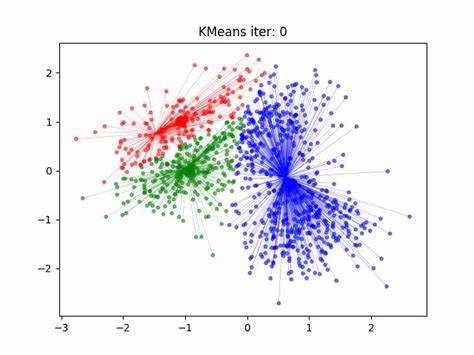
Centroid-based
Centroid-based is the most commonly used type of clustering. Centroid-based algorithm separate datapoints based on multiple centroids in the data. Each datapoint is assigned to a cluster based on its squared distance from the centroid.
In other words, this type of clustering divides the data into non-hierarchical groups. It is also known as the Partitioning Clustering method.
Centroid-based clustering is little sensitive to the initial parameters you give it, but it’s fast and efficient.
The most common example of partitioning clustering is the K-Means Clustering algorithm.
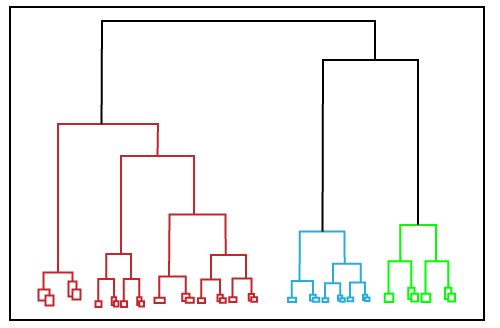
Hierarchical-based
Hierarchical-based clustering is typically used on hierarchical data, like you would get from a taxonomy. It builds a tree of clusters, so everything is organized from the top-down, and is perfect for specific kinds of datasets.
Hierarchical-based clustering can be used as an alternative for the partitioned clustering as there is no requirement of prespecifying the number of clusters to be created. In this technique, the dataset is divided into clusters to create a tree like structure or dendrogram. The observations can be selected by cutting the tree at the correct level. The most common example of this method is the Agglomerative Hierarchical algorithm.
Methods of Clustering in Machine Learning
- Hard Clustering
- In hard clustering, each dataset must belong to a cluster completely. If the new datapoints are not similar up to a certain condition, the datapoints are completely removed from the cluster.
- Soft Clustering
- In soft clustering, a probability of a dataset belonging to a cluster gets calculated, and then that dataset gets placed in that cluster. In this type of clustering, a unique data entity is found in multiple clusters based on their like-hood.
Why is Clustering in Machine Learning Important?
Clustering and classification allow you to take a sweeping glance at your data. And then form some logical structures based on what you find there before going deeper into the analysis.
Clustering is a significant component of machine learning, and its importance is highly significant in providing better machine learning techniques.
Recommended to you:

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained