
The process of determining whether the mathematical results calculating relationships between variables are acceptable as descriptions of the data is known as Validation. In this process, we measure the Training Error by calculating the difference between predicted response and original response. But this metric cannot be trusted because it works well only with the training data. It’s possible that the model is Underfitting or Overfitting the data.
We cannot just go with the evaluation metrics in order to select our best performing model. It’s critical how well the result of the statistical analysis will generalize to independent datasets. Cross-validation is one of the simplest and commonly used techniques that can validate models based on these criteria.
What is Cross-Validation?
Before introducing cross-validation, let’s review some basic concepts.
Generalization
In supervised machine learning, after building the model, we may measure the model’s performance on the same training data, but it’s usually too optimistic. The model might fail to provide reliable predictions on new data.
Overfitting
Overfitting is a concept in data science, which occurs when a statistical model fits exactly against its training data. When this happens, the algorithm unfortunately cannot perform accurately against unseen data. So we need the model to generalize its performance well over new datasets. We need to know whether the same model works on data outside of the training set.
Training data set
A training data set is a data set of examples used during the learning process. A supervised learning algorithm looks at the training data set to determine, or learn, the optimal combinations of variables that will generate a good predictive model.
Validation data set
A validation data set is a data set of examples used to tune the hyperparameters of a classifier. It is sometimes also called the development set. An example of a hyperparameter for artificial neural networks includes the number of hidden units in each layer.
Test data set
A test data set is a data set that is independent of the training data set, but that follows the same probability distribution as the training data set. If a model fit to the training data set also fits the test data set well, minimal overfitting has taken place.
Cross-Validation
Cross-Validation (CV) is one of the key topics around testing your learning models. It is a technique for evaluating a machine learning model and testing its performance. It helps to compare and select an appropriate model for the specific predictive modeling problem.
Cross-Validation is easy to understand, easy to implement, and it tends to have a lower bias than other methods used to count the model’s efficiency scores. All this makes cross-validation a powerful tool for selecting the best model for the specific task.
There are a lot of different techniques that may be used to cross-validate a model. Still, all of them have a similar algorithm:
- Divide the dataset into training and testing data sets
- Train the model on the training data set
- Validate the model on the test data set
- Repeat 1-3 steps a couple of times.
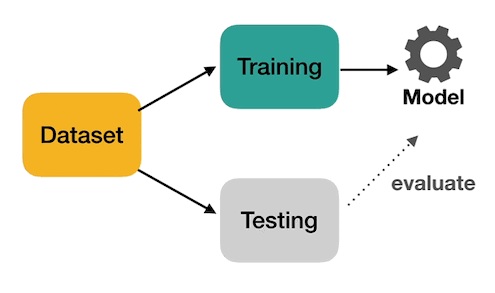
How does Cross-Validation work?
Cross-Validation has two main steps: splitting the data into subsets also called folds and rotating the training and validation among them. The splitting technique commonly has the following properties:
- Each fold has approximately the same size.
- Data can be randomly selected in each fold or stratified.
- All folds are used to train the model except one, which is used for validation. That validation fold should be rotated until all folds have become a validation fold once.
- Each example is recommended to be contained in one fold.
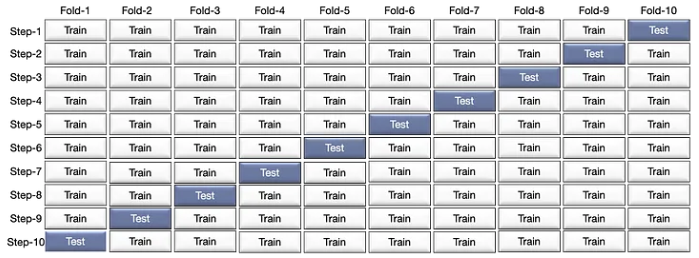
K-fold is just describing how many folds you want to split your dataset into. Many libraries use k=10 as a default value representing 90% going to training and 10% going to the validation set.
Types of Cross-validation
Cross-validation methods can be classified into two categories: exhaustive and non-exhaustive methods.
Exhaustive methods strive to test on all possible ways to divide the original data sample into a training and a testing set. On the other hand, non-exhaustive methods don’t compute all ways of partitioning the original data into training and evaluation sets.
Let’s see the cross-validation methods in this post.
Holdout method
The holdout method is one of the basic cross-validation approaches in which the original dataset is divided into training and testing data sets. It’s a non-exhaustive method, and as expected, the model is trained on the training dataset and evaluated on the testing dataset.
Generally, the size of the training dataset is twice more than the test dataset, meaning the original dataset is split in the ratio of 80:20 or 75:25. Also, the data is randomly shuffled before dividing it into training and validation sets.
However, there are some downsides to this cross-validation method. Since the model is trained on a different combination of data points, it can exhibit varying results every time it’s trained. Additionally, we can never be entirely sure that the training dataset chosen represents the entire dataset.
If the original data sample isn’t too large, there’s also a chance that the test data may contain some crucial information, which the model will fail to recognize as it’s not included in the training data.
K-fold Cross-validation
The K-fold method is a non-exhaustive cross-validation method, and as the name suggests, the dataset is divided into k number of splits. The K-fold method is an improved version of the holdout method, and brings more consistency to the model’s score as it doesn’t depend on how we choose the training and testing dataset.
The k-fold cross-validation procedure starts with randomly splitting the original dataset into k number of folds or subsets. In each iteration, the model is trained on the k-1 subsets of the entire dataset. After that, the model is tested on the kth subset to check its performance.
For example, if the value of k is equal to two, there will be two subsets of equal sizes. In the first iteration, the model is trained on one subsample and validated on the other. In the second iteration, the model is trained on the subset that was used to validate in the previous iteration and tested on the other subset.
This process is repeated until all of the k-folds have served as the evaluation set. The results of each iteration are averaged, and it’s called the cross-validation accuracy. Cross-validation accuracy is used as a performance metric to compare the efficiency of different models.
The k-fold cross-validation technique generally produces less biased models as every data point from the original dataset will appear in both the training and testing set. This method is optimal if you have a limited amount of data.
However, as expected, this process might be time-consuming because the algorithm has to rerun k times from scratch.
The algorithm of the K-Fold:
- Pick a number of k. Usually, k is 10 but you can choose any number which is less than the dataset’s length.
- Split the dataset into k equal.
- Choose k–1 folds as the training data set. The remaining fold will be the test dataset.
- Train the model on the training data set. On each iteration of cross-validation, you must train a new model independently of the model trained on the previous iteration.
- Validate on the test data set.
- Save the result of the validation data set.
Repeat steps 3–6 for k times. Each time use the remaining fold as the test set. In the end, you should have validated the model on every fold that you have. to get the final score average the results that you got on step 6.
Leave-one-out Cross-validation
Leave-one-out Cross-validation is the an exhaustive holdout splitting approach that k-fold enhances. It has one additional step of building k models tested with each example. This approach is quite expensive and requires each holdout example to be tested using a model. It also might increase the overall error rate and becomes computationally costly if the dataset size is large. Usually, it is recommended when the dataset size is small.
The algorithm of Leave-one-out:
- Choose one sample from the data set which will be the test data set.
- The remaining n–1 samples will be the training data set.
- Train the model on the training set. On each iteration, a new model must be trained.
- Validate on the test data set.
- Save the result of the validation data set.
Repeat steps 1–5 for n times as for n samples we have n different training and test data sets. To get the final score average the results that you got on step 5.
Stratified K-fold Cross-validation
Since we’re randomly shuffling data and splitting it into folds in k-fold cross-validation, there’s a chance that we end up with imbalanced subsets. This can cause the training to be biased, which results in an inaccurate model. To avoid such situations, the folds are stratified using a process called stratification. In stratification, the data is rearranged to ensure that each subset is a good representation of the entire dataset.
In the example of binary classification, this would mean it’s better to divide the original sample so that half of the data points in a fold are from class A and the rest from class B.
It works as follows. IT splits the dataset on k folds such that each fold contains approximately the same percentage of samples of each target class as the complete set. In the case of regression, Stratified k-Fold makes sure that the mean target value is approximately equal in all the folds. The algorithm of Stratified k-Fold:
- Pick a number of K.
- Split the dataset into k folds. Each fold must contain approximately the same percentage of samples of each target class as the complete data set.
- Choose k–1 folds which will be the training data set. The remaining fold will be the test data set.
- Train the model on the training data set. On each iteration a new model must be trained.
- Validate on the test data set.
- Save the result of the validation data set.
Repeat steps 3–6 for k times. Each time use the remaining fold as the test data set. In the end, you should have validated the model on every fold that you have. to get the final score average the results that you got on step 6.
Repeated K-Fold Cross-validation
Repeated k-Fold cross-validation is probably the most robust of all CV techniques. It is a variation of k-Fold. but in this case ‘k’ is not the number of folds. It is the number of times we will train the model. The main idea is that on every iteration we will randomly select samples all over the data set as our test data set. For example, if we decide that 30% of the data set will be our test data set, 30% of samples will be randomly selected and the rest 80% will become the training data set.
Advantages of Repeated K-Fold
- The proportion of train/test split is not dependent on the number of iterations.
- We can even set unique proportions for every iteration.
- Random selection of samples from the dataset makes Repeated k-Fold even more robust to selection bias.
Disadvantages of Repeated K-Fold
- Repeated k-Fold is based on randomization which means that some samples may never be selected to be in the test set at all.
- Some samples might be selected multiple times. Thus making it a bad choice for imbalanced datasets.
The algorithm of Repeated k-Fold:
- Pick k number of times the model will be trained.
- Pick a number of samples which will be the test data set.
- Split the dataset.
- Train on the training data set. On each iteration of cross-validation, a new model must be trained.
- Validate on the test data set.
- Save the result of the validation.
Repeat steps 3-6 k times. to get the final score average the results that you got on step 6.
Why is Cross-validation important?
The purpose of Cross–validation is to test the ability of a machine learning model to predict new data. It is also used to flag problems like overfitting or selection bias and gives insights on how the model will generalize to an independent dataset. Also cross-validation is a procedure that is used to avoid overfitting and estimate the skill of the model on new data.
Recommended for you:
Bias and Variance in Machine Learning
Machine Learning Optimization Techniques

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained