
Performance of deep learning and machine learning models in particular, depends on the quality, quantity and relevancy of training data. However, insufficient data is a most common challenge in implementing machine learning. Because collecting such data can be costly and time-consuming in many cases.
Companies can leverage data augmentation to reduce reliance on training data collection.
What is Data Augmentation?
Data augmentation is the process of artificially generating new data from existing data, primarily to train machine learning models.
It is artificially increasing the training set by creating modified copies of a dataset using existing data. Artificially generating solutions are now being used for high quality and fast data augmentation in various businesses.
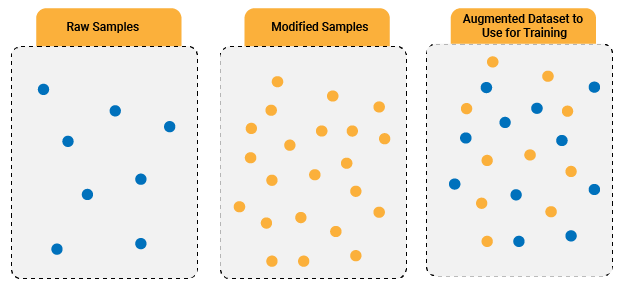
Why Data Augmentation is important.
Neural networks rely on large volumes of data to develop accurate predictions in various contexts.
It is useful to improve the performance of deep learning and machine learning models by forming new and different examples to train datasets. Here are some of the benefits of data augmentation.
- Prevent models from overfitting.
- Enhanced model performance.
- Reduce operational cost of labeling and cleansing the raw dataset.
- Reduced data dependency.
- Prevents data privacy problems.
- help to resolve imbalanced datasets in classification.
- increasing generalization of model.
How does Data Augmentation work?
Its techniques transform, or modifie existing data to create variations.
- First stage of data augmentation is to analyze existing dataset and understand its characteristics. Features like size, distribution, or text structure all give further context for augmentation.
- After you’ve selected the data augmentation technique, you begin applying different transformations. Datapoints in the dataset transform by using your selected augmentation technique, providing a range of new augmented samples.
- During the augmentation process, you maintain the same labeling rules for data consistency, ensuring that the synthetic data includes the same labels corresponding to the source dataset.
- Finally, you combine the augmented data with the original data to produce a larger training dataset for machine learning model.
To prevent biases from transferring into your new data, address any bias in the source dataset.
Data Augmentation Techniques
In this section, you will learn advanced techniques.
- Image augmentation
- Through position augmentation:
- This strategy crops, flips, or rotates an input image to create augmented images.
- Color augmentation:
- This strategy adjusts the elementary factors of a training image, randomly change RGB color channels, contrast, brightness or saturation.
- Delete some part of the initial image.
- Mixing multiple images.
- Through position augmentation:
- Adversarial training
- It is used to generate new datapoints. It does not require existing data to generate synthetic data.
- Neural style transfer
- A series of convolutional layers trained to deconstruct images and separate context and style.
- Audio augmentation
- Audio files are a common field where you can use data augmentation. Audio transformations typically include injecting random or Gaussian noise into some audio, changing the fixed rate, or altering the pitch.
- Text augmentation
- Randomly changing the position of a word or sentence, replacing words with synonyms, paraphrase the sentence using the same word.
- Insert or delete words at random.
Challenges
Companies need an evaluation system for checking the quality of augmented datasets. As use of augmentation techniques increases, assessment of quality of the output will be required. for example, if a real dataset contains bias, augmented data will contain bias too.
This domain needs to develop new research and studies to create synthetic data with advanced applications.
Data Augmentation Applications
It can apply to all machine learning applications where acquiring quality data is challenging.
Healthcare
Acquiring medical datasets is time consuming and expensive. Using geometric and other transformations can help you train robust and accurate machine learning models.
Self-Driving Cars
Companies use simulated environments to generate synthetic data using reinforcement learning. It can help you train and test machine learning applications where data security is an issue.
Automatic Speech Recognition
In speech recognition, augmented data improves the model performance even on low resource languages.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Feature Engineering in Machine Learning
Feature Selection in Machine Learning
Feature Extraction in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained