
The big problem data scientist face today is dirty data. Today data scientists often end up spending times cleaning and unifying dirty data before they can apply any analytics or machine learning. Data cleaning is essentially the task of removing errors and anomalies or replacing observed values with true values from data to get more value in analytics. There are the traditional types of data cleaning like imputing missing data and data transformations and there also more complex data unification problems like deduplication and repairing integrity constraint violations. All of these are inter-related, and it is important to understand what they are.
What Is Data Cleaning?
Data cleaning is the process of editing, correcting, and structuring data within a data set so that it’s generally uniform and prepared for analysis. This includes removing corrupt or irrelevant data and formatting it into a language that computers can understand for optimal analysis. There is an often repeated saying in data analysis: “garbage in, garbage out,” which means that, if you start with bad data , you’ll only get bad results.
Data cleaning is often a tedious process, but it’s absolutely essential to get top results and powerful insights from your data.
This is powerfully elucidated with the 1-10-100 principle: It costs $1 to prevent bad data, $10 to correct bad data, and $100 to fix a downstream problem created by bad data.
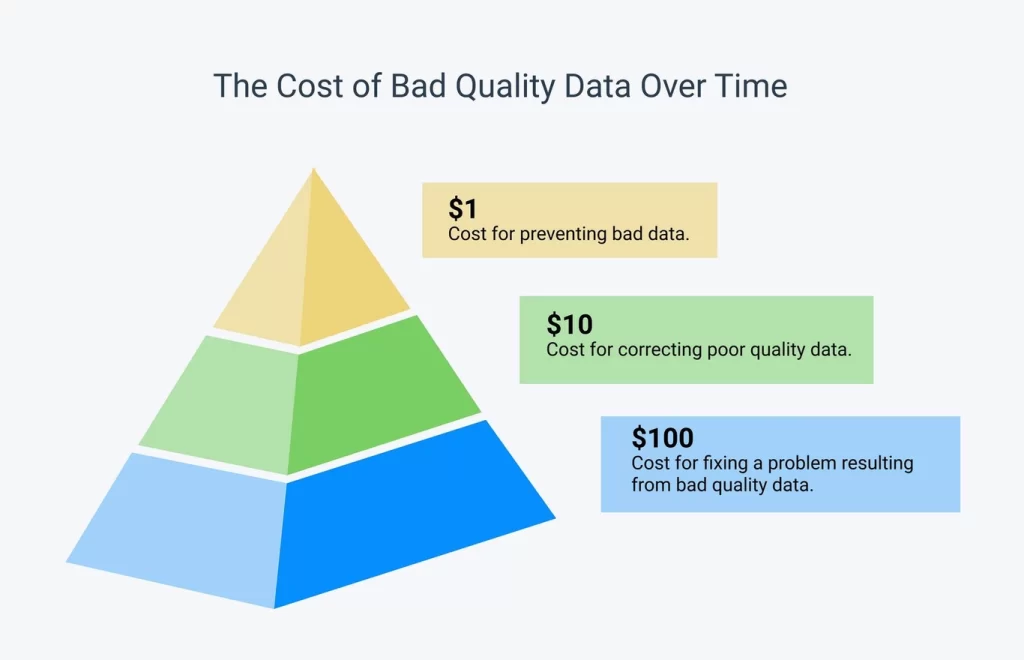
If you’re training your models with bad data, the end analysis results will not only be generally untrustworthy, but will often be completely harmful to your organization. So, it’s important that you perform proper data cleaning to ensure you get the best possible results.
In machine learning, data scientists agree that better data is even more important than the most powerful algorithms. This is because machine learning models only perform as well as the data they’re trained on.
Proper data cleaning will save time and money and make your organization more efficient, help you better target distinct markets and groups, and allow you to use the same data sets for multiple analyses and downstream functions.
Follow the data cleaning tips below to set yourself up for optimum analysis and results.
Understanding the Data
The first step in data cleaning for machine learning is to understand the data that we have. This involves exploring the data and identifying the following aspects:
- Data Types:
- Knowing the data types of the columns in the data set, such as numerical, categorical, or time series, is crucial as it helps determine the type of machine learning model that can be used and the preprocessing steps that need to be performed.
- Missing Data:
- Understanding the extent of missing data in the data set is important. Missing data can cause issues in the training of machine learning models, and hence, it’s important to decide how to handle it.
- Data Distribution:
- Understanding the distribution of the data in each column is important as it helps identify potential outliers and other data issues that need to be addressed.
- Data Quality:
- Evaluating the quality of the data is crucial in determining whether it’s suitable for machine learning models. This includes identifying any inconsistencies in the data, such as incorrect values, duplicates, or outliers.
Data Cleaning Steps
Data Cleaning is carried out through several steps.
Irrelevant data
First, you need to figure out what analyses you’ll be running and what are your downstream needs. What problems do you want to solve?
Take a good look at your data and get an idea of what is relevant and what you may not need. Filter out data or observations that aren’t relevant to your downstream needs.
For example, if you’re doing an analysis of SUV owners, but your data set contains data on Sedan owners, this information is irrelevant to your needs and would only skew your results. You should also consider removing things like hashtags, URLs, emojis, HTML tags, etc., unless they are necessarily a part of your analysis.
Deduplicated data
If you’re collecting data from multiple sources, use scraped data for analysis, or have received multiple survey or client responses, you will often end up with data duplicates.
Duplicate records slow down analysis and require more storage. Even more importantly, however, if you train a machine learning model on a dataset with duplicate results, the model will likely give more weight to the duplicates, depending on how many times they’ve been duplicated. So they need to be removed for well-balanced results.
Fix structural errors
Structural errors include things like misspellings, incongruent naming conventions, improper capitalization, incorrect word use, etc. These can affect analysis because, while they may be obvious to humans, most machine learning applications wouldn’t recognize the mistakes and your analyses would be skewed.
For example, if you’re running an analysis on different data sets – one with a ‘man’ column and another with a ‘male’ column, you would have to standardize the title. Similarly things like dates, addresses, phone numbers, etc. need to be standardized, so that computers can understand them.
Missing values
Scan your data to locate missing cells, blank spaces in text, unanswered survey responses, etc. This could be due to incomplete data or human error. You’ll need to determine whether everything connected to this missing data – an entire column or row. should be completely discarded, individual cells entered manually, or left as is.
The best course of action to deal with missing data will depend on the analysis you want to do and how you plan to preprocess your data. Sometimes you can even restructure your data, so the missing values won’t affect your analysis.
Outliers
Outliers are data points that fall far outside of the norm and may skew your analysis too far in a certain direction. For example, if you’re averaging a class’s test scores and one student refuses to answer any of the questions, his/her 0 would have a big impact on the overall average. In this case, you should consider deleting this data point.
However, just because a number is much smaller or larger than the other numbers you’re analyzing, doesn’t mean that the ultimate analysis will be inaccurate. Just because an outlier exists, doesn’t mean that it shouldn’t be considered. You’ll have to consider what kind of analysis you’re running and what effect removing or keeping an outlier will have on your results.
Handling Noisy Data
Noisy data is meaningless data that can’t be interpreted by machines. It can be generated due to faulty data collection, data entry errors, etc. It can be handled in the following ways:
- Binning Method:
- This method works on sorted data to smooth it. The whole data is divided into segments of equal size and then various methods are performed to complete the task. Each segment is handled separately. One can replace all data in a segment by its mean or boundary values can be used to complete the task.
- Regression:
- Here data can be made smooth by fitting it to a regression function. The regression used may be linear (having one or multiple independent variable).
- Clustering:
- This approach groups similar data in a cluster. The outliers may be undetected or they will fall outside the clusters.
Data validation
At the end of the data cleaning process, you must ensure that the following questions are answered or not.
- Do you have enough data for your process?
- Is it uniformly formatted in a design or language that your analysis tools can work with?
- Does your clean data immediately prove or disprove your theory before analysis?
Validate that your data is regularly structured and sufficiently clean for your needs.
Machine learning and AI tools can be used to verify that your data is valid and ready to be put to use.
Importance of data cleaning
Data cleaning is the initial step in data preprocessing. Data cleaning helps in increasing the model’s accuracy as it deals with missing values, irrelevant data, incomplete data, etc. Almost all organizations depend on the data for most things, but only a few will be successful in analyzing the quality of the data. It helps in reducing errors in the data and improves the quality of the data.
Data Cleaning helps in considering the missing values and their impact on our model. It also helps in achieving data consistency. It makes visualization easy as the dataset becomes clear and meaningful after performing data cleansing.
Recommended for you:
Machine Learning Optimization Techniques

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained