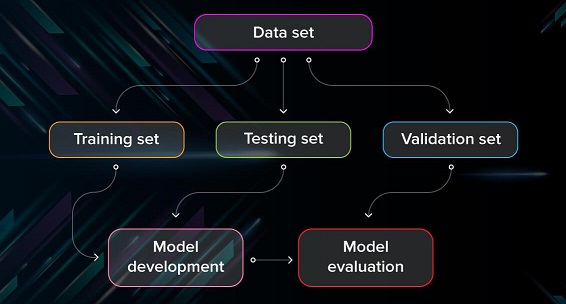
Dataset splitting is highly necessary to eliminate or reduce bias to training data in Machine Learning Models. This process is always done to prevent the machine learning algorithms from resulted into an overfitting type which could perform poorly on the test data. Data scientists split the datasets into discrete subsets on which they train different parameters. It was suggested that training set should be the largest, where cross-validation set or testing set can share the same percentages.
Data Splitting Definition
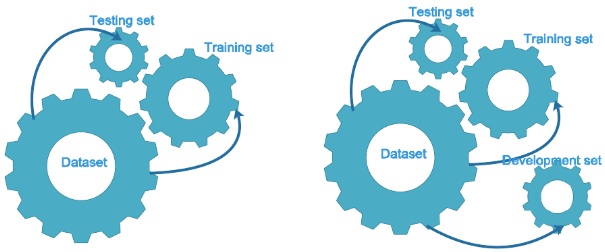
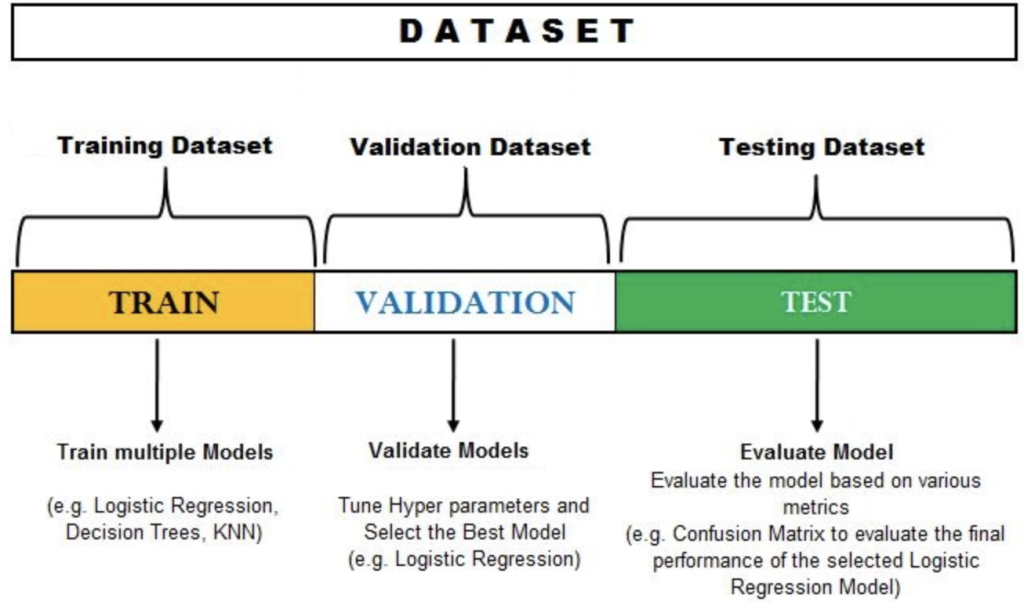
You need to have a mechanism to assess how well your model is generalizing. Hence, you need to separate your input data into training, validation, and testing subsets to prevent your model from overfitting and to evaluate your model effectively. You take a given dataset and divide it into three subsets. Description of the role of each of these datasets is below.
Training Dataset
Training dataset is also known as training data, and training set. It’s an essential component of every machine learning model and helps them make accurate predictions or perform a desired task.
Simply put, training dataset builds the machine learning model. It teaches model what the expected output looks like. The model analyzes the dataset repeatedly to deeply understand its characteristics and adjust itself for better performance.
The proportion to be divided is completely up to the task you face. It is not essential that 70% of the data has to be for training and 30% for testing. It completely depends on the dataset being used and the task to be accomplished. It depends on you, what precision or accuracy you need to achieve based on your task. In Machine Learning, the bigger the dataset to train is better.
Test Dataset
Test dataset is a dataset that is independent of the training dataset, but that follows the same probability distribution as the training dataset. If a model fit to the training dataset also fits the test dataset well, minimal overfitting has taken place.
Test dataset is therefore a set of examples used only to assess the performance of a fully specified classifier. To do this, the final model is used to predict classifications of examples in the test set. Those predictions are compared to the examples’ true classifications to assess the model’s accuracy.
In simple words, test dataset is a set of data used to provide an unbiased evaluation of a final model fitted on the training dataset.
Validation Dataset
Validation dataset is also known as the Dev dataset or the Development dataset. This makes sense since this dataset helps during the “development” stage of the model.
Validation dataset is used to evaluate the model’s hyperparameters. Our machine learning model will go through this dataset, but it will never learn anything from the validation dataset. Data Scientists use the results of a Validation dataset to update higher level hyperparameters. So validation dataset affects a model, but only indirectly. Validation dataset is used to evaluate a given model for frequent evaluation.
Dataset Splitting Ratio
Splitting your dataset into Training, Validation and Test datasets mainly depends on 2 things. First, the total number of samples in your data and second, on the actual model you are training.
Some models need substantial data to train upon. Models with very few hyperparameters will be easy to validate and tune, so you can probably reduce the size of your validation dataset, but if your model has many hyperparameters, you would want to have a large validation dataset as well. Also, if you have a model with no hyperparameters or ones that cannot be easily tuned, you probably don’t need a validation dataset.
Many a times, people first split their dataset into Training and Test. After this, they keep aside the Test dataset, and randomly choose X% of their Training dataset to be the actual Training dataset and the remaining X% to be the Validation dataset, where X is a fixed number, the model is then iteratively trained and validated on these different datasets. There are multiple ways to do this. Basically you use your training set to generate multiple splits of the Train and Validation datasets. Cross validation avoids over fitting and is getting more and more popular, with K-fold Cross Validation being the most popular method of cross validation.
All in all, training – test – validation split ratio is also quite specific to your use case and it gets easier to make judge ment as you train and build more and more models.
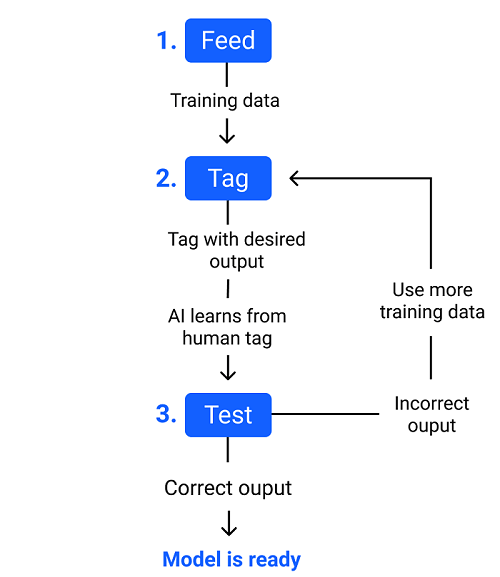
How training and test dataset is used in machine learning
Just as humans rely on past experiences to make better decisions, ML models look at their training dataset with past observations to make predictions. Predictions could include classifying images as in the case of image recognition or understanding the context of a sentence as in natural language processing.
These experiences an algorithm can take from the training dataset, which is fed to it. Further, one of the great things about ML algorithms is that they can learn and improve over time on their own, as they are trained with the relevant training dataset. Once the model is trained enough with the training dataset, it is tested with the test dataset. We can understand the whole process of training and testing in three following steps:
- Firstly, we need to train the model by feeding it with training dataset.
- Define: Now, training dataset is tagged with the corresponding outputs, and the model transforms the training data into text vectors or a number of data features.
- Test: In the last step, we test the model by feeding it with the test dataset. This step ensures that the model is trained efficiently and can generalize well.
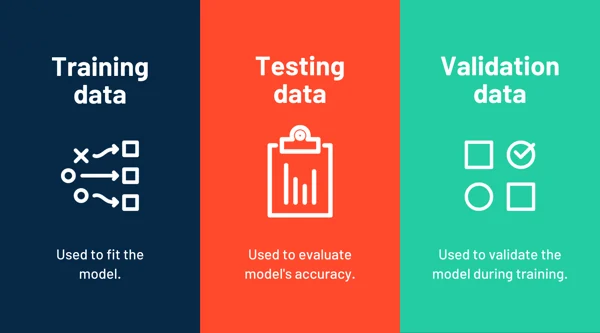
Training dataset vs. Test dataset vs. Validation dataset
Training dataset is the data used to fit the model. On the contrary, test dataset is used to evaluate the performance or accuracy of the model.
Once an ML algorithm is trained on a particular dataset and if you test it on the same dataset, it’s more likely to have high accuracy because the model knows what to expect.
But that’s never the case. A training dataset can never be comprehensive and can’t teach everything that a model might encounter in the real world. Therefore a test dataset, containing unseen data points, is used to evaluate the model’s accuracy.
Then there’s validation data. This is a dataset used for frequent evaluation during the training phase. Although the model sees this dataset occasionally, it doesn’t learn from it.
Although validation dataset is separate from training dataset, data scientists might reserve a part of the training dataset for validation. This means that the validation data was kept away during the training.
Many use the terms “test dataset” and “validation dataset” interchangeably. The main difference between the two is that validation dataset is used to validate the model during the training, while the testing dataset is used to test the model after the training is completed.
Data Splitting Infographic
I hope I’ve given you good understanding of what is data splitting in machine learning.
I am always open to your questions and suggestions.
You can share this post on Linkedin, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Anomaly Detection in Machine Learning
Data Cleaning in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained