What does Feature Scaling mean?
Increasing accuracy in machine learning models is often obtained through the first steps of data transformations.
In practice, we often encounter different types of variables in the same dataset. A significant issue is that the range of the variables may differ a lot. Using the original scale may put more weights on the variables with a large range.
For example, consider a dataset contains of two features, age, and income. Age feature is a range from 0–100, while income feature range is about 1,000 times larger than age. So, these two features are in very different ranges. When we do further analysis, like linear regression, the attributed income will intrinsically influence the result more due to its larger value. But this doesn’t necessarily mean it is more important as a predictor. Therefore, the range of all features should be scaled so that each feature contributes approximately proportionately to the final distance. For this purpose, using Feature Scaling is essential.
In order to deal with this problem, we need to apply the technique of features rescaling to independent variables or features of data in the step of data pre-processing.The terms normalisation and standardisation are sometimes used interchangeably, but they usually refer to different things.The goal of applying Feature Scaling is to make sure features are on almost the same scale so that each feature is equally important and make it easier to process by most ML algorithms.
This post explains standardization the difference between the key feature-scaling methods of standardization and normalization.
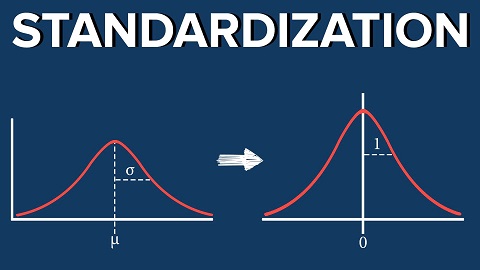
What is Standardization?
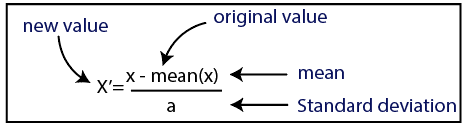
Standardization or z-score normalization is a scaling technique such that when it is applied, the features will be rescaled so that they’ll have the properties of a standard normal distribution with mean=0 and standard deviation=1.
Standardization is useful for the optimization algorithms, such as gradient descent, that are used within machine learning algorithms that weight inputs (e.g., regression and neural networks). Rescaling is also used for algorithms that use distance measurements, for example, K-Nearest neighbours.
Why Should We Use Feature Scaling?
Some of machine learning algorithms are sensitive to feature scaling while others are virtually invariant to it.
Standardization will transform features coming from any distribution so that, it will have zero mean and unit variance.
Column standardization is often called mean centering and variance scaling(squishing/expanding).
Note that: Just because the transformed distribution has mean 0 and variance 1, it should not be concluded it will follow the Gaussian distribution. if a Gaussian distribution is standardized, then the standardized distribution will follow Gaussian distribution, but if any other distribution is standardized, it will follow a distribution which will ONLY have mean 0 and variance 1.
When does Feature Scaling Matter ?
Some machine learning algorithms are based on distance matrix, also known as the distance based classifier, for example, K-Nearest Neighbours, SVM, and Neural Network. Feature scaling is extremely essential to those models, especially when the range of the features is very different. Otherwise, features with a large range will have a large influence in computing the distance.
Max-Min normalization allows us to transform the data with varying scales so that no specific dimension will dominate the statistics. However, normalization does not treat outliers very well. On the other hand, standardization allows users to better handle the outliers and facilitate convergence for some algorithms like gradient descent.
When to use Standardization
By scaling, the accuracy of the model in following algorithms will increase.
- Gradient Descent:
- Theta calculation will become faster.
- K-Nearest Neighbor:
- Measure the distance between pairs of samples and their distances are influenced by the measuring units.
- K-Means Clustering:
- Due to Euclidian Distance Measurement.
- SVM:
- Due to Euclidian distance measurement.
- Lasso and Ridge Regression:
- It puts constraints on the size of coefficients for each variable w.r.t to magnitude and there will be no intercept.
- Principle Component Analysis:
- Try to get the feature with the maximum variance.
When it is not necessary to apply Standardization
Tree-based algorithms are fairly insensitive to the scale of the features.
- Random forest
- Bagging techniques
- Decision Tree
No effect on accuracy of these algorithms.
- XG-Boost
- Gradient Boost
Standardization vs Normalization
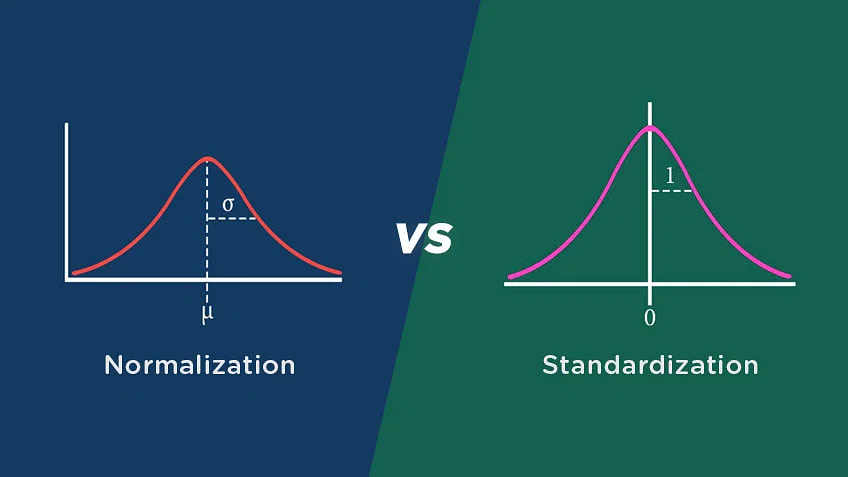
Standardization Technique
- Standardization scales the model using the mean and standard deviation.
- It is beneficial, when a variable’s mean=0 and standard deviation=1.
- Values on a scale are not constrained to a particular range.
- When the feature distribution is consistent, it is helpful.
Normalization Technique
- Normalization scales the model using minimum and maximum values.
- It is functional, when features are on various scales.
- Values on the scale fall between [0, 1] and [-1, 1].
- When the feature distribution is unclear, it is helpful.
Usage of Standardization instead of Normalization
Standardization is better when we have outliers. outliers will have large negative or positive values while inliers will have values around 0.
Normalization (using min and max) in the case of data with outliers could result in outliers having values closer to 0 and 1 and most inliers concentrated in a small band of values.
Min-Max Normalization has one important downside that it does not handle outliers with ease. Lets assume we have 99 values between 0 and 30, and one value is 110, then the 99 values will all be transformed to a value between 0 and 0.4.
That data is just as squished as before!
Recommended to you:
Data Normalization in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained