
For developing machine learning models, it is common to split the dataset into training and test subsets. The training set is used for fitting the model, that is, to estimate the hyperparameters in the model.
The model is then evaluated for its accuracy using the test set. The reason for doing this is because if we were to use the entire dataset for fitting, the model would overfit the data and can lead to poor predictions in future scenarios.
Therefore, holding out a portion of the dataset and testing the model for its performance before deploying it in the field can protect against unexpected issues that can arise due to overfitting.
Generally, datasets are divided into either two or three subsets called training, validation, and test subsets. The training set is the portion of the dataset used to teach the model relevant patterns in the data.
Validation sets are typically used to confirm how well the patterns learned in the training stage apply to unseen data.
Validation sets give you a general idea of how well your model may perform in the real-world, also allows you to continue tuning your model to obtain the optimal results.
Once a model is tuned and ready for deployment, the test set includes unseen data that can be used to validate the final evaluation metric of the model.
In this post we explain most common techniques to split dataset.
Techniques to Split Dataset
Random Manual Splitting
Random manual splitting is a commonly used method that randomly divides the dataset into training, validation, and test subsets. One of the biggest disadvantages to random manual splitting is it that it is tedious and prone to human error.
Random manual splitting is highly discouraged for live production environments, and even in smaller experiments can unnecessarily open the door to quite a bit of error. In some cases, manual splitting may also require a certain degree of domain knowledge, which we may not have.
Train Test Split Method
The dataset is divided right into a training and test subsets. The training set is used to educate the model, even as test set is used to assess the model’s overall performance.
The regular cut up is 70% for training and 30% for test, but this may vary depending on the scale of the dataset and the precise use case.
If dataset is split into three training, validation and a test subsets. The training set is used to train the model, the validation set is used to tune hyperparameters and validate the version’s overall performance for the duration of training, and the testing set is used to evaluate the last version’s overall performance.
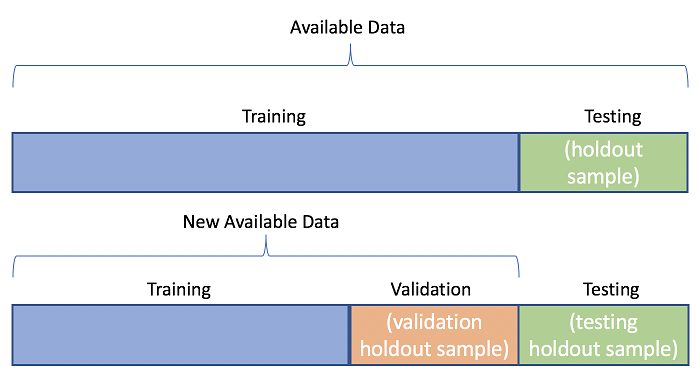
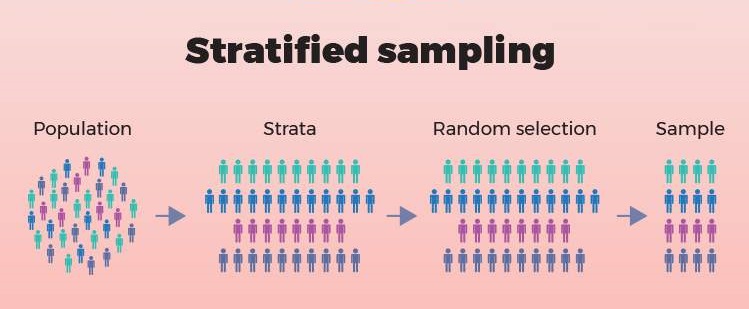
Stratified Sampling Method
This technique guarantees that the distribution of training or other essential features is preserved in the training and test subsets. This is in particular beneficial when coping with imbalanced datasets, wherein some classes may additionally have only a few samples.
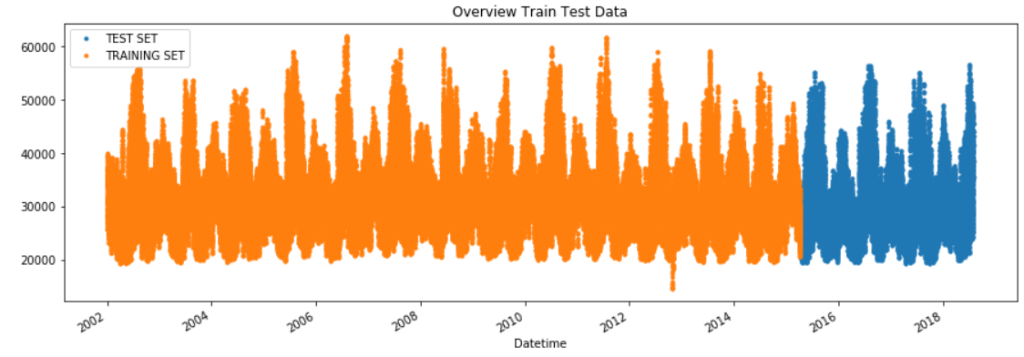
Time Series Split Method
When coping with time series facts, consisting of stock costs or weather statistics, the dataset is regularly cut up into training and test subsets based on a chronological order. This facilitates in comparing the model’s performance on future unseen facts.
Cross Validation Method
Cross-validation is a resampling method that uses different portions of the dataset to test and train the model over the course of various iterations. It involves dividing the available data into multiple subsets, using one of these folds as a validation set, and training the model on the remaining folds.
This process is repeated multiple times, each time using a different fold as the validation subset. Finally, the results from each validation step are averaged to produce a more robust estimate of the model’s performance.
Cross-validation not only optimizes intra-model selection, but also inter-model selection, as it allows us to get a broader idea of the performance of a model on different subsets of dataset, and therefore gives us a more reliable evaluation metric to choose our final model from.
Cross validation helps to ensure that the model selected for deployment is robust and generalizes well to new data.
There are several cross-validation methods that you can use: K-fold Cross-Validation, Leave-One-Out Cross-Validation, and Stratified K-fold Cross-Validation.
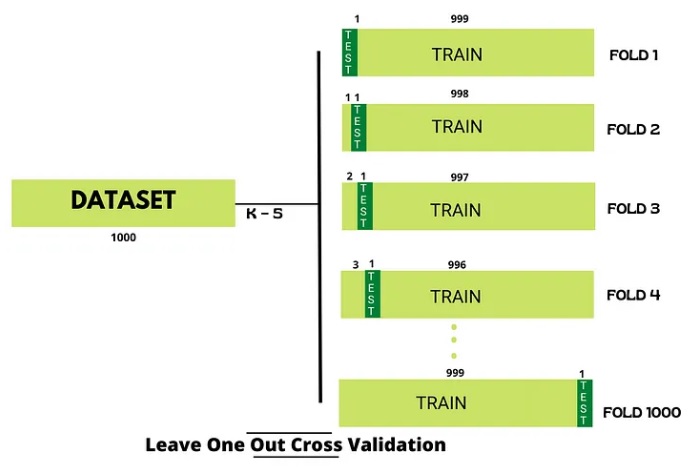
Leave-One-Out Cross-Validation (LOOCV)
In this method, one data point is used for testing and the entirety of the remaining data is used for training. This process is then repeated until every individual data point has been used as the test data.
This method is similar to K-fold in its structure, but with LOOCV, you can’t specify the number of folds (there will always be two folds).
It has some advantages as well as disadvantages also.
Advantage of using this method is that we make use of all data points and hence it is low bias.
The major drawback of this method is that it leads to higher variation in the testing model as we are testing against one data point. If the data point is an outlier it can lead to higher variation.
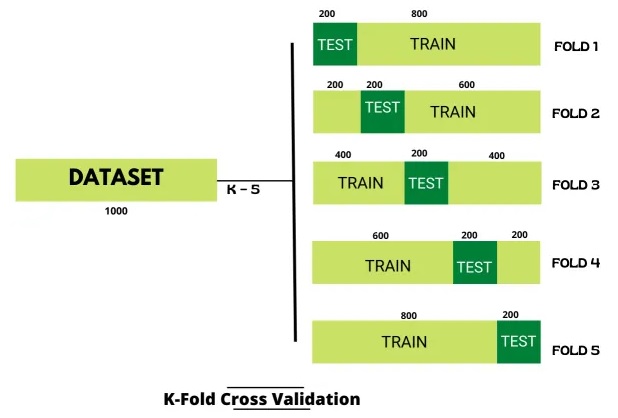
K-fold Cross-Validation
In K-Fold Cross Validation, we split the dataset into k number of folds then we perform training on the all the folds but leave one (k-1) fold for the evaluation of the trained model. In this method, we iterate k times with a different subset reserved for testing purpose each time.
Note: It is always suggested that the value of k should be 10. The lower value of k is takes towards validation and higher value of k leads to LOOCV method.
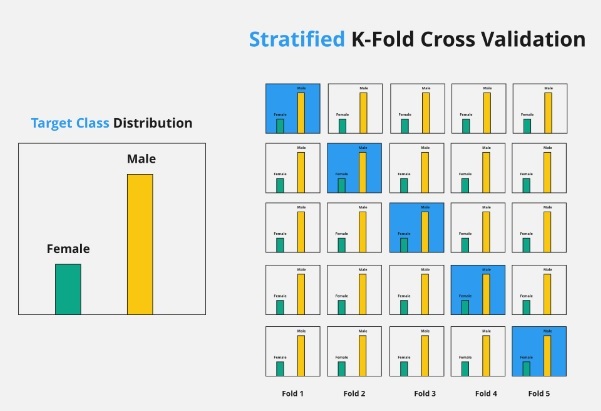
Stratified K-fold Cross-validation
Stratified K-fold cross-validation is a variation of cross-validation that uses stratified sampling rather than random sampling to create subsets of the data.
It is used in machine learning to ensure that each fold of the cross-validation process maintains the same class distribution as the entire dataset. This is particularly important when dealing with imbalanced datasets, where some classes may be underrepresented.
In stratified sampling, the data is divided into K- number of non-overlapping groups that each have distributions resembling the distribution of the full dataset. Each subset will have an equal number of values for each class label.
Advantages of Cross Validation
- Cross validation helps to prevent overfitting by providing a more robust estimate of the model’s performance on unseen data.
- Cross validation can be used to compare different models and select the one that performs the best on average.
- Cross validation can be used to optimize the hyperparameters of a model, by selecting the values that result in the best performance on the validation set.
- Cross validation allows the use of all the available data for both training and validation, making it a more data-efficient method compared to traditional validation techniques.
Disadvantages of Cross Validation
- Cross validation can be computationally expensive, especially when the number of folds is large or when the model is complex.
- Cross validation can be time-consuming, especially when there are many hyperparameters to tune or when multiple models need to be compared.
- Choice of the number of folds in cross validation impact the bias-variance tradeoff, i.e., too few folds may result in high variance, while too many folds may result in high bias.
It’s vital to keep in mind dataset splitting approach primarily based at the hassle, dataset size, and other elements to make certain that the version is skilled and evaluated effectively.
I hope I’ve given you good understanding of dataset splitting techniques.
I am always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Data Splitting in Machine Learning
Confusion Matrix


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained