
What is deep learning?
Deep learning (also known as deep structured learning) is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
The main idea behind deep learning is that artificial intelligence should draw inspiration from the brain. This perspective gave rise to the “neural network” terminology. The brain contains billions of neurons with tens of thousands of connections between them. Deep learning algorithms resemble the brain in many conditions, as both the brain and deep learning models involve a vast number of computation units (neurons) that are not extraordinarily intelligent in isolation but become intelligent when they interact with each other.
Neurons
The basic building block for neural networks is artificial neurons, which imitate human brain neurons. These are simple, powerful computational units that have weighted input signals and produce an output signal using an activation function. These neurons are spread across several layers in the neural network.
The neuron takes in a input and has a particular weight with which they are connected with other neurons. Using the Activation function the nonlinearities are removed and are put into particular regions where the output is estimated.
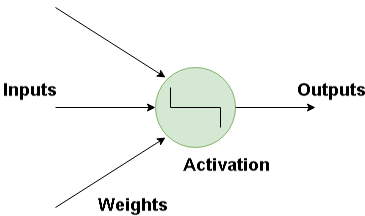
How Do Neural Network Works?
As data travels through this artificial mesh, each layer processes an aspect of the data, filters outliers, spots familiar entities, and produces the final output.
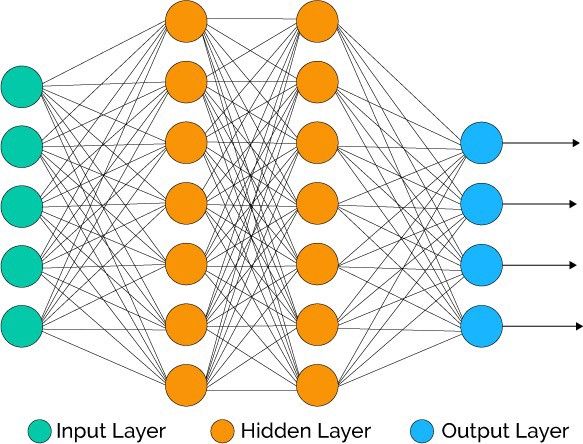
Input layer : This layer consists of the neurons that do nothing than receiving the inputs and pass it on to the other layers. The number of layers in the input layer should be equal to the attributes or features in the dataset.
Output Layer: The output layer is the predicted feature, it basically depends on the type of model you’re building.
Hidden Layer: In between input and output layer there will be hidden layers based on the type of model. Hidden layers contain vast number of neurons. The neurons in the hidden layer apply transformations to the inputs and before passing them. As the network is trained the weights get updated, to be more predictive.
NEURON WEIGHTS
Weights refer to the strength or amplitude of a connection between two neurons, if you are familiar with linear regression you can compare weights on inputs like coefficients we use in a regression equation. Weights are often initialized to small random values, such as values in the range 0 to 1.
FEED FORWARD
Feedforward supervised neural networks were among the most successful learning algorithms. They are also called deep networks, multi-layer Perceptron (MLP), or simply neural networks and the vanilla architecture with a single hidden layer is illustrated. Each Neuron is associated with another neuron with some weight,
The network processes the input upward activating neurons as it goes to finally produce an output value. This is called a forward pass on the network.
How data passes through the series of layers.
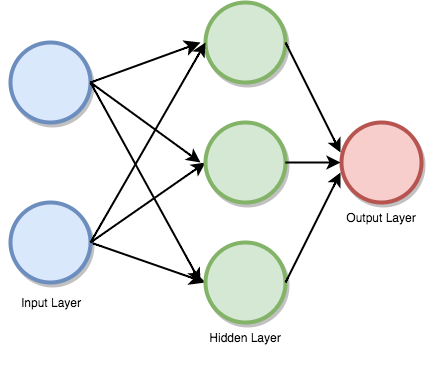
ACTIVATION FUNCTION
An activation function is a mapping of summed weighted input to the output of the neuron. It is called an activation/ transfer function because it governs the inception at which the neuron is activated and the strength of the output signal.
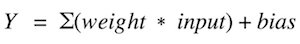
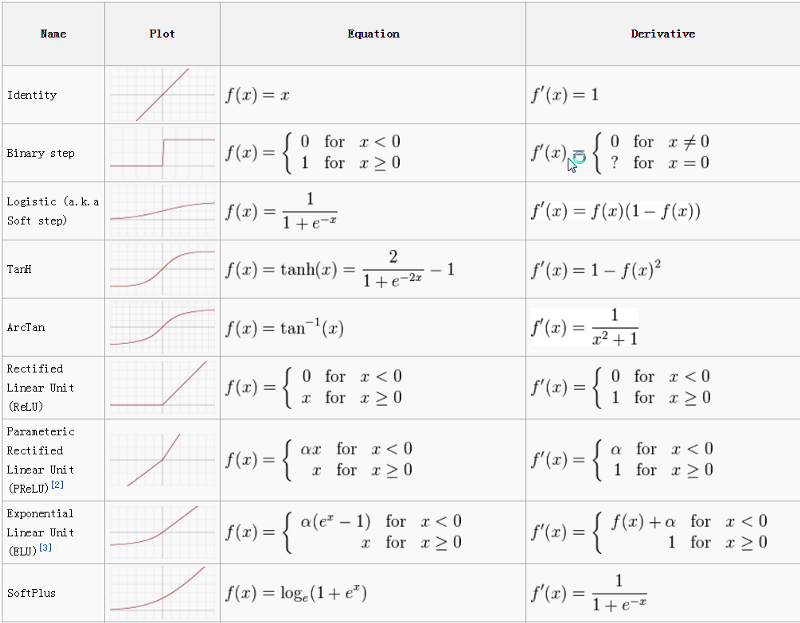
The most commonly used activation functions are relu, tanh, softmax. The cheat sheet for activation functions is given below.
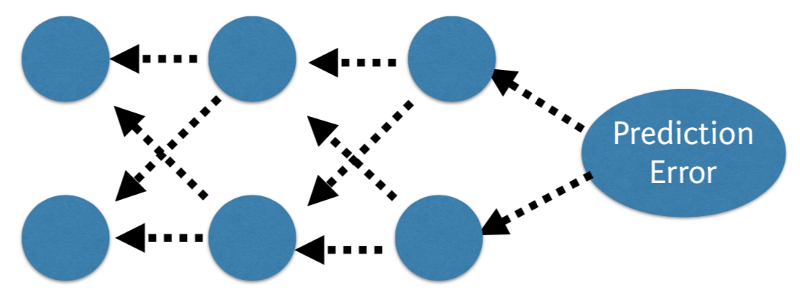
BACK PROPAGATION
The predicted value of the network is compared to the expected output, and an error is calculated using a function. This error is then propagated back within the whole network, one layer at a time, and the weights are updated according to the value that they contributed to the error. This clever bit of math is called the backpropagation algorithm. The process is repeated for all of the examples in your training data. One round of updating the network for the entire training dataset is called an epoch. A network may be trained for tens, hundreds or many thousands of epochs.
COST FUNCTION AND GRADIENT DESCENT
The cost function is the measure of “how good” a neural network did for its given training input and the expected output. It also may depend on attributes such as weights and biases.
A cost function is single-valued, not a vector because it rates how well the neural network performed as a whole. Using the gradient descent optimization algorithm, the weights are updated incrementally after each epoch.
Compatible Cost Function:
Sum of squared errors (SSE)
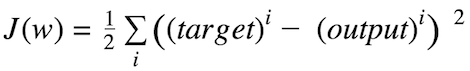
The magnitude and direction of the weight update are computed by taking a step in the opposite direction of the cost gradient.
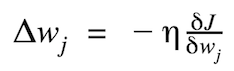
where Δw is a vector that contains the weight updates of each weight coefficient w, which are computed as follows:
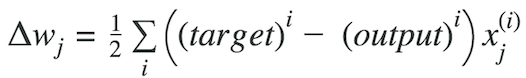
Graphically, considering cost function with single coefficient
We calculate the gradient descent until the derivative reaches the minimum error, and each step is determined by the steepness of the slope (gradient).
MULTILAYER PERCEPTRONS
This class of networks consists of multiple layers of neurons, usually interconnected in a feed-forward way (moving in a forward direction). Each neuron in one layer has direct connections to the neurons of the subsequent layer. In many applications, the units of these networks apply a sigmoid or relu function as an activation function.
Recommended for you:
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained