
Data scientists spend a huge amount of time doing data preprocessing like feature engineering. Feature selection is also a very common step in many machine learning projects.
In this post, we discuss the importance of feature selection in machine learning. we highlight why we should select features when using our models for business problems.
What is Feature Selection
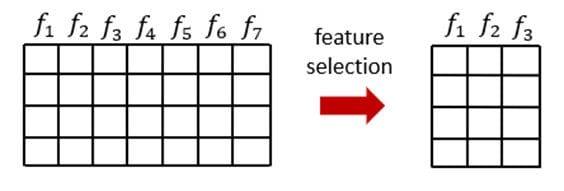
Feature selection in Machine Learning consists of selecting the best features for our algorithms. The goal of feature selection in machine learning is to choose a small subset of the relevant features from the original features by removing irrelevant, redundant, or noisy features.
It usually can lead to better learning performance, higher learning accuracy, lower computational cost, and better model interpretability.
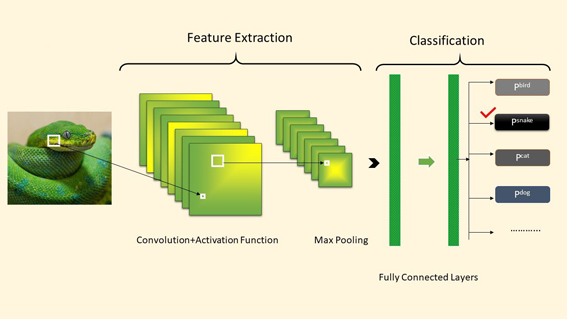
Almost all machine learning workflows depend on feature engineering, which comprises feature extraction and feature selection that are building blocks of machine learning pipelines.
The feature selection process is based on selecting the most consistent and relevant features.
Below are some benefits of feature selection in machine learning:
- It helps in avoiding the curse of dimensionality.
- Simplification of models to make them easier to interpret by the researchers.
- Shorter training times.
- Enhanced generalization by reducing overfitting.
Feature Selection Importance
Machine learning models follow a basic rule: whatever goes in, comes out. If we put noise into our model, we can expect the output to be noise too.
For training a model, we collect enormous quantities of data to help the model learn better. Usually, a good portion of the dataset collected is noise, while some of the features of dataset might not contribute significantly to the performance of the model.
Apart from choosing the right algorithm for dataset, we need to choose the right data to put in our model. Good feature selection is what separates good data scientists from the rest.
Feature Selection Techniques
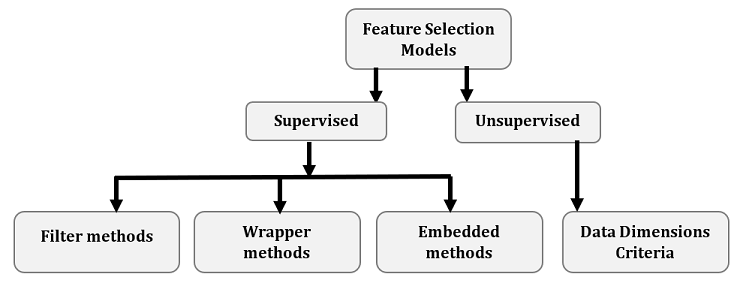
Feature selection techniques in machine learning can be classified into two categories:
- Supervised Techniques
- Supervised techniques can be used for labeled data to identify the relevant features for increasing the efficiency of both classification and regression models.
- Unsupervised Techniques
- Unsupervised Techniques can be used for unlabeled data. For example, k-mean clustering, principal component analysis.
Feature Selection Methods
- Wrapper Methods
- In wrapper Methods, features selection is done by considering it as a search problem, in which different combinations are made, evaluated, and compared with other combinations.
- Filter Methods
- Filter methods pick up the intrinsic properties of the features measured via univariate statistics. These methods are faster and less computationally expensive than wrapper methods. It is computationally cheaper to deal with high dimensional data.
- Embedded Methods
- Embedded methods combined both filter and wrapper methods by considering the interaction of features along with low computational cost. It is fast and more accurate processing method than the filter method.
- Information Gain
- Information gain calculates the reduction in entropy from the transformation of a dataset. It evaluates the Information gain of each variable in the context of the target variable.
- Chi-square test
- Chi-square test is used for categorical features in a dataset. We calculate chi-square between each feature and the target. Then select the desired number of features with the best chi-square scores. In order to apply the chi-squared to test the relation between various features and target in the dataset, following conditions is required:
- The variables have to be categorical.
- Sampled independently.
- Values should have an expected frequency greater than 5.
- Chi-square test is used for categorical features in a dataset. We calculate chi-square between each feature and the target. Then select the desired number of features with the best chi-square scores. In order to apply the chi-squared to test the relation between various features and target in the dataset, following conditions is required:
- Hybrid Methodology
- Creating hybrid feature selection methods depends on what you choose to combine. The main priority is to select the methods you’re going to use, then follow their processes.
- Exhaustive search
- Exhaustive search is the greediest method. It tries all combinations of features, for any number of features from one until the maximum number of features available. This method is extremely computationally expensive but would provide the best subset of features.
- Random forest feature importance
- Random forest is generally very popular among the machine learning algorithms because they provide good predictive performance, low overfitting, and easy interpretability.
- Part of the interpretability encompasses how straightforward is to derive the importance of each feature on a decision, which makes it one of the best embedded methods of feature selection.
- Correlation Coefficient
- Correlation is a measure of the linear relationship between variables. Through correlation, we can predict one variable from the other. The logic behind using correlation for feature selection is that good variables correlate highly with the target.
- Variance Threshold
- Variance threshold removes all features whose variance doesn’t meet some threshold. By default, it removes all zero-variance features, i.e., features with the same value in all samples. We assume that features with a higher variance may contain more useful information.
- Mean Absolute Difference
- It computes the absolute difference from the mean value. The main difference between the variance and mean absolute difference measures is the absence of the square in the latter. The higher mean absolute difference, the higher the discriminatory power.
- Forward Feature Selection
- This is an iterative method wherein we start with the performing features against the target features. Then, we select another variable that gives the best performance in combination with the first selected variable. Selection process continues until the preset criterion is achieved.
- Backward Feature Elimination
- This method starts with all the features available and build a model. Then, we the variable from the model, which gives the best evaluation measure value. This process is continued until the preset criterion is achieved.
Choose a Feature Selection Model
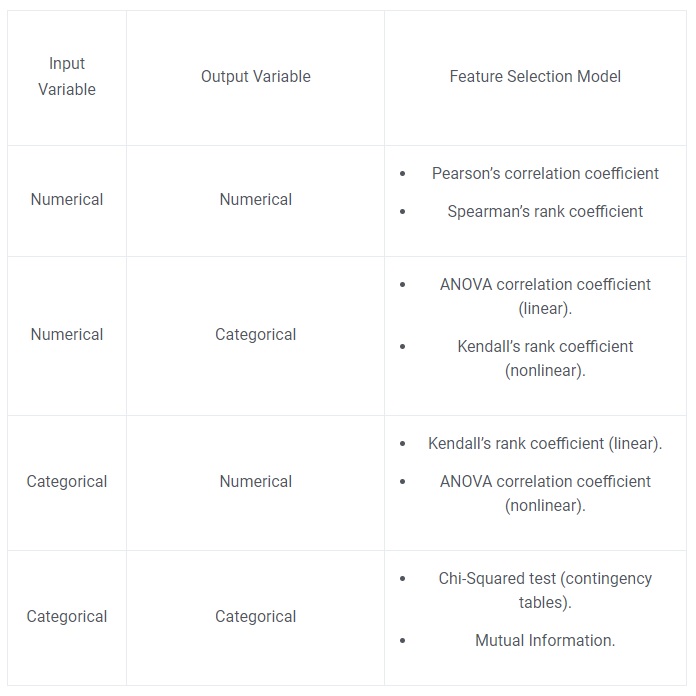
The process is relatively simple, with the model depending on the types of input and output variables. There are two main types of Variables:
- Numerical Variables
- Which include integers, float, and numbers.
- Categorical Variables
- Which include labels, strings, boolean variables.
Based on whether we have numerical or categorical variables, we can summarize the cases with appropriate measures in the below table:
Feature Selection Infographic
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Feature Engineering in Machine Learning
Feature Encoding in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained