
The real-world data needs processing before feeding it to a machine learning model. We know that around 80% of a data scientist’s time goes into data preprocessing and 20% of the time into model building. Hence, data preprocessing is a crucial step in machine learning. One of the most crucial steps in preprocessing is feature encoding.
The objective of this post is to demonstrate feature encoding techniques to transform a categorical feature into a numerical feature.
What is Feature Encoding
Encoding is a feature engineering technique that is used to transform categorical data into a numerical format, which makes it accessible for training machine learning models. Using encoding is useful when you’re working with a feature where the data has no relationship to one another. Because machine learning algorithms can only work with numbers, we need to be mindful of how we encode our values. By assigning numbers for categorical data, we apply an attribute of significance to our data.
Encoding allows you to make sure that your data can be rescaled easily. This is beneficial when working with many different categories, allowing your data to be more expressive.
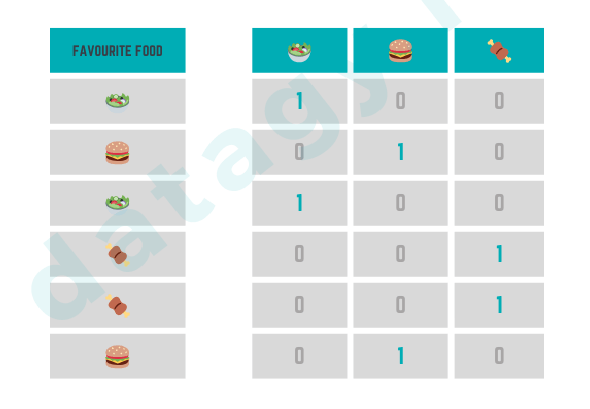
Categorical feature encoding are of two types:
- Ordinal categorical variables: These variables can be ordered (for example, grades in an exam. Here, one can say that C {C:1, B:2, A:3}
- Nominal categorical variables: These variables can’t be ordered (for example colors). One Hot Encoding is preferred in such a situation. In One Hot Encoding, Each categorical value is converted into a new categorical column and assigned a binary value of 1 or 0 to those columns.
Advantages of Encoding in Machine Learning
- Preservation of categorical information: encoding retains the categorical nature of data by converting it to binary vectors.
- Enhanced model performance: encoding allows your model to learn from categorical data, allowing the data to be easily differentiated.
- Reduced risk of bias: Since machine learning models need to work with numbers, your categorical data needs to be encoded. encoding eliminates any artificial ordinal relationships between categories, removing the risk of bias.
- Interpretability and feature importance: encoding allows you to easily understand which categories are more influential in your model’s decision-making abilities.
Disadvantages of Encoding in Machine Learning
- High dimensionality: encoding has the potential to significantly increase the dimensionality of a dataset. This is because one column is added for each unique value in a given column.
- Increased storage requirements: by storing the binary vectors that are generated when we encode data, our storage requirements increase as well.
- Handling rate categories: Categories that are infrequent in a categorical column can result in sparse encoded binary vectors that are mostly zeros. This can lead to an issue where machine learning algorithms
- Increased computation time: Because the data will be of a higher dimension, certain machine learning algorithms will require longer to train and to make predictions.
- Interpretability challenges: When working with a large number of encoded features, the specific importance attributed to each feature can be difficult to interpret.
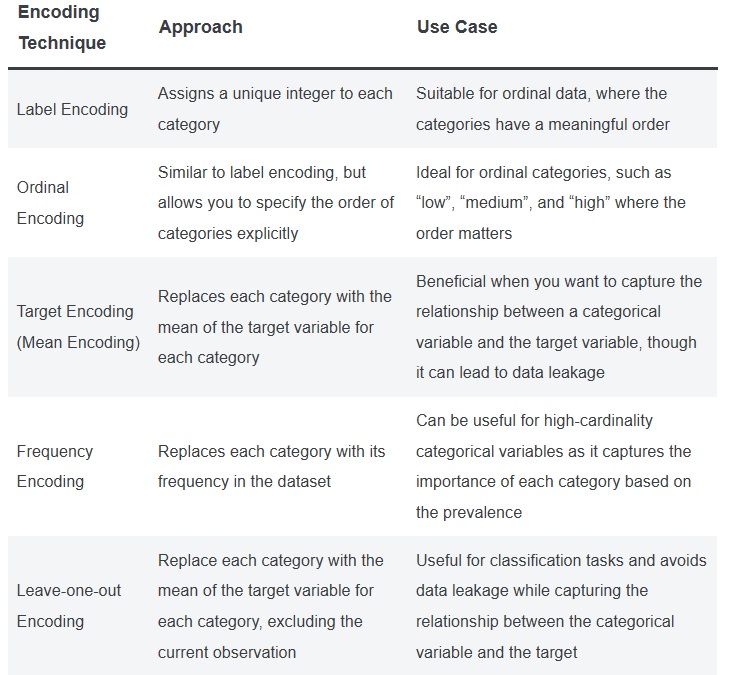
With everything you have learned about encoding in this post, there are many of technique to encode your data that may be more appropriate for your specific problem. Let’s explore some of the encoding technique you may want to use them.
Recommended for you:
Anomaly Detection in Machine Learning
Feature Engineering in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained