In machine learning projects, we may assume that a more significant number of features means more details on the target variable. But datasets may consist of relevant, irrelevant features.
While building a machine learning model with datasets which consist of a massive number of features, it becomes complicated for us to visualize and also consumes a lot of time and memory. Sometimes, the model performs poorly on the testing subset because of the irrelevant features in the dataset. Here’s when the concept of feature extraction comes in.
What is Feature Extraction?
It refers to the process of transforming raw data into numerical features that can be processed. It yields better results than applying machine learning directly to the raw data.
In general, Feature extraction in machine learning is taking the features from dataset and mapping it to a lower dimensional set in which each feature is obtained as a function of the original feature dataset.
In simple words, it is the process of establishing a relation among several features to get a new feature.
Feature Extraction from Text
We cannot feed textual data to machine learning models because the Machine Learning algorithms don’t understand text data.
Algorithms understand only numerical data. The process of converting text data into numbers is called extract feature from the text. It is also called text vectorization.
Feature Extraction from Signals
Training machine learning directly with raw signals often yields poor results because of the high data rate and information redundancy.
Feature extraction identifies the most discriminating characteristics in signals, which a machine learning algorithm can more easily consume.
Features Extraction from Time-frequency
Time-frequency transformations, such as the short-time Fourier transform can be used as signal representations for training data in machine or deep learning models. For example, convolutional neural networks are commonly used on image data and can successfully learn from the 2D signal representations returned by time-frequency transformations.
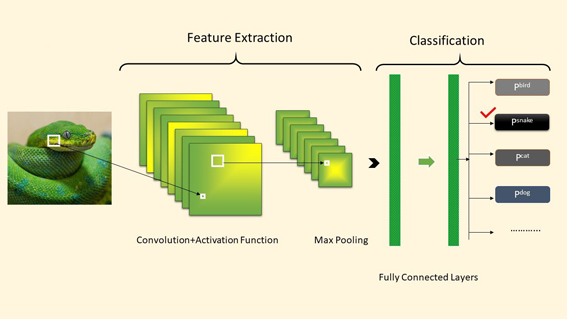
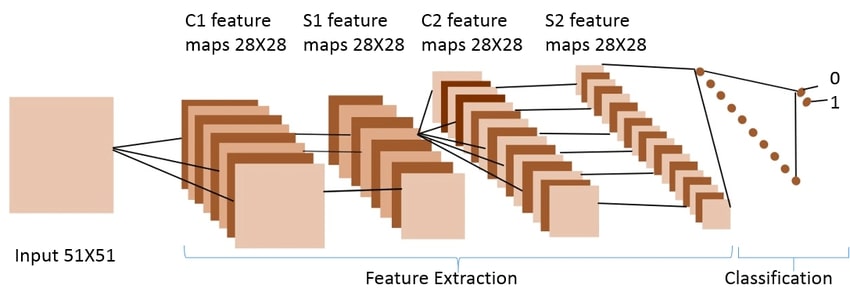
Feature Extraction from Image
Loading images, reading, and then process them through the models is difficult because the machine does not have eyes.
Machines see any images in the form of a matrix of numbers. The size of this matrix actually depends on the number of pixels of the input image. Feature extraction from image represents the interesting parts of an image as a compact feature vector.
Advantages
In machine learning, the performance of the model mainly depends on data preprocessing steps. Below are some points that explain the need for feature extraction.
- Better flexibility in features.
- Increase the accuracy of the model.
- No redundancy in data.
- Better visualization of data.
- It can reduces risk of overfitting.
- Increase in speed of training the model.
- Reduction in computation of the model.
Applications
- Feature extraction is used in Machine Learning while dealing with a dataset which consists of a massive number of features.
- In Natural language Processing, it is used to identify specific keywords based on their frequency of occurrence in a sentence. Here, firstly sentences are tokenized, lemmatized, and stop words are removed. After that, the words are individually classified into the frequency of use.
- Image processing is one of the domains where feature extraction is widely used. Digital images represent different features or attributes such as shapes, hues, motion. thus, processing them is of utmost importance so that only specified features are extracted.
- Auto-encoders is another domain where feature extraction is widely used. It plays a major role in identifying the key features from the data which will help us to code by learning from the coding of the dataset in order to derive new ones.
Feature Extraction Techniques
- One Hot Encoding
- One hot encoding means converting the words of your document into a N-dimension vector. This technique is very intuitive, and you can code it yourself. If size of each document after one hot encoding be different. The machine learning model doesn’t work.
- Principal Component Analysis
- Principal Component Analysis is a method of obtaining important variables from a large set of variables in a dataset. It tends to find the direction of maximum variation in data. Principal Component Analysis is more useful when dealing with high-dimensional data.
- Bag of Words
- The bag of words model is used for text representation and feature extraction in natural language processing.
- It represents a text document as a multiset of words, disregarding grammar and word order. This representation is useful for tasks such as text classification, document similarity, and text clustering.
- Term Frequency-Inverse Document Frequency Vectorizer
- It is a statistical measure used for information retrieval and natural language processing tasks. It reflects the importance of a word in a document relative to an entire corpus.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Feature Engineering in Machine Learning
Feature Selection in Machine Learning


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained