
In machine learning, collecting and processing data can be expensive and time-consuming process. Therefore, choosing informative, discriminating features is a crucial step for algorithms in pattern recognition.
Furthermore, it has become common to see datasets with thousands of features. Therefore, many times algorithm developers are using a process called feature generation. In this post, we describe feature generation to improve machine learning process.
What is Feature Generation?
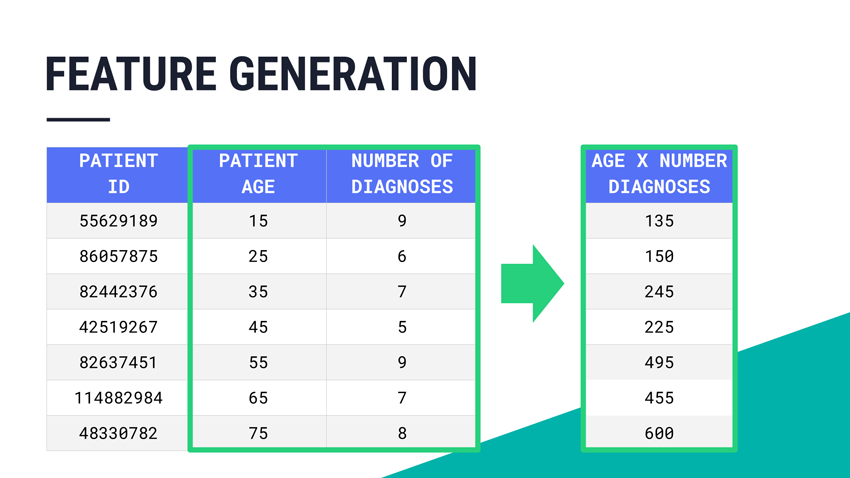
Feature generation also known as feature construction is the process of constructing new features from multiple features. The goal of feature generation is to derive new combinations and representations of our data that might be useful to the machine learning modeling and in the statistical analysis.
By generating features, we can uncover potential new interactions between the features and the target and so improve the model’s performance. By adding new features that encapsulate the feature interaction, new information becomes more accessible for the prediction model.
Feature generation can encompass either extraction or transformation operations. These operations will be encapsulated in an independently executable function that produces a feature. Your feature generator will be things that can take raw data and produce new features that you want to use to learn a model.
Feature Generation Techniques
Datetime
Events may manifest at more than one timescale so, depending on your data, you may wish to decompose a timestamp column into multiple columns, such as: minutes, hour, day, month, season or year.
Geolocation
For predicting home prices, geolocations is a way to add new features to supplement with auxiliary data.
You can add distances to relevant landmarks: city center, good schools, etc. Another feature is building density, with high densities indicating popularity, confluence of transportation options.
Numerical
Numerical features are good candidates to add interaction features. These are formed by performing summing-subtractions-divisions or multiplications between two or more features. They are especially beneficial for tree-based models which have difficulty extracting such dependencies. The difficulty for us, is there’s an infinite number of ways to create such interactions, but only some are helpful.
Categorical
Categorical interaction features are useful for not tree-based algorithms like KNN. They are formed by string-concatenating two categorical features to form a new composite, e.g. concatenating ‘sex’{M, F}.
Feature Generation vs Feature Selection vs Feature Extraction
- Feature generation
- It is the process of taking raw, unstructured data and defining features for potential use in your modeling. For instance, in the case of text mining you may begin with a raw log of thousands of text messages (e.g. SMS, email, social network posts) and generate features by removing low-value words.
- Feature selection
- It is a process of selecting a subset of relevant features from the original features. The goal is to reduce the dimensionality of the feature space and improve its generalization performance.
- Feature extraction
- It is a process of transforming the original features into a subset of features that are more informative. Our goal is to capture the essential information from the original features and represent it in a lower-dimensional space.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Feature Engineering in Machine Learning
Feature Selection in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained