Introduction
It is probably the most popular machine learning algorithm, and is an optimization algorithm mainly used to find the minimum of a function. In machine learning, gradient descent is used to update parameters in a model. Parameters can vary according to the algorithms, such as coefficients in Linear Regression and weights in Neural Networks.
It is an algorithm to minimize the cost function of a model. We can tell this from the meanings of the words ‘Gradient’ and ‘Descent’.
While gradient means the gap between two defined points (that is the cost function in this context), descent refers to downward motion in general (that is minimizing the cost function in this context). So in the context of machine learning, Gradient Descent refers to the iterative attempt to minimize the prediction error of a machine learning model by adjusting its parameters to yield the smallest possible error. This error is known as the Cost Function. The cost function is a plot of the answer of the question “by how much does the predicted value differ from the actual value?”.
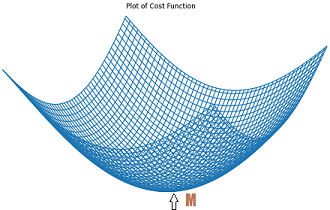
What is Cost-function?
The cost function is defined as the measurement of difference or error between actual values and expected values at the current position and present in the form of a single real number. It helps to increase and improve machine learning efficiency by providing feedback to this model so that it can minimize error and find the local or global minimum. Further, it continuously iterates along the direction of the negative gradient until the cost function approaches zero. At this steepest descent point, the model will stop learning further.
The cost function is calculated after making a hypothesis with initial parameters and modifying these parameters over known data to reduce the cost function.
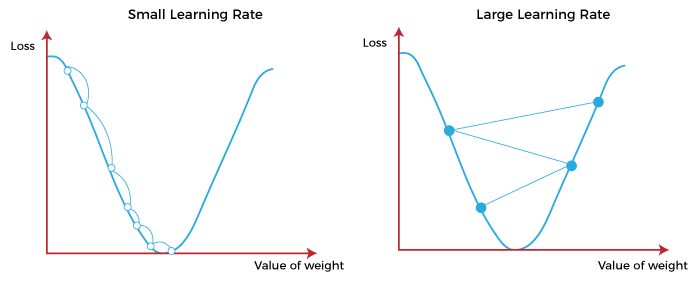
What is Learning Rate?
It is defined as the step size taken to reach the minimum or lowest point. This is typically a small value that is evaluated and updated based on the behavior of the cost function. If the learning rate is high, it results in larger steps but also leads to risks of overshooting the minimum. At the same time, a low learning rate shows the small step sizes, which compromises overall efficiency but gives the advantage of more precision.
Types of Gradient Descent
Batch-Gradient-Descent
Batch gradient descent is used to find the error for each point in the training set and update the model after evaluating all training examples. This procedure is known as the training epoch. In simple words, it is a greedy approach where we have to sum over all examples for each update.
Advantages of Batch-Gradient-Descent:
- It produces less noise in comparison to other.
- It produces stable convergence.
- It is computationally efficient as all resources are used for all training samples.
Stochastic-Gradient-Descent
Stochastic gradient descent runs one training example per iteration. Or in other words, it processes a training epoch for each example within a dataset and updates each training example’s parameters one at a time. As it requires only one training example at a time, hence it is easier to store in allocated memory. However, it shows some computational efficiency losses in comparison to batch gradient systems as it shows frequent updates that require more detail and speed. Further, due to frequent updates, it is also treated as a noisy gradient. However, sometimes it can be helpful in finding the global minimum and also escaping the local minimum.
In situations when you have large amounts of data, you can use stochastic-gradient-descent.
Advantages of Stochastic-Gradient-Descent:
- It is easier to allocate in desired memory.
- It is relatively fast to compute than batch gradient descent.
- It is more efficient for large datasets.
MiniBatch-Gradient-Descent
Mini Batch gradient descent is the combination of both batch and stochastic gradient descent. It divides the training datasets into small batch sizes then performs the updates on those batches separately. Splitting training datasets into smaller batches make a balance to maintain the computational efficiency of batch gradient descent and speed of stochastic gradient descent. Hence, we can achieve a special type of gradient descent with higher computational efficiency and less noisy.
Advantages of Mini Batch gradient descent:
- It is easier to fit in allocated memory.
- It is computationally efficient.
- It produces stable gradient descent convergence.
Tips
- Plot Cost versus Time: Collect and plot the cost values calculated by the algorithm each iteration. The expectation for a well performing gradient descent run is a decrease in cost each iteration. If it does not decrease, try reducing your learning rate.
- Learning Rate: The learning rate value is a small real value such as 0.1, 0.001 or 0.0001. Try different values for your problem and see which works best.
- Rescale Inputs: The algorithm will reach the minimum cost faster if the shape of the cost function is not skewed and distorted. You can achieved this by rescaling all of the input variables (X) to the same range, such as [0, 1] or [-1, 1].
- Few Passes: Stochastic gradient descent often does not need more than 1-to-10 passes through the training dataset to converge on good or good enough coefficients.
- Plot Mean Cost: The updates for each training dataset instance can result in a noisy plot of cost over time when using stochastic gradient descent. Taking the average over 10, 100, or 1000 updates can give you a better idea of the learning trend for the algorithm.
In this post you learned that:
- Optimization is a big part of machine learning.
- Gradient descent is a simple optimization procedure that you can use with many machine learning algorithms.
- Batch refers to calculating the derivative from all training data before calculating an update.
- Stochastic refers to calculating the derivative from each training data instance and calculating the update immediately.
- MiniBatch is the combination of both batch gradient descent and stochastic gradient descent.
Recommended for you:
Algorithms

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained