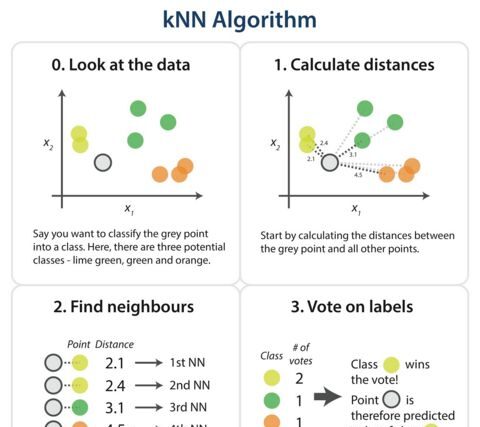
How K-Nearest Neighbors works ?
The K-Nearest Neighbors algorithm, also known as KNN or K-NN, is a non-parametric, supervised learning classifier, which uses proximity to make predictions about the grouping of an individual data point. While it can be used for either regression or classification problems, it is typically used as a classification algorithm, working off the assumption that similar points can be found near one another. For classification problems, a class label is assigned on the basis of a majority vote.
The label that is most frequently represented around a given data point is used. While this is technically considered plurality voting, the term, majority vote is more commonly used in literature. The distinction between these terminologies is that majority voting technically requires a majority of greater than 50%, which primarily works when there are only two categories. When you have multiple classes e.g. four categories, you don’t necessarily need 50% of the vote to make a conclusion about a class; you could assign a class label with a vote of greater than 25%.
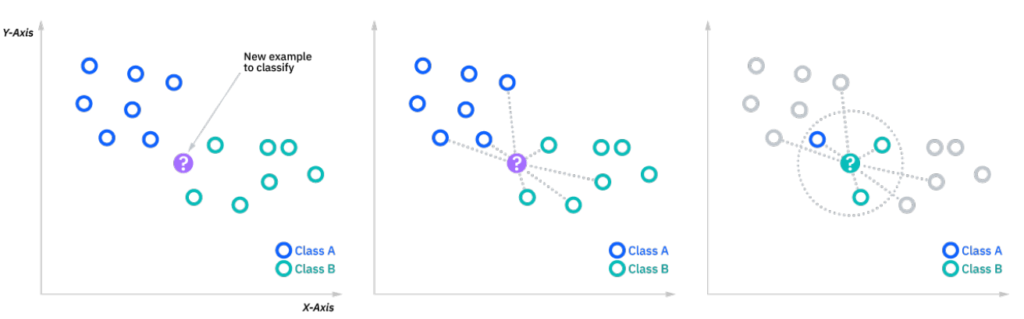
To recap, the goal of the K-Nearest Neighbor algorithm is to identify the nearest neighbors of a given query point, so that we can assign a class label to that point. In order to do this, KNN has a few requirements.
Determine your Distance Metrics
In order to determine which data points are closest to a given query point, the distance between the query point and the other data points will need to be calculated. These distance metrics help to form decision boundaries, which partitions query points into different regions. You commonly will see decision boundaries visualized with Voronoi diagrams. While there are several distance measures that you can choose from, this article will cover the following.
Euclidean distance (p=2): This is the most commonly used distance measure, and it is limited to real-valued vectors. Using the below formula, it measures a straight line between the query point and the other point being measured.
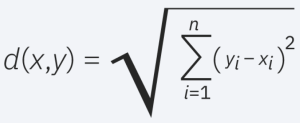
Manhattan distance (p=1): This is also another popular distance metric, which measures the absolute value between two points. It is also referred to as taxicab distance or city block distance as it is commonly visualized with a grid, illustrating how one might navigate from one address to another via city streets.
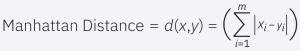
Minkowski distance: This distance measure is the generalized form of Euclidean and Manhattan distance metrics. The parameter, p, in the formula below, allows for the creation of other distance metrics. Euclidean distance is represented by this formula when p is equal to two, and Manhattan distance is denoted with p equal to one.

Hamming distance: This technique is used typically used with Boolean or string vectors, identifying the points where the vectors do not match. As a result, it has also been referred to as the overlap metric. This can be represented with the following formula.
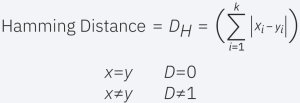
The Optimal Value of K
The K value in the KNN algorithm defines how many neighbors will be checked to determine the classification of a specific query point. For example, if k=1, the instance will be assigned to the same class as its single nearest neighbor. Defining K can be a balancing act as different values can lead to overfitting or underfitting. Lower values of K can have high variance, but low bias, and larger values of K may lead to high bias and lower variance.
The choice of K depend on the input data as data with more outliers or noise will likely perform better with higher values of K.
Overall, it is recommended to have an odd number for K to avoid ties in classification, and cross-validation tactics can help you choose the optimal K for your dataset.
A very low value for K such as K=1 or K=2, can be noisy and lead to the effects of outliers in the model. On the other hand, large values for K may lead to some difficulties.
Another technique to get the optimal value of K is to use the Autooptimizer Package. Using combined techniques of Exhaustive Search and Autotuning , the library obtains the best possible K value based on the dataset.
Advantages of KNN Algorithm
- It is a simple algorithm to implement.
- It is robust to the noisy data.
- It can be more effective if the data is large.
Disadvantages of KNN Algorithm
- Always KNN needs to determine the value of K which may be complex some time.
- The computation cost is high because of calculating the distance between the data points for all the samples.
Applications of K-Nearest Neighbors
K-Nearest Neighbors algorithm has been utilized within a variety of applications, largely within classification. Some of these use cases include:
Data preprocessing: Datasets frequently have missing values, but the KNN algorithm can estimate for those values in a process known as missing data imputation.
Recommendation Engines:
Using clickstream data from websites, the KNN algorithm has been used to provide automatic recommendations to users on additional content. This research shows that the a user is assigned to a particular group, and based on that group’s user behavior, they are given a recommendation.
Finance:
It has also been used in a variety of finance and economic use cases. It is used to determine the credit-worthiness of a loan applicant. Another KNN use in stock market forecasting, currency exchange rates, trading futures, and money laundering analyses.
Healthcare:
KNN has also application within the healthcare industry, making predictions on the risk of heart attacks and cancer. The algorithm works by calculating the most likely gene expressions.
Pattern Recognition:
KNN has also assisted in identifying patterns, such as in text and digit classification. This is particularly helpful in identifying handwritten numbers that you might find on forms or mailing envelopes.
K-Nearest Neighbors Algorithm Infographic

Recommended for you:
K-Mean Clustering Algorithm
Logistic Regression


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained