
K-Means Clustering is an unsupervised learning algorithm. It is a simple and elegant approach used to solve the clustering problems in machine learning.
What is Clustering?
Clustering is the task of segmenting a set of data into distinct groups such that the data points in the same group will bear similar characteristics as opposed to those data points which lie in the groups/clusters. Our main objective here is to segregate groups having similar characteristics assign them unique clusters.
- The points present in the same cluster should have similar properties
- The points present in the different clusters should be as dissimilar as possible
What is K-Means Algorithm?
K-Means Clustering comes under the category of Unsupervised Machine Learning algorithms, these algorithms group an unlabeled dataset into distinct clusters. The K defines the number of pre-defined clusters that need to be created, for instance, if K=2, there will be 2 clusters, similarly for K=3, there will be three clusters. The primary goal while implementing k-means involves defining k clusters such that total within-cluster variation (or error) is minimum.
The cluster center is the arithmetic mean of all the data points that belong to that cluster. The squared distance between every given point and its cluster center is called variation. The goal of the k-means clustering is to ascertain these k clusters and their centers whilst reducing the total error.
The K Means Algorithm is:
- Choose a number of clusters “K”.
- Randomly assign each point to Cluster.
- Until cluster stop changing, repeat the following.
- For each cluster, compute the centroid of the cluster by taking the mean vector of the points in the cluster.
- Assign each data point to the cluster for which the centroid is closest.
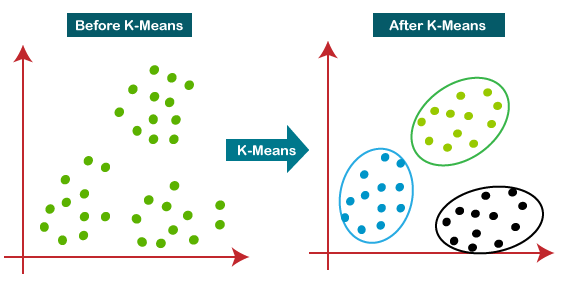
K-Means clustering algorithm performs two tasks:
Determines the best value for K center points or centroids by an iterative process.
Assigns each data point to its closest k-center. Those data points which are near to the particular k-center, create a cluster.
Hence each cluster has datapoints with some commonalities, and it is away from other clusters.
The below diagram explains the working of the K-Means Clustering Algorithm:
Finding the optimal value of K
K is a hyperparameter of the K-Means Algorithm. In most cases, the number of clusters is determined in a heuristic fashion. Most strategies involve running K-Means with different K-values and finding the best value using some criterion like the elbow method.
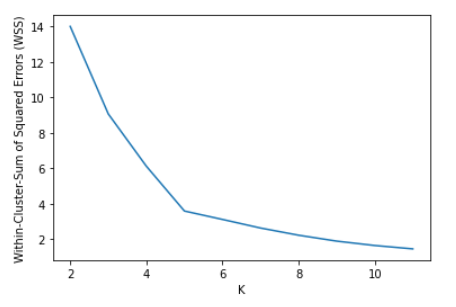
The Elbow Method is a popular technique for determining the optimal number of clusters. Here, we calculate the Within-Cluster-Sum of Squared Errors (WCSS) for various values of k and choose the k for which WSS first starts to diminish. In the plot of WSS-versus-k, this can be observed as an elbow.
- The Squared Error for a data point is the square of the distance of a point from its cluster center.
- The WSS score is the summation of Squared Errors for all given data points.
- Distance metrics like Euclidean Distance or the Manhattan Distance can be used.
We calculate the WCSS for K=2 to 12 and calculate the WCSS in each iteration. We plot the WCSS vs K cluster graph. It can be seen below that there is an elbow bend at K=5 i.e. it is the point after which WCSS does not diminish much with the increase in value of K.
Another and better approach is use AutoOptimizer package.
AutoOptimizer package provides tools to automatically optimize machine learning model for a dataset with very little user intervention. It allow engineers to discover a good predictive model for their machine learning algorithm task quickly, with very little intervention other than providing a dataset. AutoOptimizer uses Exhaustive Search Mechanism with Hyperparameter Tuning for optimizing machine learning models.
Why K-Means Algorithm ?
K-Means clustering algorithm is deployed to discover groups that haven’t been explicitly labeled within the data. It’s being actively used today in a wide variety of applications including:
- Customer segmentation:
- Customers can be grouped in order to better tailor products and offerings.
- Text clustering:
- grouping to find topics in text.
- Image grouping: groups similar in images or colors.
- Anomaly detection:
- finds what isn’t similar, or the outliers from clusters
- Semi-supervised learning:
- clusters are combined with a smaller set of labeled data and supervised machine learning in order to get more valuable results.
Advantages of K-Means Clustering Algorithm
- It is fast and robust.
- Easy to understand and interpret.
- Comparatively efficient.
- If data sets are distinct, then gives the best results.
- Produce tighter clusters.
- Flexible (when centroids are recomputed, the cluster changes).
- Better computational cost.
- Enhances Accuracy.
- Works better with spherical clusters.
Disadvantages of K-Means Clustering Algorithm
- Needs prior specification for the number of cluster.
- incompatible with overlapping data.
- With the different representations of the data, the results achieved are also different.
- Euclidean distance can unequally weigh the factors.
- It gives the local optima of the squared error function.
- It can be used only if the meaning is defined.
- Cannot handle outliers and noisy data.
- Does’t work with the non-linear data set.
- Lacks consistency.
- Sensitive to scale.
K-Means Infographic
Recommended to you:


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained