
As one of the important topics in machine learning, loss function plays an important role in the construction of machine learning models. which has been concerned and explored by many researchers.
Loss functions serve as indicators of how far the model’s predictions deviate from the correct answers.
What is Loss Function?
Loss function also called Error function is a mathematical function of the parameters of machine learning algorithm. It is the method of evaluating how well specific algorithm models your data. This evaluation of the gap informs the model about the extent of adjustments needed in parameters, such as weights or coefficients, to more accurately capture the underlying patterns in the data.
If predictions deviate too much from actual results, loss function would cough up a very large number. Gradually, with the help of some optimization function, loss function learns to reduce the error in prediction.
Generally, depending upon the type of learning method loss functions can be classified into two major categories, Regression losses and Classification losses. In classification, we are trying to predict output from categorical values. Regression deals with predicting a continuous value.
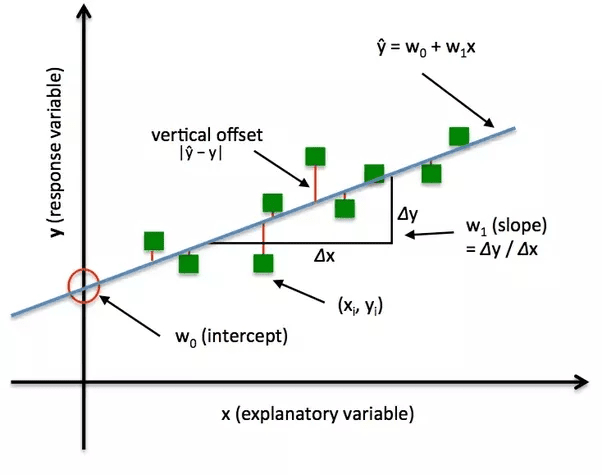
Types of Loss Functions
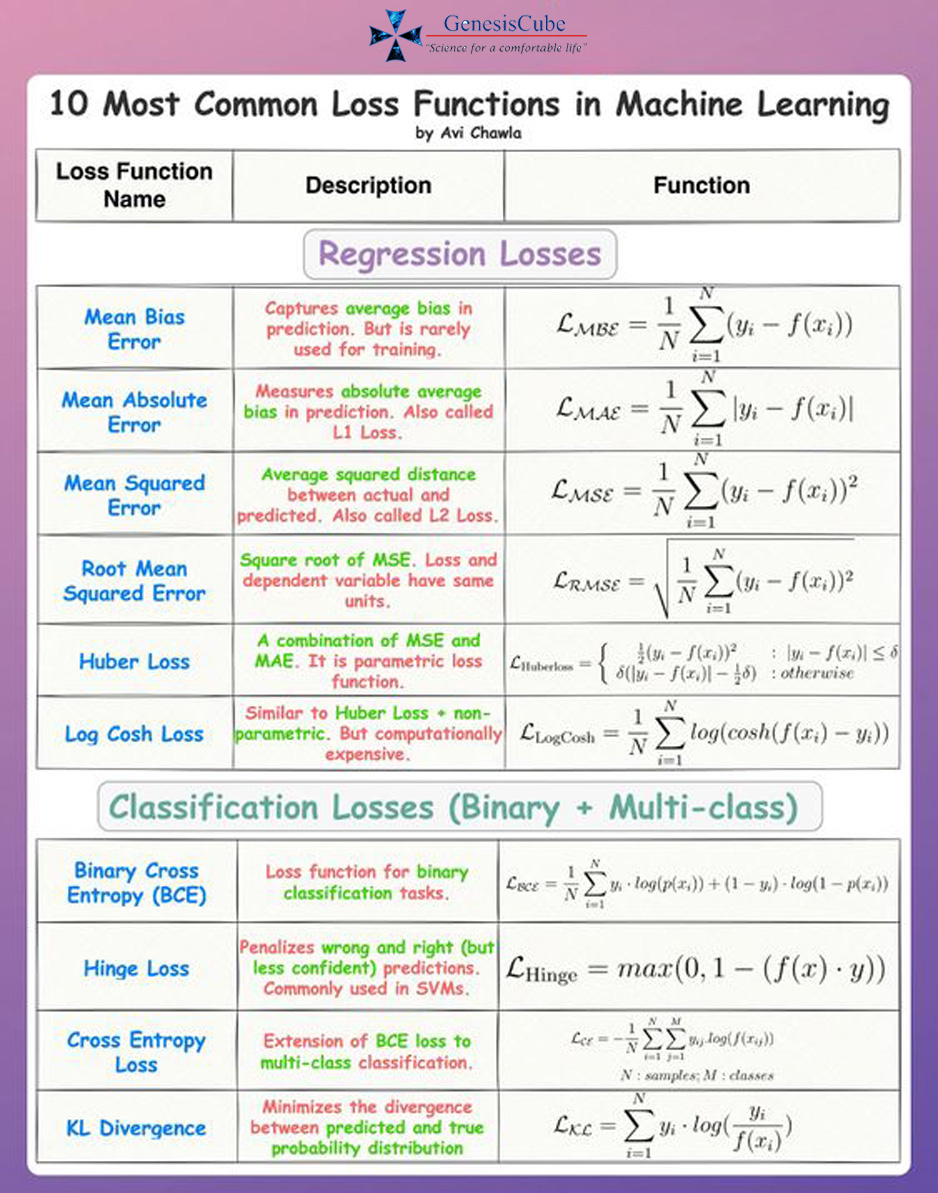
Mean Squared Error
Mean squared error (MSE) loss function is the sum of squared differences between the entries in the prediction value and the truth value. To calculate the MSE, you take the difference between the actual value and model prediction, square it, and average it across the whole dataset.
Mean Absolute Error
Mean Absolute Error (MAE) is also the simplest loss function. To calculate the mean absolute error, you take the difference between the actual value and model prediction value and average it across the whole dataset.
Binary Cross Entropy
It is used in binary classification. For example, a person has pain or not. To know, how predictions close or far from the actual value. It compares each of the predicted to the actual class output which can be either 0 or 1. Then calculates the score that penalizes the probabilities based on the distance from the expected value.
Likelihood Loss
Likelihood function is also relatively simple, and commonly used in classification problems. The function takes the predicted probability for each input example and multiplies them. Although the output isn’t interpretable, but it’s useful for comparing models.
Log Loss
Log Loss is a performance measure for classification models that outputs a prediction with a probability value typically between 0 and 1, and this prediction value corresponds to the likelihood of a data sample belonging to a class or category. It’s just a straightforward modification of the likelihood function with logarithms. This is exactly the same formula as the regular likelihood function with logarithms added in. In log loss we just end up multiplying the log of the actual predicted probability for the ground truth class.
Mean Bias Error
This is much less common in machine learning. This is same as mean squared error with the only difference that we don’t take absolute values. Although less accurate in practice, it could determine if the model has positive bias or negative bias.
SVM Loss
In simple words, the score of correct category should be greater than sum of scores of all incorrect categories by some safety margin. And hence hinge loss is used for maximum-margin classification, most notably for support vector machines. Although it is not differentiable, it’s a convex function which makes it easy to work with usual convex optimizers used in machine learning.
Hinge Loss
It is a loss function to train classifiers that optimize to increase the margin between datapoints and the decision boundary. Hence, it is mainly used for maximum margin classifications. To ensure the maximum margin between the datapoints and boundaries, hinge loss penalizes predictions from the model that are wrongly classified, which are predictions that fall on the wrong side of the margin boundary and also predictions that are correctly classified but are within close proximity to the decision boundary.
Hinge Loss function ensures machine learning models are able to predict the accurate classification of datapoints to target value with confidence that exceeds the threshold of the decision boundary.
Loss Function Infographic
Recommended for you:


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained