LSTM (Long Short-Term Memory) is a type of RNN (Recurrent Neural Network) that is widely used for learning sequential data prediction problems. LSTM also has some layers which help it to learn and recognize the patterns in data sets for better performance. Like any other RNN, LSTM has a chain structure with feedback loops, and If the current state of the neural network requires data that is not in the recent memory, then LSTM can learn the data from the past memory. That’s why LSTM networks are usually used to learn, process, and segregate sequential data. For example, it is widely used in speech recognition, machine translation, video analysis.
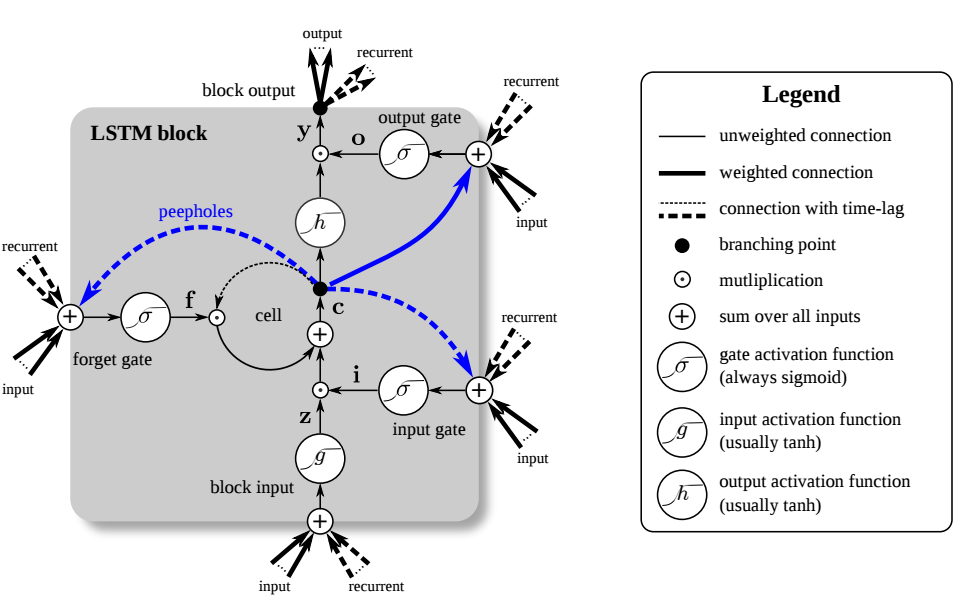
LSTM has persistent memory. It uses additional gates to learn long-term dependencies. The gates control the flow of information in the memory modules of neural networks.
LSTM can remember data for long periods, because of its remembering capacity. It identifies the data that is important and remembered for the long term from the incoming data. At the same time, LSTM eliminates the unimportant data from the incoming data.
This post help you to understand LSTM clearly.
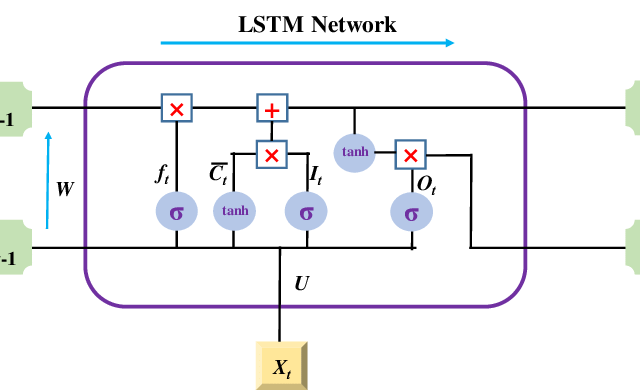
LSTM Architecture
To give a gentle introduction, LSTMs deal with both Long and Short Term Memory and for making the calculations simple and effective, it uses gates. That is a stack of neural networks composed of linear layers composed of weights and biases., and the weights are constantly updated by backpropagation.
Now, let me introduce a few crucial specific terms to you.
- Cell : Every unit of the LSTM network is known as a cell, and each cell is composed of 3 inputs and 2 outputs :
- x(t) : token at timestamp t.
- h(t−1): previous hidden state.
- c(t-1) : previous cell state.
- h(t) : updated hidden state, used for predicting the output.
- c(t) : current cell state.
- Gates : LSTM uses a mechanism of controlling the memorizing process. Popularly referred to as gating mechanism, what the gates in LSTM do is, store the memory components in analog format. and make it a probabilistic score by doing point-wise multiplication using sigmoid activation function, which stores it in the range of 0–1.
- Forget Gate:
- This gate decides whether to allow incoming information into the LSTM modules or remove it. When the output of the forget gate is 1, the input information is passed through the cell state. On the contrary, if the output is 0, the input information is removed from the cell state. In short, you can modify cell states with the help of this gate.
- Input Gate:
- This gate decides whether to allow new information in the cell state and store it in the memory cell. The ‘tanh layer’ associated with this input gate generates new candidate values. So, the output of the sigmoid function and candidate values are multiplied and added to the cell state.
- Output Gate:
- This gate decides which information to flow into the rest of the LSTM networks.
- Forget Gate:
Forget Gate
One of the main properties of the LSTM is to memorize and recognize the information coming inside the network and also to discard the information which is not required to the network to learn the data and predictions. This gate is responsible for this. It helps in deciding whether information can pass through the layers of the network. There are two types of input it expects from the network:
- one is the information from the previous layers.
- another one is the information from the presentation layer.
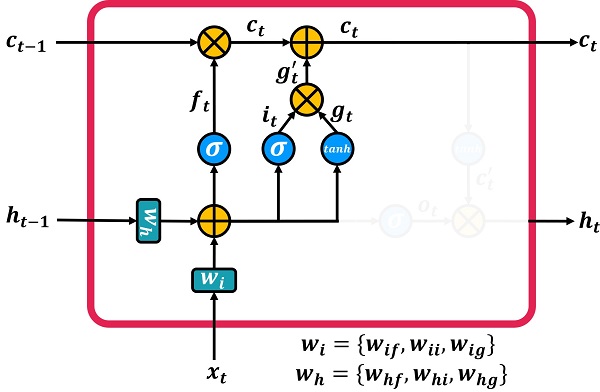
The structure of the forgetting gate is very similar to the internal structure of the recurrent neural network. This network has two inputs ‘xt’ and ‘ht-1’. These two inputs are combined and then passed through a sigmoid layer. The sigmoid layer generates a number between 0 and 1, which is multiplied by the input vector ‘Ct-1’. I repeat, ft is a vector, not a single scalar number. This vector is the size of ‘Ct-1’. Determines by what number from 0 to 1 each ‘Ct-1’ number should be multiplied. If any fraction of ft is close to 1, it means that this fraction of ‘Ct-1’ should be preserved. If it is close to 0, that means discard this portion of ‘Ct-1’.
But how are two input vectors ‘xt’ and ‘ht-1’ combined? Using the MLP neural network, it is enough to give these two vectors to two fully connected layers. Then add these two together. The formula and form of the forgetfulness gate is as follows:
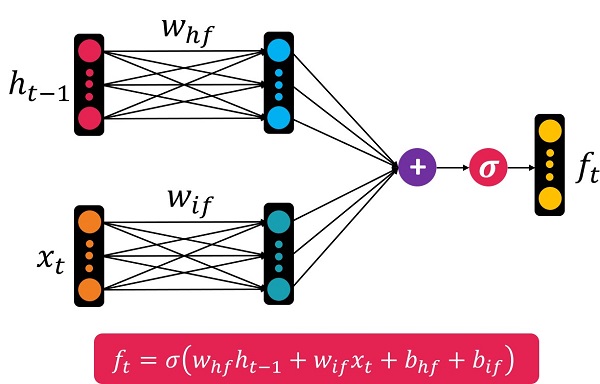
In the figure above, we have two fully connected layers with weights whf and wif. These two layers are for input ht-1 and xt respectively. hf index stands for hidden and forget. The if index stands for input and forget.
Forgetting in LSTM network
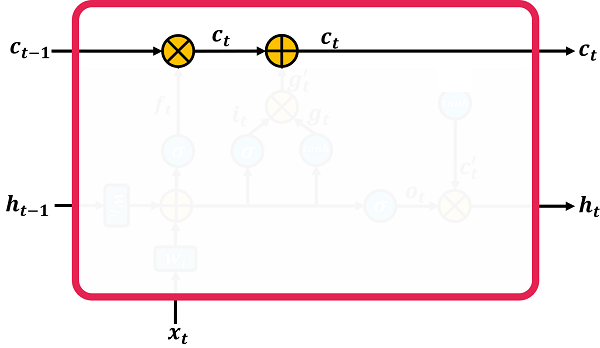
Look at the ‘x’ on the long-term memory line in the figure below. This operator has two inputs, one of which is ‘Ct-1’. The second is an input. But, the input passes through a sigmoid function before being applied. This sigmoid function causes the output to be a number between 0 and 1. Note that, both inputs are vectors of the same length that are multiplied step by step and produce a vector as output.
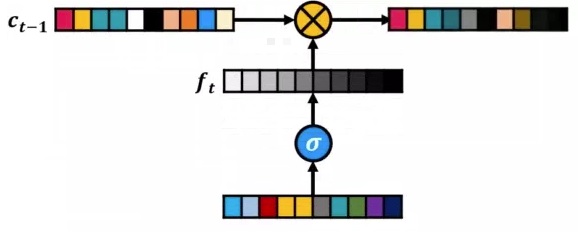
Now, what do you think the output of operator ‘x’ has? Is the output the same as ‘Ct-1’ with the slight changes that the ft input makes on it? These changes may be as follows:
If any branch of ‘ft’ is 0, it means that it does not allow its corresponding branch in ‘Ct-1’ to go to the output. If any branch of ‘ft’ is 1, it means that all the input of ‘Ct-1’ goes to the output and remains untouched.
If it is a number between 0 and 1, it naturally affects the input to some extent. So this is how we can delete information from inside ‘Ct-1’.
But how is the ‘ft’ input formed? According to the figure below, this input is formed by a small neural network with two inputs ‘xt’ and ‘ht-1’. This small neural network has the task of forgetting part of the information in long-term memory. This neural network is called forget gate.

Inpute Gate
The input gate is an evaluator of the value of the information in the gt. The input gate checks the entry of a series of new information into the long-term memory. That’s why they named it inpute gate. Similar to the forget gate, the values in the it vector may be close to zero, thus reducing the effect of gt. Conversely, the values of the it vector may be close to 1, in which case gt goes to be stored in long-term memory. The structure of this gate is similar to the forgetting gate. Pay attention to the figure below; The input gate enters the two inputs ‘xt’ and ‘ht-1’ into two fully connected layers and then adds them together and finally passes the sigmoid function.
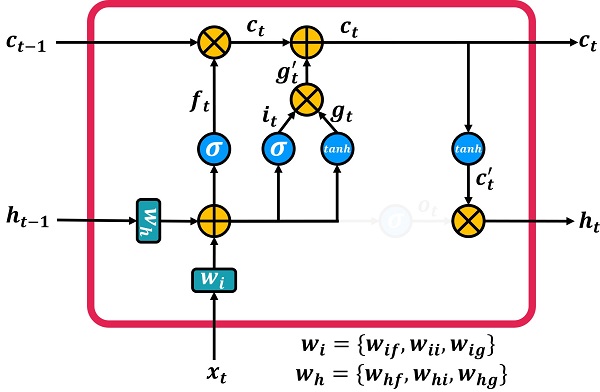
What does a recurrent LSTM network need to produce the output ht? So we pass the output Ct through a hyperbolic tangent, then we are ready to connect it to the output ht. It is shown in the figure below.
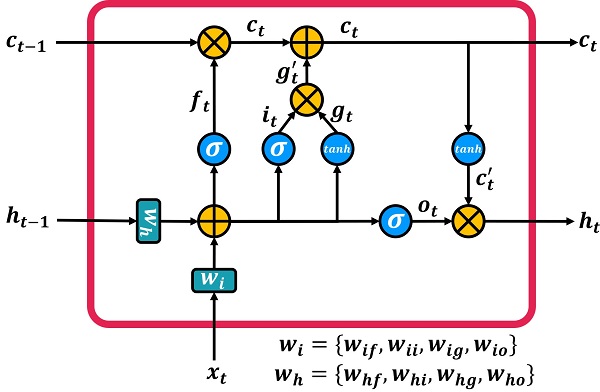
Output Gate
What happens in the output gate?
The output gate enters the two inputs ‘xt’ and ‘ht-1’ into the two fully connected layers and adds them together and finally passes the sigmoid function.
Finally, the output generated from the output gate ‘ot’ must be multiplied by the output of the sigmoid function to transfer as much as needed to the output ‘ht’.
Recommended for you:
Recurrent Neural Network
Deep Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained