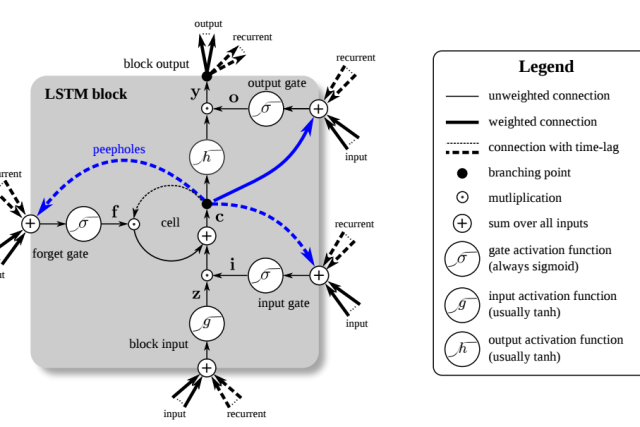
LSTM is one of the Recurrent Neural Networks used to efficiently learn long-term dependencies. LSTM modules consist of gate layers that act as key drivers to control information in neural networks.
What is Recurrent Neural Network?
Recurrent Neural Networks are the type of Artificial Neural Networks that consists of feedback loops. RNNs effectively process sequential data. RNNs have multiple neural networks or modules connected in their basic form. Each module in an RNN has a single ‘tanh’ layer.
When it comes to training data, RNNs, Feed Forward as well as Convolutional Neural Networks function similarly. But at the same time, they differ at one point – memory. Unlike Convolutional Neural Networks and Feed-forward NNs, the previous inputs impact the current input and output of RNN.
Recurrent Neural Networks are widely used in deep learning, mainly in Natural Language Processing (NLP) and speech recognition.
Although RNNs come with feedback loops to remember information, they are inefficient in learning long-term dependencies. This is because RNNs face gradient vanishing and gradient exploding problems. Gradients are nothing but errors that occur while training input data. The gradients drive the weighs of RNNs to become either too small or big.
Gradient vanishing doesn’t allow RNNs to learn from training data, mainly when the data is too complex. Simply put, RNNs can process only close temporal events. If you want to process distant temporal events or long-term dependencies, you need neural networks with long-term memory cells.
What is LSTM?
A Long short-term memory also known as LSTM is one of the Recurrent Neural Networks used to efficiently learn long-term dependencies. LSTM modules consist of gate layers that act as key drivers to control information in neural networks.
We can use Recurrent Neural Networks to overcome the setback of feed-forward networks because RNNs are built with feedback loops. Generally, feedback loops remember information, which eases neural networks to process sequential data.
But Recurrent Neural Networks is not efficient in managing long-term dependencies in memory. LSTM is the type of RNN that helps to overcome this setback of RNNs and efficiently processes the sequential data by effectively managing long-term dependencies.
LSTMs due to their ability to learn long term dependencies are applicable to a number of sequence learning problems including language modeling and translation, acoustic modeling of speech, speech synthesis, audio and video data analysis, handwriting recognition and generation, sequence prediction, and protein secondary structure prediction.
Long Short-Term Memory Architecture
The LSTM Architecture consists of linear units with a self-connection having a constant weight of 1.0. This allows a value (forward pass) or gradient (backward pass) that flows into this self-recurrent unit to be preserved and subsequently retrieved at the required time step. With the unit multiplier, the output or error of the previous time step is the same as the output for the next time step. This self-recurrent unit, the memory cell, is capable of storing information which lies dozens of time-steps in the past. This is very powerful for many tasks.
For example, for text data, an LSTM unit can store information contained in the previous paragraph and apply this information to a sentence in the current paragraph.
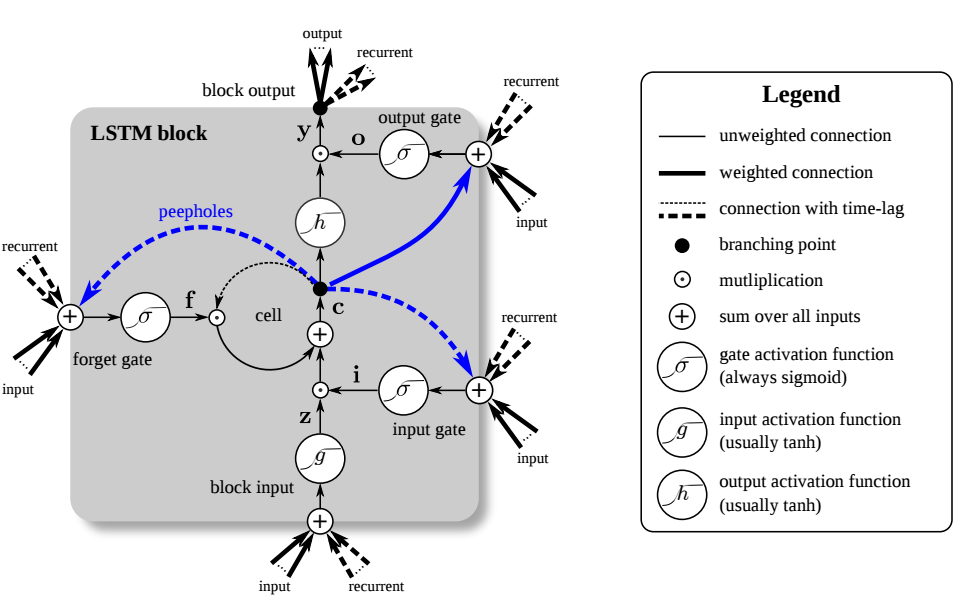
Bidirectional LSTMs train the input sequence on two LSTMs – one on the regular input sequence and the other on the reversed input sequence. This can improve LSTM network performance by allowing future data to provide context for past data in a time series.
These LSTM networks can better address complex sequence learning than simple feed-forward networks.
How does LSTM work?
The memory cell and the three gates play a vital role in the function of LSTM networks.
- Forget Gate
- This gate decides whether to allow incoming information into the LSTM modules or remove it. In other words, forget gate decides which information must be passed through the cell state and which information must be removed from the cell state.
- When the output of the forget gate is 1, the input information is ultimately passed through the cell state. On the contrary, if the output is 0, the input information is removed from the cell state. you can modify cell states with the help of this gate.
- Input Gate
- This gate decides whether to allow new information in the cell state and store it in the memory cell. The ‘tanh layer’ associated with this input gate generates new candidate values. So, the output of the sigmoid function and candidate values are multiplied and added to the cell state.
- Output Gate
- The cell state is given through this stage’s ‘tanh’ layer. Then it multiplied with the output of the sigmoid function. As a result, the part of the cell state that must be outputted from the LSTM module is decided. This is how the cell state is filtered before releasing the output from this gate. This gate decides which information to flow into the rest of the LSTM networks.
What are the Types of LSTM Networks?
- Vanilla LSTM
- It has a single hidden layer and an output layer in LSTM modules to make predictions.
- Stacked LSTM
- In this type, multiple hidden layers are stacked one on another in the LSTM Modules and the sequential output of one LSTM hidden layer is passed into the following LSTM hidden layer.
- CNN LSTM
- It is the LSTM model that processes two-dimensional image data efficiently.
- ConvLSTM
- A fully-connected LSTM model has the drawback of redundancy in spatial data. ConvISTM uses a convolution operator to predict the future state of two-dimensional spatial data by reducing the redundancy in spatial data. Each LSTM module in the network can convolute the input data seamlessly.
What is Bidirectional LSTM?
In a typical LSTM network, input information flows in one direction – either forward or backward. But, in bidirectional LSTM, information can flow in both forward as well as backward directions. The information flows in the backward direction only because of the additional layer in the bidirectional LSTM.
The outputs of both the forward as well as backward layers are combined together through the processes such as sum, multiplication, average, etc.
It is undoubtedly a powerful LSTM model that can effectively handle long-term dependencies of sequential data, such as words and phrases in both directions.
Bidirectional LSTM is used in text classification, forecasting models, speech recognition, and language processing. It is also used in NLP tasks such as sentence classification, entity recognition, translation, and handwriting recognition.
Vanishing Gradient Problem in LSTM
A simple LSTM model only has a single hidden LSTM layer while a stacked LSTM model has multiple LSTM hidden layers. A common problem in deep networks is the “vanishing gradient” problem, where the gradient gets smaller and smaller with each layer until it is too small to affect the deepest layers. With the memory cell in LSTMs, we have continuous gradient flow (errors maintain their value) which thus eliminates the vanishing gradient problem and enables learning from sequences which are hundreds of time steps long.
Accelerating Long Short-Term Memory using GPUs
The parallel processing capabilities of GPUs can accelerate the LSTM training and inference processes. GPUs are the de-facto standard for LSTM usage and deliver a 6x speedup during training and 140x higher throughput during inference when compared to CPU implementations. cuDNN is a GPU-accelerated deep neural network library that supports training of LSTM recurrent neural networks for sequence learning. TensorRT is a deep learning model optimizer and runtime that supports inference of LSTM recurrent neural networks on GPUs.
Recommended for you:
Text Mining Algorithms
Recurrent Neural Network
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained