Machine Learning
Machine learning is the process of employing an algorithm to learn from past data and generalise it to make predictions about future data. Here, an optimization technique is used to generate parameter values that minimise the function’s error when used to map the inputs to outputs. In this post, we will discover the central role of optimization in machine learning.
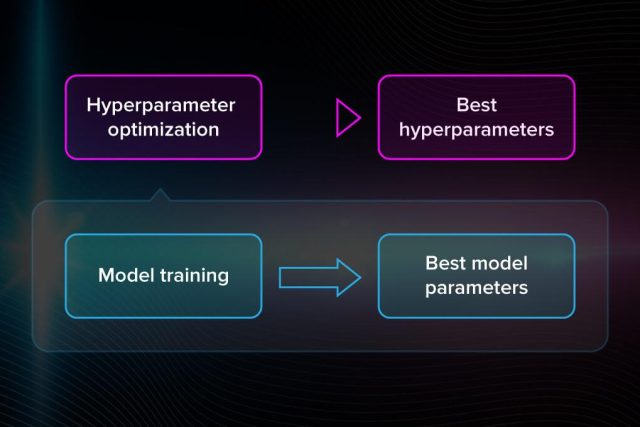
Parameters and hyperparameters of the model
Difference between parameters and hyperparameters of a model:
- You need to set hyperparameters before starting to train the model. They include a number of clusters, learning rate, etc. Hyperparameters describe the structure of the model.
- The parameters of the model are obtained during the training. There is no way to get them in advance. Examples are weights and biases for neural networks. This data is internal to the model and changes based on the inputs.
Machine Learning and Optimization
Machine learning optimization is the process of adjusting hyperparameters in order to minimize the cost function. It is important to minimize the cost function because it describes the discrepancy between the true value of the estimated parameter and what the model has predicted.
Finding a set of inputs to an objective goal function that results in the function’s minimum or maximum is known as “function optimization.”
Function Optimization: Finding the collection of inputs that results in the minimum or maximum of the objective function is known as function optimization. Function approximation is a good way to describe machine learning. This means approximating an unknown basis function that maps examples of inputs to outputs to predict new data.
Approximation of Functions: Generalizing from specific examples to a reusable mapping function for making predictions on new examples. Optimizing functions is often easier than approximating functions.
In addition, the process of working on a predictive modeling problem involves optimization in several steps in addition to learning the model, including:
- Selection of model hyperparameters.
- Selection of transformations to apply to data before modeling
- Selecting a modeling pipeline to use as the final model.
How hyperparameter tuning works
As we said, the hyperparameters are set before training. But you can’t know in advance, for instance, which learning rate is best in this or that case. Therefore, to improve the model’s performance, hyperparameters have to be optimized.
After each iteration, you compare the output with expected results, assess the accuracy, and adjust the hyperparameters if necessary. This is a repeated process and you can do that manually or use one of the many optimization techniques, which come in handy when you work with large amounts of data.
Optimization Techniques in Machine Learning
Exhaustive search
Exhaustive search is the process of looking for the most optimal hyperparameters by checking whether each candidate is a good match. In machine learning, we do the same thing but the number of options is quite large and try out all the possible options.
The exhaustive search method is simple. For example, if you are working with a k-means algorithm, you will manually search for the right number of clusters. However, if there are hundreds and thousands of options that you have to consider, it becomes unbearably heavy and slow.
Gradient descent
This technique involves updating the variables iteratively in the direction (opposite of) the gradients of the objective function. This approach helps the model locate the target at each update and gradually approaches the objective function’s ideal value.
In order to perform gradient descent, you have to iterate over the training dataset while re-adjusting the model. Your goal is to minimize the cost function because it means you get the smallest possible error and improve the accuracy of the model.
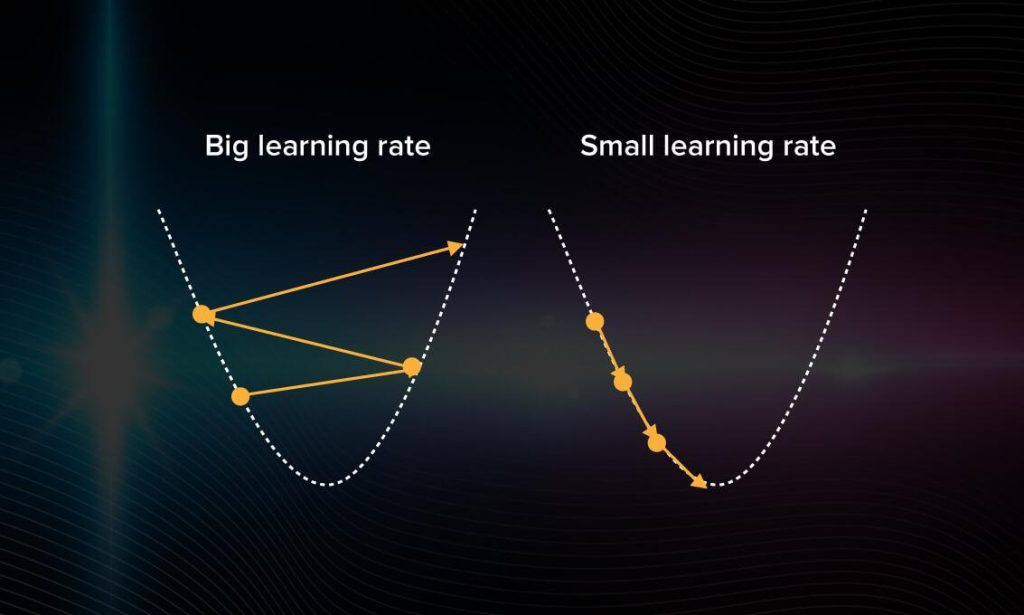
In gradient descent, you proceed forward with steps of the same size. If you choose a learning rate that is too large, the algorithm will be jumping around without getting closer to the right answer. If it’s too small, the computation will start mimicking exhaustive search take, which is, of course, inefficient.
Stochastic gradient descent
To solve the computational difficulty inherent in each iteration for large scale data, stochastic gradient descent was developed. Backpropagation is called taking values and iteratively adjusting them based on various parameters to reduce the loss function.
Instead of determining the gradient’s precise value directly, this method updates the gradient using one sample chosen at random for each cycle. An unbiased estimation of the true gradient is provided by the stochastic gradient. This optimization technique eliminates some computational duplication while reducing the update time for working with several samples.
Genetic algorithms
The principle that lays behind the logic of Genetic algorithms is an attempt to apply the theory of evolution to machine learning.
In the evolution theory, only those specimens get to survive and reproduce that have the best adaptation mechanisms. How do you know what specimens are and aren’t the best in the case of machine learning models?
Imagine you have a bunch of random algorithms at hand. This will be your population. Among multiple models with some predefined hyperparameters, some are better adjusted than the others. First, you calculate the accuracy of each model. Then, you keep only those that worked out best. Now you can generate some descendants with similar hyperparameters to the best models to get a second generation of models.
Optimization without derivatives
Derivative free optimization Instead of systematically determining answers uses a heuristic algorithm to choose approaches that have previously been successful. Particle swarm optimization, genetic algorithms, and traditional simulated annealing math are a few examples.
Zero order optimization
Zero order optimization was recently introduced to address the shortcomings of derivative free optimization. Derivative free optimization methods are challenging to scale to significant problems and suffer from a lack of convergence rate analysis.
A momentum based optimizer
It is an adaptive optimization algorithm that exponentially uses weighted average gradients over previous iterations to stabilize convergence, resulting in faster optimization. This is done by adding a fraction (gamma) to the values of the previous iteration. Essentially, the momentum term increases when the gradient points are in the same direction and decreases when the gradients fluctuate. As a result, the value of the loss function converges faster than expected.
Recommended for you:
AutoOptimizer Package GenesisCube
Machine Learning Model Optimization
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained