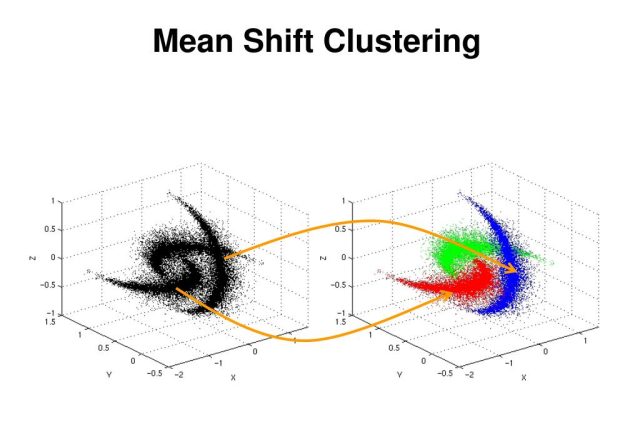
What is Clustering?
A cluster is often an area of density in the feature space where examples from the domain (observations or rows of data) are closer to the cluster than other clusters. The cluster may have a center (the centroid) that is a sample or a point feature space and may have a boundary or extent.
Clustering can also be useful as a type of feature engineering, where existing and new examples can be mapped and labeled as belonging to one of the identified clusters in the data.
What is Meanshift?
Mean Shift Algorithm is one of the clustering algorithms that is associated with the highest density points or mode value as the primary parameter for developing machine learning. The algorithm works on the concept of Kernel Density Estimation known as KDE. It is also known as mode seeking algorithm. The Kernel is associated with mathematical computation related to weightage to the data points. There are mainly two popular kernel functions associated with the mean Shift Algorithm such as the flat kernel and Gaussian Kernel.
- MeanShift assigns the data points to the clusters in a way by shifting the data points towards the high-density region. The highest density of data points is termed as the model in the region. It has applications widely used in the field of computer vision and image segmentation.
- KDE is a method to estimate the distribution of the data points. It works by placing a kernel on each data point. The kernel in math term is a weighting function that will apply weights for individual data points. Adding all the individual kernel generates the probability.
The Kernel Function
The weight function is called a kernel.
- The first requirement is to ensure the kernel density estimate is Normalized.
- The second requirement is that KDE is well associated with the symmetry of space.
Two Popular Kernel Functions used in it are:
- Flat Kernel
- If no kernel parameter is mentioned, Gaussian Kernel is invoked by default. KDE utilizes the concept of probability density function which helps to find the local maxima of the data distribution. The algorithm works by making the data points to attract each other allowing the data points towards the area of high density.
- Gaussian Kernel
In contrast to the K-Means clustering algorithm, the output of the Mean Shift algorithm does not depend on assumptions on the shape of the data point and the number of clusters. The number of clusters will be determined by the algorithm with respect to data.
Kernel Density Estimation
Mean shift is based on the concept of Kernel Density Estimation (KDE), which is a way to estimate the probability density function of a random variable. KDE is a problem where the inferences of the population are made by data smoothing. It works by providing weights to each data point. Adding all those kernels together creates a density function. The resultant density function variation depends on the used bandwidth parameter.
Mean shift is based on the idea of KDE, but what makes it different is that using the bandwidth parameter.
Bandwidth Parameter
The bandwidth parameter used to make the KDE surface varies on the different sizes. we have a tall skinny kernel which means a small kernel bandwidth and in a case where the size of the kernel is short and fat, which means a large kernel bandwidth.
A small kernel bandwidth makes the KDE surface hold the peak for every data point more formally, saying each point has its cluster; on the other hand, large kernel bandwidth results in fewer kernels or fewer clusters.
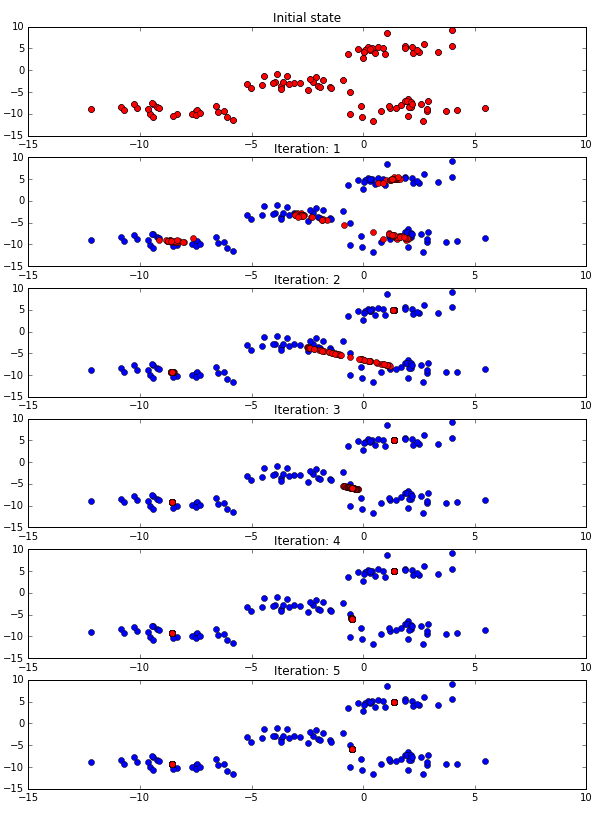
Working of Mean Shift Algorithm
- First, start with the data points assigned to a cluster of their own.
- Next, this algorithm will compute the centroids.
- In this step, location of new centroids will be updated.
- Now, the process will be iterated and moved to the higher density region.
- At last, it will be stopped once the centroids reach at position from where it cannot move further.
We prove for discrete data the convergence of a recursive mean shift procedure to the nearest stationary point of the underlying density function and thus its utility in detecting the modes of the density.
Meanshift Diagram
Advantages and Disadvantages
Advantages
- It does not need to make any model assumption.
- It can also model the complex clusters which have nonconvex shape.
- It only needs one parameter named bandwidth which automatically determines the number of clusters.
- There is no issue of local minima.
- No problem generated from outliers.
Disadvantages
- Mean shift algorithm does not work well in case of high dimension, where number of clusters changes abruptly.
- We do not have any direct control on the number of clusters but in some applications, we need a specific number of clusters.
- It cannot differentiate between meaningful and meaningless modes.
Recommended for you:
K-Mean Clustering Algorithm

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained