
Performance of a machine learning model depends on training dataset, algorithm, and the hyperparameters of the algorithm.
Many techniques such as exhaustive search are required to find the best performing algorithm and hyperparameters. Meta learning approaches help find these and optimize the number of experiments. This results in better predictions in a shorter time.
What is Meta Learning?
In the context of machine learning, meta learning also known as “learning to learn” refers to the application of machine learning algorithms for the optimization and training of machine learning models.
As meta learning becomes more favored and new approaches of meta learning are established, it’s vital to have a comprehension of how it may be used. Meta learning helps researchers understand which algorithms generate the best or better predictions from datasets.
Meta learning algorithms make better predictions by taking the outputs and metadata of machine learning algorithms as input. And provide information about the performance of these learning algorithms as output.
It is the capability to learn to perform a variety of complex tasks by applying the concepts it learned for one task to other activities.
It can be used for different machine learning models (e.g., reinforcement learning, natural language processing, etc.).
Developing these methodologies can aid Machine Learning and Artificial Intelligence in generalizing learning processes and gaining new skills more quickly.
How does Meta Learning work?
It is carried out in a variety of ways, depending on the type of the task.
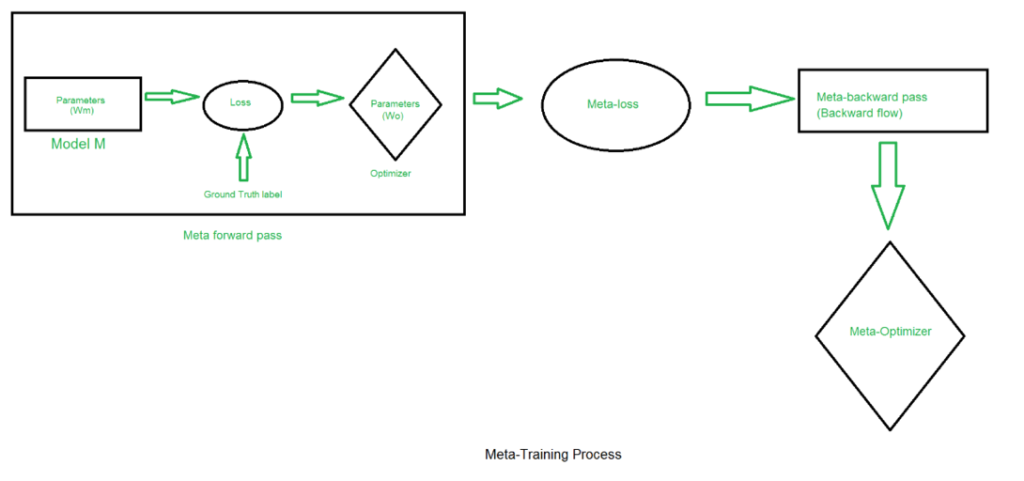
In meta learning, there are two training processes. After multiple steps of training on the base model have been completed, the meta model is typically trained. The forward training pass for the optimization model is performed after the forward, backward, and optimization phases that train the base model.
Learning
- Tasks
- Exposure to a range of tasks, each with its own set of parameters and characteristics, is part of the meta training process.
- Model Training
- Many tasks are used to train a base model, also known as a learner. The purpose of this model is to represent shared knowledge or common patterns among various tasks.
- Adaption
- The model is trained with few examples to quickly adjust its parameters to new tasks.
Testing
- New Task
- The model is given a new task during the meta testing stage that it was not exposed to during training.
- Few Shots
- With only a small amount of data, the model is modified for the new task. In order to make this adaptation, the model’s parameters are frequently updated using the examples from the new task.
- Generalization
- The efficacy is evaluated by looking at how well the model quickly generalizes to the new task.
The input required for the meta learner will look like this:
- A set of known tasks.
- Configurations for the learning algorithms (hyperparameters, pipeline components, network architecture components).
- A set of evaluations for each configuration’s performance on each task, for example – accuracy.
Using this terminology, we can state what we want from our meta learner. Training on the data given above, we want to recommend optimal configurations for new tasks that come our way.
Types of Meta Learning
Optimizer
It is frequently used to improve the performance of a neural network that already exists. Optimizer approaches work by changing the hyperparameters of another neural network to improve the performance of the base neural network.
Metric Learning
It is similar to few shot learning in that the network is trained and taught the metric space using only a few samples. Additionally, it is applied across all domains, and networks that deviate from it are judged to be failing.
Recurrent Models
This technique that is applied to Long Short-Term Memory networks and Recurrent Neural Networks.
This method works by first training an LSTM model to learn a certain dataset and then using that model as a foundation for another learner. It takes into account the optimization strategy used for training the prime model. The meta-inherited learner’s parameterization allows it to fast initialize and converge while still being able to update for new circumstances.
Model Agnostic
In this method, the model is trained on a set of meta training tasks, which are similar to the target tasks but have a different distribution of data. The model learns a set of generalizable parameters that can be quickly adapted to new tasks with only a few examples by performing a few gradient descent steps.
Model-based
It is a well-known algorithm that learns how to initialize the model parameters correctly so that it can quickly adapt to new tasks with few examples.
It updates parameters rapidly with a few training steps and quickly adapts to new tasks by learning a set of common parameters. It could be a neural network with a certain architecture that is designed for fast updates, or it could be a more general optimization algorithm that can quickly adapt to new tasks.
The parameters of a model are trained such that even a few iterations of applying gradient descent with relatively few data samples from a new task can lead to good generalization on that task.
Meta Learning Optimization
During the training process of a machine learning algorithm, hyperparameters determine which parameters should be used. Optimizing hyperparameters may be done in several ways.
- Grid Search
- The Grid Search technique makes use of manually set hyperparameters. All suitable combinations of hyperparameter values are tested during a grid search. After that, the model selects the best hyperparameter value. But the process takes so long and is so ineffective.
- Random Search
- The optimal solution for the created model is found using the random search approach, which uses random combinations of the hyperparameters. Even though it has characteristics similar to grid search, it has been shown to produce superior results overall.
Advantages
- Optimizing hyperparameters to find best results.
- It can help reduce the number of hyperparameters that need to be tuned manually.
- helping learning algorithms better adapt to changes in conditions.
- Identifying clues to design better learning algorithms.
- Supporting learning from fewer examples. This reduces the amount of data you need in solving problems in the new context.
- Increasing the speed of learning processes by reducing necessary experiments.
- Its approaches can produce learning architectures that perform better and faster than hand-crafted models.
- It can frequently generalize to new tasks more effectively by learning to learn.
- It can automate the process of choosing and fine-tuning algorithms, thereby increasing the potential to scale AI applications.
- Help improve the performance of machine learning models by allowing them to adapt to different datasets and learning environments.
- By leveraging prior knowledge and experience, can quickly adapt to new situations and make better decisions.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Model Generalization in Machine Learning
Machine Learning Optimization Techniques

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained