
Before talking about model generalization in machine learning, it’s important to understand what supervised learning is.
With supervised learning, a dataset of labeled training data is given to a model. Based on this training dataset, the model learns to make predictions.
The more training data is made accessible to the model, the better it becomes at making predictions.
The known outcomes and the predictions from the model are compared, and the model’s parameters are tuned until the two line up. The aim of the training is to develop the model’s ability to generalize successfully.
What is Generalization?
As machine learning becomes more and more available to the general public. Hence, the most relevant concerns are the assessment of our confidence in trusting machine learning predictions.
In real cases, it is of utmost importance to estimate the capabilities of a machine learning model to generalize, i.e., to provide accurate predictions on unseen data.
Generalization refers to the model’s capability to adapt and react properly to training data, and unseen-data, which has been drawn from the same distribution as the one used to build the model.
How well a model is able to generalize is the key to its success.
If you train a model too well on training data, it will be incapable of generalizing. In such cases, it will end up making erroneous predictions when it’s given new data. This is known as overfitting.
The inverse is underfitting, which happens when you train a model with inadequate data. In cases of underfitting, your model would fail to make accurate predictions even with the training data. This would make the model just as useless as overfitting.
In other words, generalization examines how well a model can digest new data and make correct predictions after getting trained on a training dataset.
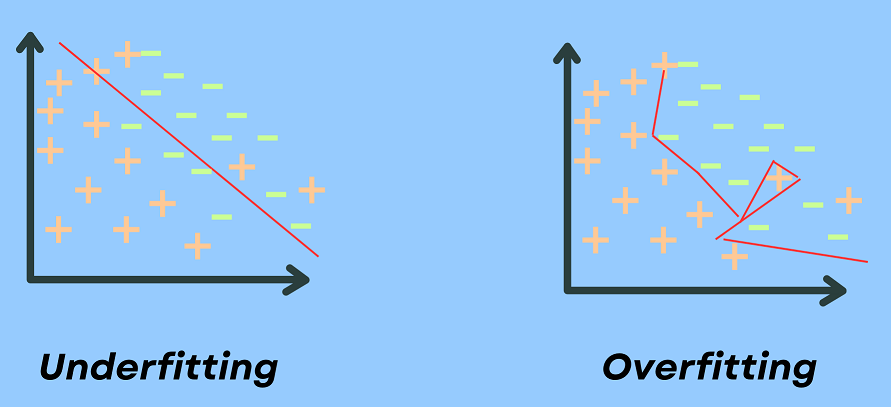
How to improve Model Generalization
To generalize a machine learning model, techniques that you can use are:
- Choose a model that stands at the sweet spot between overfitting and underfitting.
- The sweet spot is the point just before the error on the test dataset begins to rise where the model shows good skill on both the training dataset as well as the unseen test dataset.
- To achieve this goal, you can track the performance of a machine learning algorithm over time as it’s working with a training dataset.
- Using a resampling method to estimate the accuracy of the model.
- Holding back a validation dataset.
- Validation dataset is used to fine-tune hyperparameters like the number of hidden units and the learning rate.
- Cross Validation.
- Cross-validation option is typically employed in cases with tiny datasets, i.e. less than a few thousand examples.
- Add a regularization term.
- Regularization has no effect on the algorithm’s performance on the dataset used to learn the model parameters. It can, however, increase generalization performance.
- Stop the gradient descent training at the appropriate point.
- Implement data augmentation, and regularization in the machine learning model training phase.
- Use data normalization.
- Perform hyperparameter-tuning.
- Early stopping.
- Early stopping is a technique used to prevent the machine learning model from overfitting during training. Generally, the model learns from the training dataset by optimizing a loss function through gradient descent.
Generalization of your model is probably the most important element of your Machine Learning project. Model’s ability to generalize is central to the success of an Machine Learning project.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Overfitting and Underfitting
Machine Learning Optimization Techniques

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained