Machine learning is useful when it comes to solving complex problems from data. The issue is that data can also be scarce, and good labeled data can be expensive. It is also not easy to train a model for complex tasks, and we may need direction to a good solution.
Multi task learning offers a solution to the problem of efficiency and improved generalization. A shared backbone can be shared among multiple tasks and can benefit from the training signal coming from each of the target tasks. A larger learning signal can lead to improved learning speed.
What is Multi Task Learning?
Multi task Learning is an approach in machine learning and its aim is to leverage information contained in multiple related tasks to help improve the generalization performance of all the tasks.
It does by learning tasks in parallel while using a shared representation; what is learned for each task can help other tasks be learned better.
Multi task Learning encompasses a wide array of transfer learning style methods. It is training a single model to solve more than one task. This is generally done in parallel though it can be done sequentially in some cases.
In this post, we make sense of multi task learning definition and introduce the major considerations when deciding whether or not to employ multi task learning for your problem.
Transferring knowledge across tasks in order to improve model generalization is an important benefit of multi task learning.
How these benefits are achieved, either through training on multiple tasks in parallel or through sequential training, is a design decision that is context dependent.
Multi-task learning also combines examples from different tasks to improve generalization. When a model is shared across tasks, it is more constrained to excellent values, which often leads to better generalization.
Diagram shows a common type of multi-task learning in which several supervised tasks share the same input x, as well as an intermediate-level representation ‘h’ that captures a common pool of components.
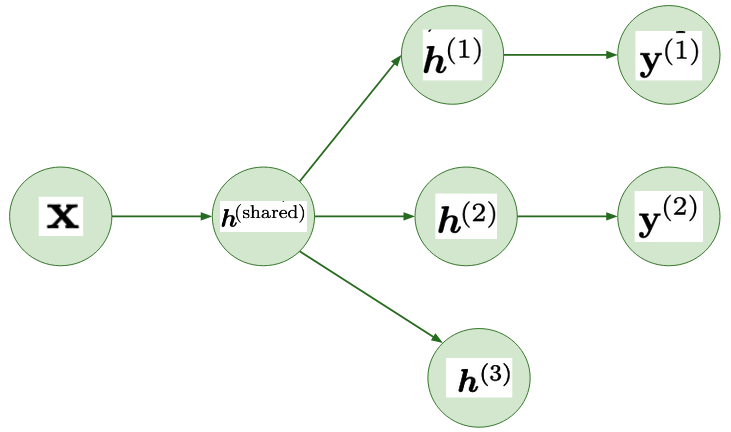
The model is divided into two parts, with its own parameters:
- Task specific parameters
- which only benefit from the examples of their task to achieve good generalization.
- Generic parameters
- those that apply to all tasks (which benefit from the pooled data of all the tasks).
Knowing that the performance improvement from multi-task learning is due to the extra information in the training signals of related tasks is different from knowing how that benefit occurs.
This section summarizes several mechanisms that help multi-task learning backprop nets to generalize better. The mechanisms all derive from the summing of error gradient terms at the hidden layer for the different tasks. Each, however, exploits a different relationship between tasks.
How does Multi Task Learning works?
The simplest way to think about multi-task learning is to consider a machine learning task where you have a dataset {X, Y} consisting of N input vectors x in X and N prediction targets y in Y where Y is an N, 1 dimensional vector representing N targets.
The standard classification loss in this case then would be:
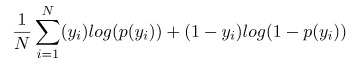
Y is an NxT dimensional matrix, where T is the number of tasks our model is being trained to solve. We can write our loss as:
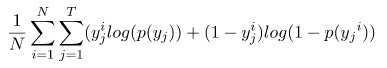
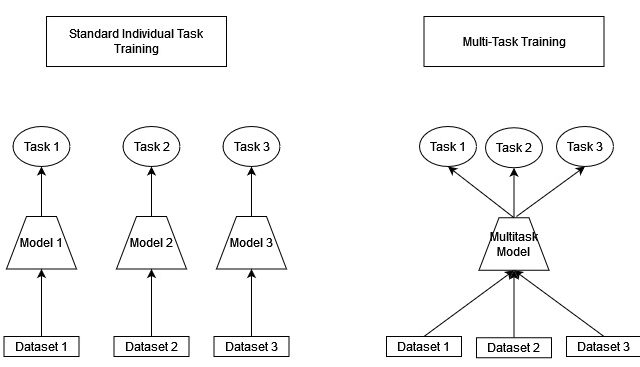
Multi-task loss simply adds the loss for each individual task. This loss allows us to train the full network for each task in parallel. The image offers a comparison of training many individual task models and one multi-task model.
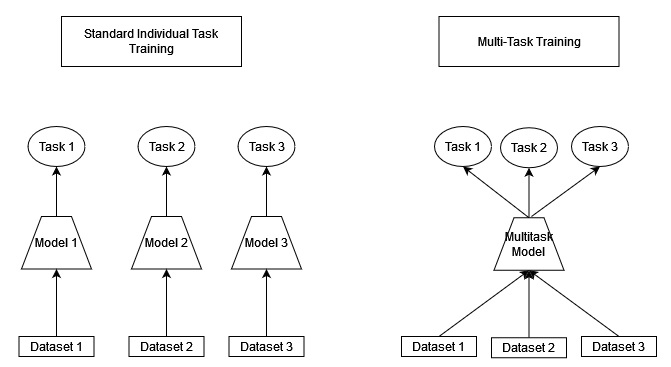
In order to benefit from multi-task learning, the set of tasks used needs to be considered. Some tasks will lead to negative transfer, making it harder to solve other tasks. We should consider the order and the choice of tasks; how much we weigh the solution to each of the tasks and what parts of the architecture are shared across tasks.
Balance the loss functions!
If we have multiple tasks, that means we have multiple loss functions. Optimizing each of those is challenging as they may have different scales, and different directions.
We need to choose which tasks to optimize together and how we balance each of those included losses.
If we have classification and regression tasks, the difference in loss metric is obvious. We may need to shrink the value of one of the losses to ensure it doesn’t dominate the loss.
Similarly, if the number of samples we have for one task is significantly larger than for another task, then we need to balance the losses.
Data sampling approaches are used to balance the network loss’s. Other approaches, such as weighted sampling and dynamic sampling, where samples are weighted towards data from underperforming tasks, can produce more balanced results.
Multi-Task Supervised Learning
Multi-task supervised learning (MTSL) setting means that each task in Multi-task is a supervised learning task, which models the functional mapping from data instances to labels.
Specifically, existing MTSL models reflect the task relatedness in three aspects: feature, parameter and instance, leading to three categories of MTSL models including
- Feature-based
- Feature-based MTSL models assume that different tasks share identical or similar feature representations, which can be a subset or a transformation of the original features.
- Parameter-based
- Parameter-based MTSL models aim to encode the task relatedness into the learning model via the regularization or prior on model parameters.
- Instance-based
- Instance-based MTSL models propose to use data instances from all the tasks to construct a learner for each task via instance weighting.
Multi-Task Unsupervised Learning
Multi-task unsupervised learning mainly focuses on multi-task clustering.
Clustering is to divide a set of data instances into several groups, each of which has similar instances, and hence multi-task clustering aims to conduct clustering on multiple datasets by leveraging useful information contained in different datasets.
Multi-Task Semi-supervised Learning
In multi-task semi-supervised learning, the goal is the same, where unlabeled data are used to improve the performance of supervised learning while different supervised tasks share useful information to help each other.
Based on the nature of each task, multi-task semi-supervised learning can be classified into two categories:
- Multi-task semi-supervised classification
- a method proposed in follows the task-clustering approach to do task clustering on different tasks based on a relaxed Dirichlet process, while in each task, random walk is used to exploit useful information contained in the unlabeled data.
- Multi-task semi-supervised regression
- a method is proposed in, where each task adopts a Gaussian process and unlabeled data are used to define the kernel function, and Gaussian processes in all the tasks share a common prior on kernel parameters.
Multi-Task Active Learning
In multi-task active learning, each task selects informative unlabeled data to query an oracle to actively acquire their labels. Hence the criterion for the selection of unlabeled data is the main research focus in multi-task active learning.
Specifically, two criteria are proposed in to make sure that the selected unlabeled instances are informative for all the tasks instead of only one task.
The selection criterion for unlabeled data is the expected error reduction. Moreover, a selection strategy, a tradeoff between the learning risk of a low-rank multi task learning model based on the trace-norm regularization and a confidence bound similar to multi-armed bandits, is proposed in.
Multi-Task Reinforcement Learning
Inspired by behaviorist psychology, reinforcement learning studies how to take actions in an environment to maximize the cumulative reward.
When environments are similar, different reinforcement learning tasks can use similar policies to make decisions, which is a motivation of the proposal of multi-task reinforcement learning.
In the reinforcement learning model for each task is a Gaussian process temporal-difference value function model and a hierarchical Bayesian model relates value functions of different tasks.
In the value functions in different tasks are assumed to share sparse parameters and it applies the multi-task feature selection method with the L1, L2 regularization. In an actor–mimic method, which is a combination of deep reinforcement learning and model compression techniques, is proposed to learn policy networks for multiple tasks.
Multi-Task Online Learning
When the training data come in a sequential way, traditional muti task models cannot handle them, but multi-task online learning is capable of doing this job.
Specifically, in where different tasks are assumed to have a common goal, a global loss function, a combination of individual losses on each task, measures the relations between tasks, and by using absolute norms for the global loss function, several online multi-task algorithms are proposed.
- In the proposed online multi-task algorithms model task relations by placing constraints on actions taken for all the tasks.
- In online multi-task algorithms, which adopt perceptrons as a basic model and measure task relations based on shared geometric structures among tasks, are proposed for multi-task classification problems.
- In a Bayesian online algorithm is proposed for a multi-task Gaussian process that shares kernel parameters among tasks.
- In an online algorithm is proposed for the multi-task-relationship learning method by updating model parameters and task covariance together.
Multi-Task Multi-View Learning
In some applications such as computer vision, each data point can be described by different feature representations. In this case, each feature representation is called a view and multi-view learning, a learning paradigm in machine learning, is proposed to handle such data with multiple views.
Each multi-view data point is usually associated with a label. Multi-view learning aims to exploit useful information contained in multiple views to further improve the performance over supervised learning, which can be considered as a single-view learning paradigm.
As a multi-task extension of multi-view learning, multi-task multi-view learning hopes to exploit multiple multi-view learning problems to improve the performance over each multi-view learning problem by leveraging useful information contained in related tasks.
The first multi-task multi-view classifier is proposed to utilize the task relatedness based on common views shared by tasks and view consistency among views in each task. In different views in each task achieve consensus on unlabeled data and different tasks are learned by exploiting a priori information as in or learning task relations as the MTRL method did.
When to use Multi-task Learning?
Multi-task learning can be applied in situations where not every input is labeled for every task. In cases where a label is missing, we simply eliminate the loss for that sample for that task and train only on what is available. This lets us include multiple datasets in our training which may be general or specific data generation processes.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Genetic Algorithm in Machine Learning
Spectral Clustering Algorithm

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained