Feature engineering is a critical step in building accurate and effective machine learning models. One key aspect of feature engineering is normalization, or standardization, which involves transforming the data to make it more suitable for modeling. These techniques can help to reduce the impact of outliers, and ensure that the data is on the same scale. In this post, we will explore the concepts of normalization, and standardization, including why they are important and how to apply them to different types of data.
What is Feature Scaling?
Feature scaling is a data preprocessing technique used to transform the values of features in a dataset to a similar scale. The purpose is to ensure that all features contribute equally to the model and to avoid the domination of features with larger values. There are several common techniques for feature scaling, including standardization, normalization. These methods adjust the feature values while preserving their relative relationships and distributions.
Scaling facilitates meaningful comparisons between features, improves model convergence, and prevents certain features from overshadowing others based solely on their magnitude.
What is Normalization?
Normalization is used to transform features to be on a similar scale.
This scales the range to [0, 1] or sometimes [-1, 1]. Normalization is useful when there are no outliers as it cannot cope up with them. Usually, we would scale age and not incomes because only a few people have high incomes but the age is close to uniform.
Normalization is also known as Min-Max scaling.
Here’s the formula for normalization:
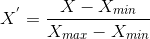
- Here, Xmax and Xmin are the maximum and the minimum values of the feature, respectively.
- When the value of X is the minimum value in the column, the numerator will be 0.
- On the other hand, when the value of X is the maximum value in the column, the numerator is equal to the denominator, and thus the value of X is 1.
- If the value of X is between the minimum and the maximum value, then the value of X is between 0 and 1.
What is Standardization?
Standardization is the transformation of features by subtracting from mean and dividing by standard deviation.
Standardization is also called Z-Score.
Standardization can be helpful in cases where the data follows a Gaussian distribution. Geometrically speaking, it translates the data to the mean vector of original data to the origin and squishes or expands the points if std is 1 respectively. We can see that we are just changing mean and standard deviation to a standard normal distribution which is still normal thus the shape of the distribution is not affected.
Here’s the formula for normalization:

Standardization does not get affected by outliers because there is no predefined range of transformed features.
Difference between Normalization and Standardization
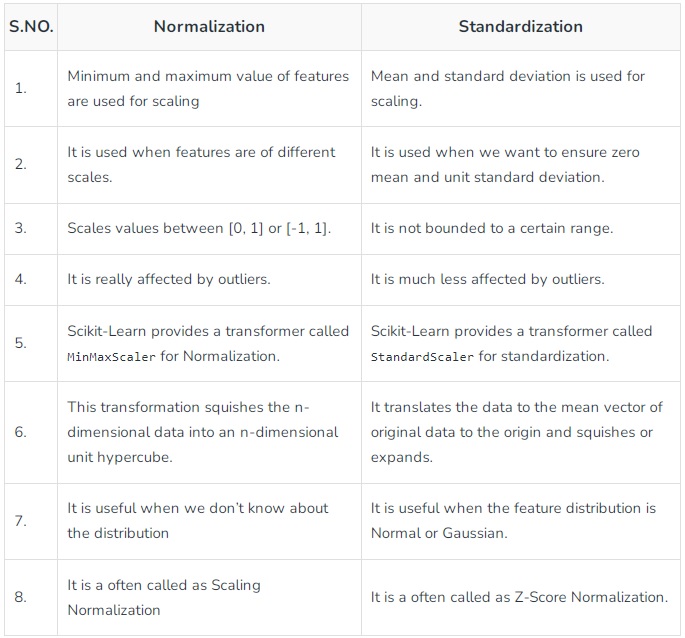
The choice of using normalization or standardization will depend on your problem and the machine learning algorithm you are using. There is no fast rule to tell you when to normalize or standardize your data. You can always start by fitting your model to raw, normalized, and standardized data and comparing the performance for the best results.
It is a good practice to fit the scaler on the training data and then use it to transform the testing data. This would avoid any data leakage during the model testing process. Also, the scaling of target values is generally not required.
Why we use feature scaling?
Some machine learning algorithms are sensitive to feature scaling, Let’s explore these:
- Gradient Descent Based Algorithms
- Machine learning algorithms like linear regression, logistic regression, neural network, PCA (principal component analysis), etc., that use gradient descent as an optimization technique require data to be scaled. Having features on a similar scale can help the gradient descent converge more quickly towards the minima.
- Distance-Based Algorithms
- Distance algorithms like KNN, K-means clustering, and SVM(support vector machines) are most affected by the range of features. This is because, behind the scenes, they are using distances between data points to determine their similarity.
- Tree-Based Algorithms
- Tree-based algorithms, on the other hand, are fairly insensitive to the scale of the features. A decision tree only splits a node based on a single feature. The decision tree splits a node on a feature that increases the homogeneity of the node. Other features do not influence this split on a feature. So, the remaining features have virtually no effect on the split. This is what makes them invariant to the scale of the features!
Recommended for you:
Data Normalization in Machine Learning
Data Standardization in Machine Learning


{kind=link}
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained