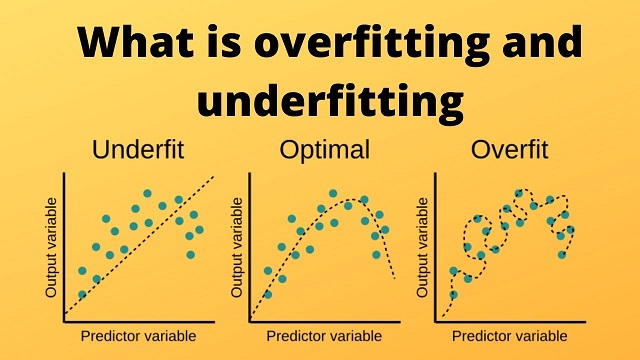
The most common challenges that machine learning practitioners face are overfitting and underfitting. Hence, it is important to understand the concept of overfitting and underfitting in machine learning.
In this post, we’ll take a look at these concepts, how they arise in our machine learning models, and what can be done to mitigate their effects.
What is Underfitting?
Underfitting is a problem in machine learning where the training subset does not learn the important parameters for predictions on the test subset. In simple words, model is too simple to represent the complexity of the data and fails to capture important relationships between the input and output variables.
When a model under fits the data, model has high bias and low variance. This means that the model is not able to fit the training data well, and also fails to generalize to new data. Sometimes underfitting occurs when there is not enough training data to capture the true complexity of the problem.
Underfitting causes
Some of the main reasons for underfitting are:
- Outdated model:
- An outdated model may not be capable of capturing the underlying patterns in the dataset.
- Bad quality of dataset:
- Dataset quality is an important factor for the model to learn from it. If dataset is noisy, missing or irrelevant, the model will underfit the dataset.
- Model simplicity:
- A model with a low number of parameters and low flexibility is more likely to underfit, as it can’t capture the underlying patterns in the data.
- An example, if we use a linear regression model to fit a dataset with a non-linear relationship between the input and output variables, the model may underfit the data.
- Insufficient training data:
- Model may underfit the data, if there is not enough training data to capture the underlying patterns. In this case, the model may generalize poorly to unseen data.
- Feature selection:
- If we select features that are not relevant, the model may not be able to capture the underlying patterns in the data.
- Regularization:
- Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function, which discourages the model from using complex solutions. However, if the regularization parameter is set too high, the model may under fit the data.
- Preprocessing:
- If dataset is not preprocessed properly, the model may underfit the data.
To avoid underfitting, we can use following techniques:
- Increase model complexity:
- This can be achieved by adding more layers or neurons in a neural network, increasing the degree of a polynomial regression model, or using a more complex model architecture.
- Increase the amount of training dataset:
- Providing the model with more data can help it learn more underlying patterns in the dataset.
- Feature engineering:
- Feature engineering involves creating new features or transforming existing ones to make them more informative.
- Reduce regularization:
- By reducing the regularization parameters, a model can be allowed to fit the training data more closely, which can reduce underfitting.
- Apply different algorithm:
- Some algorithms may be better suited to certain types of data or problems than the others.
- Ensemble methods:
- Ensemble methods involve combining multiple models to improve performance. This can help reduce underfitting by combining the strengths of multiple models and reducing the impact of any individual model’s weaknesses.
- Cross-validation:
- Cross-validation is a technique used to assess the performance of a model on unseen data. It can be used to tune the model parameters to reduce underfitting.
- Hyperparameter tuning:
- Hyperparameter tuning can help to find the best hyperparameters for a model, which can increase its ability to capture the underlying patterns in the dataset.
- Increasing training time:
- increase the training time as the model might not have yet learned some of the useful features that might help model make better predictions.
- Training machine learning models for many iterations would ensure that useful features and their importance are learned during the process of making robust predictions.
What is Overfitting?
Overfitting occurs when a model is trained too well on the training subset, and as a result, it performs poorly on unseen data. It is a problem in machine learning where it fits the noise in the data rather than the underlying patterns.
In simple words, the model becomes too complex and starts to memorize the training data rather than generalize to unseen data. This leads to lack the ability to generalize beyond the training data.
Overfitting can occur in any type of machine learning model with a large number of parameters, including regression, classification, or deep learning networks.
Overfitting causes
Some of the main reasons for Overfitting are:
- Insufficient training dataset:
- When there is not enough data to train a model, the model may overfit as it tries to learn from a limited amount of data.
- Model complexity:
- This can happen when a model has too many hyperparameters relative to the amount of training dataset.
- Feature selection:
- If the model is overfitting, it may be because it is too closely fitting noise in the irrelevant selected features.
- Lack of regularization:
- Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function that discourages overly complex models. If the regularization parameter is set too low or not used at all, the model may overfit the training data.
- Data leakage:
- Data leakage occurs when information from the test subset is accidentally used during training subset, leading to overly optimistic performance estimates and potential overfitting.
To avoid overfitting, we can use following techniques:
- Increasing the amount of training dataset:
- Providing more data can help the model learn the underlying patterns in the data accurately and reduce overfitting.
- Reducing model complexity:
- Reducing the number of hyperparameters in the models can help prevent overfitting by reducing the risk of fitting noise in the data.
- Regularization:
- Regularization techniques such as L1 or L2 can help prevent overfitting by adding a penalty for overly complex models.
- Cross-validation:
- Cross-validation can help identify when a model is starting to overfit and when to stop training.
- Data augmentation:
- Data augmentation techniques can be used to artificially increase the size of the training data set by generating new examples from the existing data.
- Ensemble methods:
- Ensemble methods can help reduce overfitting by combining the predictions of multiple models.
- Hyperparameter tuning:
- Hyperparameters are set before training the model. Tuning these parameters can help to prevent overfitting by finding the best combination of hyperparameters for a given model.
- Distribution of training and test dataset:
- It is important to note that the training and test dataset have the same distribution. If training dataset distribution be different as compared to the testing dataset. Model might learn really well on the training data but when it comes to testing data, it would not perform well as the distribution is different.
- Reducing the dimensionality of the input:
- Sometimes with a lot of features and very few training examples, it is possible for machine learning models to overfit the training data.
- Since there are not many training examples, the model would just take the features and make predictions leading to the model having overfitting problems.
Infographic

Source is pinterest
In summary
Overfitting and underfitting are common problems in machine learning, and they happen when a model is trained too well or not well enough on the training data, respectively. To prevent overfitting, techniques such as regularization, cross-validation, ensemble methods, and hyperparameter tuning can be used.
To prevent underfitting, techniques such as increasing model complexity, collecting more data, feature engineering, hyperparameter tuning, and ensemble methods can be used.
Note that there is no one-size-fits-all solution to overfitting or underfitting, and the optimal approach may vary depending on the specific problem and dataset being used.
Recommended for you:
Machine Learning Optimization Techniques
Bias and Variance in Machine Learning
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained