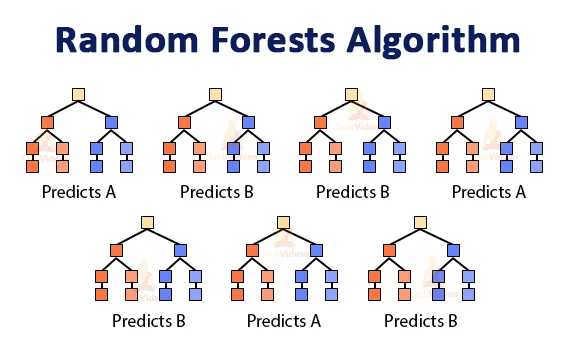
It is a supervised machine learning algorithm that is constructed from decision tree algorithms, and widely used for both classification and regression problems.
Tree-based structure algorithms tend to use the mean for continuous features or mode for categorical features when making predictions on training samples in the regions they belong to. They also produce predictions with high accuracy, stability, and ease of interpretation.
This post will present the algorithm’s features and how it works. It also points out the advantages and disadvantages of this algorithm.
What is Decision Tree?
As we know, the Random Forest model combines multiple decision trees to create a forest. Decision tree is another type of algorithm used to classify data. In very simple terms, you can think of it like a flowchart that draws a pathway to the outcome. It starts at a single point and then branches off into two or more directions, with each branch offering different possible outcomes.
Tree has an inherent hierarchy, that organizes information in a hierarchical manner. The order that the information appears matters and leads to different trees as a result. Figure below, is an example of the decision tree
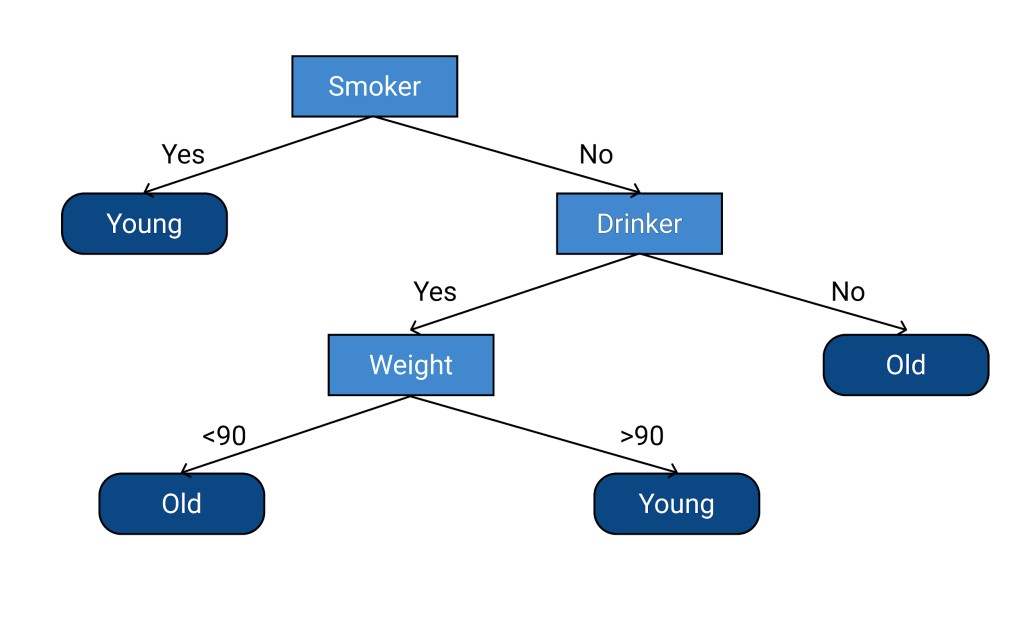
By looking at the tree, it is easy to understand those divisions and see how each layer is derived from previous ones, those layers are the tree levels, and the levels describe the depth of the tree.
When the data is classified, that means the tree is performing a classification task, and when the quantity of data is found, the tree is performing a regression task. This means that the decision tree can be used for both classification and regression tasks.
What is Random Forest?
A random forest algorithm consists of many decision trees. The forest generated by the random forest algorithm is trained through bagging or bootstrap aggregating. Bagging is an ensemble meta algorithm, that improves the accuracy of machine learning algorithms.
Random forest tends to combine hundreds of decision trees and then trains each decision tree on a different sample of the observations. The final predictions of the forest are made by averaging the predictions of each individual tree. Increasing the number of trees increases the precision of the outcome.
The benefits of this algorithm are numerous. The individual decision trees tend to overfit, but random forest can mitigate that issue by averaging the prediction results from different trees. That gives forest algorithm a higher predictive accuracy than a single decision tree. It can also help you to find features that are important in your dataset. It lies at the base of the Boruta algorithm, which selects important features in a dataset.
It uses in a variety of applications, from recommendations of different products to customers in e-commerce, to identify the patient’s disease by analyzing the patient’s medical record.
How does the Random Forest algorithm work?
The logic behind this algorithm is that multiple uncorrelated models perform much better as a group than they do alone. When using random forest for classification, each tree gives a vote. The forest chooses the classification with the majority of the votes. When using it for regression, the forest picks the mean of the outputs of all trees.
The key here lies in the fact that there is low or no correlation between the decision trees, that make up the larger random dorest model. While individual decision trees may produce errors, the majority of the group will be correct, thus moving the overall outcome in the right direction.
The following are the main steps involved when executing the algorithm:
- The algorithm select random samples from the data set provided. Each tree fit on a random subset of features, which is rectified by ensembling.
- The algorithm will create a decision tree for each sample selected. Then it will get a prediction result from each decision tree created.
- Voting will then be performed for every predicted result. For a classification problem, it will use mode, and for a regression problem, it will use mean.
- In classification task: each tree will predict the category to which the new record belongs. After that, the new record is assigned to the category that wins the majority vote.
- In regression task: each tree predicts a value for the new record, and the final prediction value will be calculated by taking a mean of all the values predicted by all the trees in the forest.
- Finally, the algorithm will select the most voted prediction result as the final prediction.
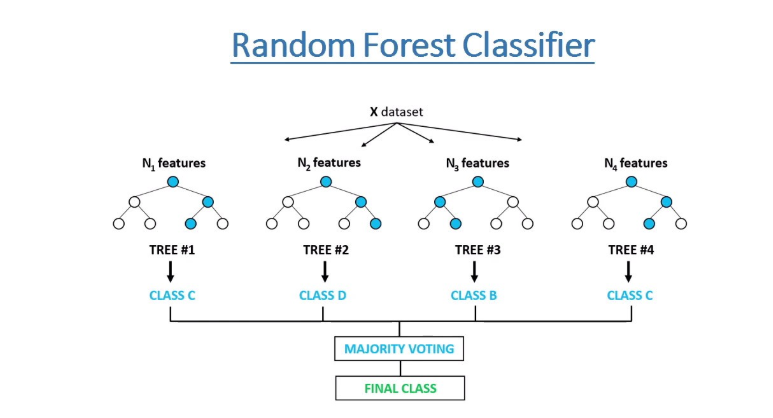
Applying Decision Trees in Random Forest algorithm
The random forest employs the bagging method to generate the required prediction. The bagging method is a type of ensemble machine learning algorithm called Bootstrap Aggregation. An ensemble method combines predictions from multiple machine learning algorithms together to make more accurate predictions than an individual model. Random Forest is also an ensemble method.
Bootstrap Aggregation randomly performs row and feature sampling from the data set to form sample data sets for every model. Aggregation reduces these sample datasets into summary statistics based on the observation and combines them. bagging can be used to reduce the variance of high variance algorithms such as decision trees.
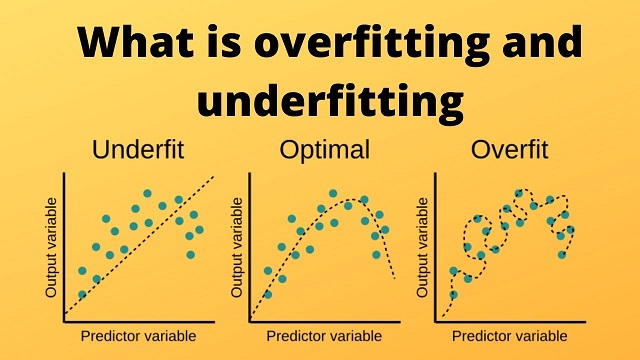
Variance is an error resulting from sensitivity to small fluctuations in the data set. High variance will cause an algorithm to model noise, in the dataset instead of the intended outputs, called signal. This problem is called overfitting. An overfitted model will perform well in training, but won’t be able to distinguish the noise from the signal in an actual test.
Advantages
It offers a variety of the following advantages.
- It can perform both regression and classification tasks.
- It produces good predictions that can be understood easily.
- It can handle large data sets efficiently.
- This algorithm provides a higher level of accuracy in predicting outcomes over the decision tree algorithm.
Disadvantages
- Because it uses many decision trees, it can require a lot of memory on larger projects. This can make it slower than some other algorithms.
- Sometimes, because this is a decision tree-based method and decision trees often suffer from overfitting, this can affect the overall forest.
- Unlike linear regression, which uses existing observations to estimate values beyond the observation range. Random forest regression is not ideal in the extrapolation of data.
- It does not produce good results when the data is very sparse. In this case, the subset of features and the bootstrapped sample will produce an invariant space. This will lead to unproductive splits, which will affect the outcome.
In Summary:
- Random Forest is a supervised machine learning algorithm made up of decision trees.
- It is used for both classification and regression.
- Overall, it is accurate, efficient, and relatively quick to develop, making it an extremely handy tool for data scientists.
Recommended for you:
Top Machine Learning Algorithms
Bias and Variance in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained