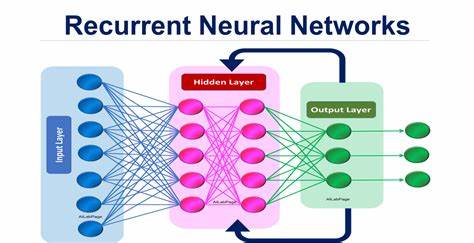
What is Recurrent neural networks?
Recurrent neural networks also known as RNNs are a class of neural networks that are naturally suited to processing time-series data and other sequential data x(t)= x(1), . . . , x(τ) with the time step index t ranging from 1 to τ.
For tasks that involve sequential inputs, such as speech and language, it is often better to use RNNs. In natural language processing problem, if you want to predict the next word in a sentence, it is important to know the words before it. RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations.
In simple words, RNNs have memory which captures information about what has been calculated so far.
RNN works on the principle of saving the output of a particular layer and feeding this back to the input in order to predict the output of the layer.
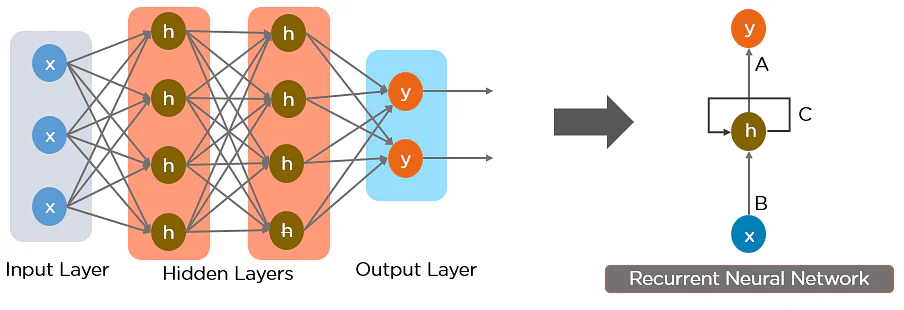
- Input: x(t) is taken as the input to the network at time step t. For example, x1, could be a one-hot vector corresponding to a word of a sentence.
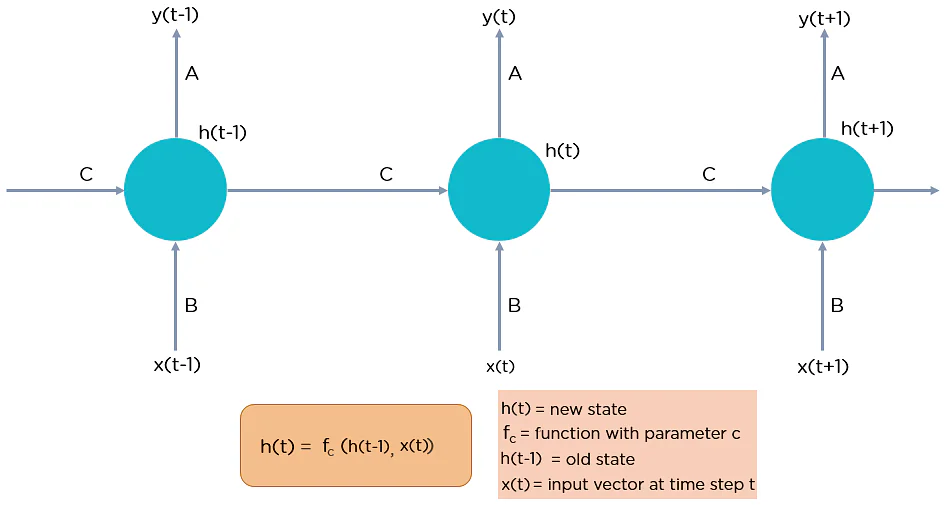
- Hidden state: h(t) represents a hidden state at time t and acts as memory of the network. h(t) is calculated based on the current input and the previous time step’s hidden state: h(t) = f(U x(t) + W h(t−1)). The function f is taken to be a non-linear transformation such as ReLU.
- Weights: The RNN has input to hidden connections parameterized by a weight matrix U, hidden-to-hidden recurrent connections parameterized by a weight matrix W, and hidden-to-output connections parameterized by a weight matrix V and all these weights (U, V, W) are shared across time.
- Output: o(t) illustrates the output of the network. In the figure I just put an arrow after o(t) which is also often subjected to non-linearity, especially when the network contains further layers downstream.
Fully connected Recurrent Neural Network
Here, “x” is the input layer, “h” is the hidden layer, and “y” is the output layer. A, B, and C are the network parameters used to improve the output of the model. At any given time t, the current input is a combination of input at x(t) and x(t-1). The output at any given time is fetched back to the network to improve on the output.
Why Recurrent Neural Networks?
RNN were created because there were a few issues in the feed-forward neural network:
- Cannot handle sequential data.
- Considers only the current input.
- Cannot memorize previous inputs.
RNN can handle sequential data, accepting the current input data, and previously received inputs. RNNs can memorize previous inputs due to their internal memory.
How Does RNN work?
In RNN, the information cycles through a loop to the middle-hidden layer.
- The input layer ‘x’ takes in the input to the neural network and processes it and passes it onto the middle layer.
- The middle layer ‘h’ can consist of multiple hidden layers, each with its own activation functions and weights and biases.
Recurrent Neural Network will standardize the different activation functions and weights and biases so that each hidden layer has the same parameters. Then, instead of creating multiple hidden layers, it will create one and loop over it as many times as required.
Types of RNN
- One to One
- This type of neural network is known as the Vanilla Neural Network. It’s used for general machine learning problems, which has a single input and a single output.
- One to Many
- This type of neural network has a single input and multiple outputs.
- Many to One
- This RNN takes a sequence of inputs and generates a single output. Sentiment analysis is a good example of this kind of network where a given sentence can be classified as expressing positive or negative sentiments.
- Many to Many
- This RNN takes a sequence of inputs and generates a sequence of outputs. Machine translation is one of the examples.
Two Issues of Standard RNN
Vanishing Gradient Problem
RNNs suffer from the vanishing gradients problem. The gradients carry information used in the RNN, and when the gradient becomes too small, the parameter updates become insignificant. This makes the learning of long data sequences difficult.
Exploding Gradient Problem
While training a neural network, if the slope tends to grow exponentially instead of decaying, this is called Exploding Gradient. This problem arises when large error gradients accumulate, resulting in very large updates to the neural network model weights during the training process.
Long training time and poor performance are the major issues in gradient problems.
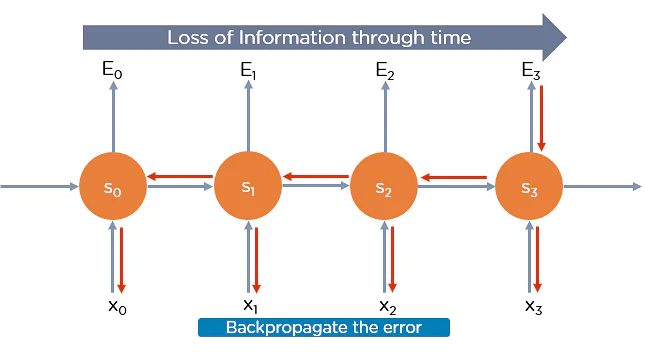
Backpropagation Through Time
Backpropagation through time is when we apply a Backpropagation algorithm to a Recurrent Neural network that has time-series data as input.
In a typical RNN, one input is fed into the network at a time, and a single output is obtained. But in backpropagation, you use the current as well as the previous inputs as input. This is also called timestep, and a timestep will consist of many time series datapoints entering the RNN simultaneously.
Once the neural network has trained on a time set and given you an output, that output is used to calculate and accumulate the errors. After this, the network is rolled back up and weights are recalculated and updated keeping the errors in mind.
Recommended for you:
MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained