
Reinforcement Learning is the science of decision making. Reinforcement Learning is about learning the optimal behavior in an environment to obtain maximum reward. In the absence of a supervisor, the learner must independently discover the sequence of actions that maximize the reward. This discovery process is akin to a trial-and-error search. The quality of actions is measured by not just the immediate reward they return, but also the delayed reward they might fetch. As it can learn the actions that result in eventual success in an unseen environment without the help of a supervisor, reinforcement learning is a very powerful algorithm.
Reinforcement learning uses algorithms that learn from outcomes and decide which action to take next. After each action, the algorithm receives feedback that helps it determine whether the choice it made was correct, neutral or incorrect. It is a good technique to use for automated systems that have to make a lot of small decisions without human guidance.
SARSA Reinforcement Learning
SARSA (State-Action-Reward-State-Action) is a reinforcement learning algorithm that is used to learn a policy for an agent interacting with an environment. This means that the SARSA algorithm waits for the next action to be taken in the next state before updating the Q-function.
SARSA very much resembles Q-learning. The key difference between SARSA and Q-learning is that SARSA is an on-policy algorithm. It implies that SARSA learns the Q-value based on the action performed by the current policy instead of the greedy policy.
The SARSA algorithm works by maintaining a table of (action-value) estimates Q(s, a), where s is the state and a is the action taken by the agent in that state. The table is initialized to some arbitrary values, and the agent uses an (epsilon-greedy) policy to select actions.
Due to this difference, the SARSA algorithm knows the action taken in the next state and does not need to maximize the Q-function over all possible actions in the next state. The difference in the update rule for Q-Learning vs. SARSA is shown in Fig below.
Function update equation for Q-Learning (top) vs. SARSA (bottom)
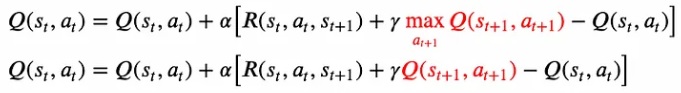
The steps involved in the SARSA algorithm
- Initialize the action-value estimates Q(s, a) to some arbitrary values.
- Set the initial state.
- Choose the initial action a using an epsilon-greedy policy based on the current Q values.
- Take the action a and observe the reward r and the next state s’.
- Choose the next action a’ using an epsilon-greedy policy based on the updated Q values.
- Update the action-value estimate for the current state-action pair using the SARSA update rule: Q(s, a) = Q(s, a) + alpha * (r + gamma * Q(s’, a’) – Q(s, a)) where alpha is the learning rate, gamma is the discount factor, and r + gamma * Q(s’, a’) is the estimated return for the next state-action pair.
- Set the current state s to the next state s’, and the current action a to the next action a’.
- Repeat steps 4-7 until the episode ends.
Advantage and Disadvantage
- Advantage: On-Policy is appropriate if the overall policy is controlled by another agent or program, such that the agent does not go Off-Policy and try other actions.
- Disadvantage: SARSA is less flexible than Q-Learning since it does not go Off-Policy to explore other policies. It learns the policy at a slower rate compared to ADP as the local updates do not ensure consistency to Q-values.
SARSA algorithm learns a policy that balances exploration and exploitation, and can be used in a variety of applications, including robotics or decision making. However, it is important to note that the convergence of the SARSA algorithm can be slow, especially in large state spaces.
Recommended for you:


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained