
Machine Learning is a fast-growing technology, and is already integrated into our daily lives with tools like face recognition and self-driving cars.
Scikit-learn is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support-vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
If you are a python developer looking for a powerful library for machine learning, then you must take scikit-learn into your consideration. Scikit-learn in python plays an essential role in the machine learning. This scikit-learn cheat sheet is designed for the one who has already started learning about the python package. If you are a beginner and have no idea about how scikit-learn works, this scikit-learn cheat sheet for machine learning will give you a quick reference of the basics that you must know to get started.
Review on Machine Learning
Machine Learning teachs the computer to perform and learn tasks without being explicitly coded. This means that the system possesses a certain degree of decision-making capabilities. Machine Learning can be divided into three major categories:
- Supervised Learning
- In this machine learning model, our system learns under the supervision of a teacher. The model has both a known input and output used for training.
- Unsupervised Learning
- Unsupervised Learning (clustering) refers to models where there is no supervisor for the learning process. The model uses input for training and the output is learned from the inputs.
- Reinforcement Learning
- Reinforcement Learning refers to machine learning models that learn to make decisions based on rewards or punishments and tries to maximize the rewards with correct answers.
Import Convention
Before you start using Python Scikit-learn, you need to remember that it is a Python library and you need to import it.
import sklearn Data Loading
Following are the two ways you can load the data, you can also use some other numeric array to load your data.
Numpy
import numpy as np
a = np.array([(1,2,3,4),(5,6,7,8)], dtype=int)
data = np.loadtxt(‘file_name.csv’, delimiter=’,’)
Pandas
import pandas as pd
df = pd.read_csv(‘file_name.csv’, header=0)
df_ = pd.read_excel(‘file_name.csv’, header=0)
Split data into Train-Test
The next step is to split your data in training data set and testing data set.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
Data Preprocess
- Standardization:
- Data standardization is used for rescaling attributes so that the attributes have a mean value of 0 and a standard deviation of 1. Standardization assumes that your data has a Gaussian distribution.
- Normalization:
- Normalization is a technique used for data preparation for machine learning. The main goal of normalization is to change the values of numeric columns in the dataset so that we can have a common scale, without losing the information or distorting the differences in the ranges of values.
- Binarization
- Binarization is a operation performed on text data. Using binarization the analyst can decide to consider the presence or absence of a feature rather than having a quantified number of occurrences for instance.
- Encoding Categorical Features
- The LabelEncoder is another class used in preprocessing to transform non-numerical labels into numerical labels.
from sklearn.preprocessing import StandardScaler
import pandas as pd
df = pd.read_csv(‘file_name.csv’, header=0)
columns_names = df.columns
scaler = StandardScaler()
scaled_df = scaler.fit_transform(df)
scaled_df = pd.DataFrame(scaled_df, columns=columns_names )
from sklearn.preprocessing import Normalizer
X = [[4, 1, 2, 2],
[1, 3, 9, 3],
[5, 7, 5, 1]]
normalizer = Normalizer().fit(X)
normalizer .transform(X)
from sklearn.preprocessing import Binarizer
binarizer = Binarizer(threshold=0.0).fit(X)
binary_X = binarizer.transform(X)
from sklearn.preprocessing import LabelEncoder
enc = LabelEncoder()
y = enc.fit_transform(y)
Machine Learning Model Creation
Supervised Learning
from sklearn.linear_model import LinearRegression
lr = LinearRegression(normalize=True)
# Naive Bayes Algorithm
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
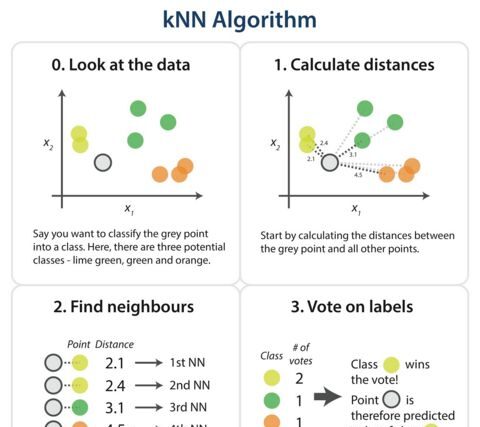
# KNN Algorithm
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier(n_neighbors=3)
# Support Vector Machines for classification
from sklearn.svm import SVC
svc = SVC(kernel=’linear’)
Unsupervised Learning
# K Means Clustering Algorithm
from sklearn.cluster import KMeans
k_means = KMeans(n_clusters=3, random_state=0)


Recommended for you:

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained