
In machine learning, a distinction has been made between two tasks: supervised and unsupervised learning.
In supervised learning, one is presented with a set of datapoints consisting of input x and a corresponding output y. The goal is, to construct a classifier or regressor that can estimate the output value for unseen inputs.
In unsupervised learning, no specific output value is provided. Instead, we try to infer some underlying structure from the inputs.
What is Semi Supervised Learning?
Semi supervised learning is a combination of supervised and unsupervised learning.
Typically, semi supervised learning algorithms attempt to improve performance in one of supervised or unsupervised tasks by utilizing information generally associated with the other.
For instance, by tackling a classification problem, additional data points for which the target is unknown might be used to aid in process.
For clustering methods, the learning procedure benefit from the knowledge that certain datapoints belong to the same class.
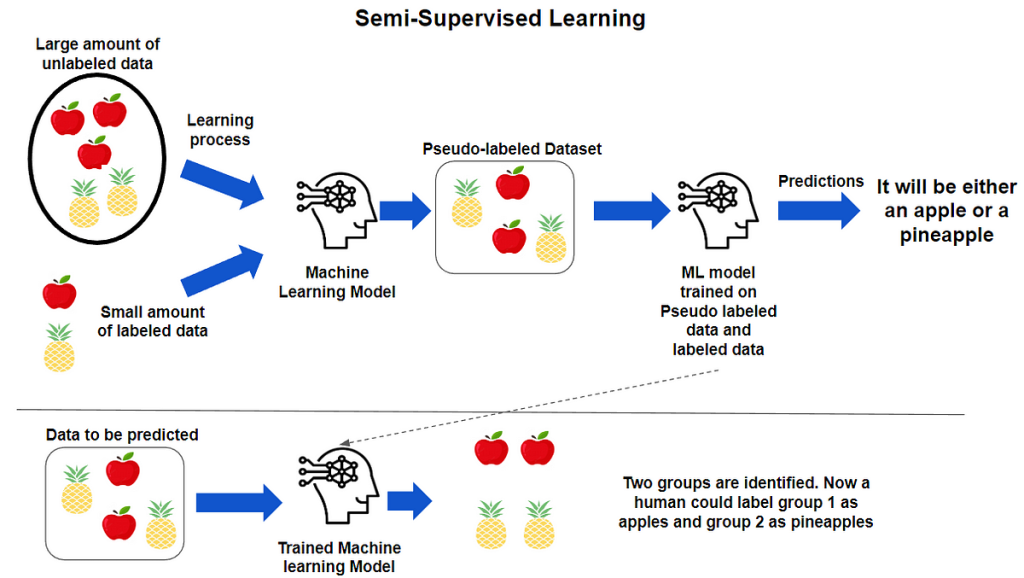
Semi supervised uses a small amount of labeled data and a large amount of unlabeled data, which provides the benefits of both unsupervised and supervised learning.
Therefore, you can train a machine learning model to label a data without having to use as much labeled training data.
Semi supervised algorithms approach use small amounts of labeled data and also large amounts of unlabeled data. This reduces expenses on manual annotation and data preparation time.
Since unlabeled dataset is easy to get, and inexpensive, semi supervised learning finds many applications.
Semi Supervised Learning Techniques
Consistency Regularization
The motivation of consistency regularization is to take advantage of the continuity and cluster assumptions.
Let’s say we have a dataset with both labeled and unlabeled examples of two classes.
During training, we handle labeled and unlabeled datapoints differently. For labeled datapoints, we optimize using traditional supervised learning, calculating loss by comparing our prediction to our target.
For unlabeled datapoints, we want to enforce that on our low dimensional manifold similar datapoints have similar predictions.
Pseudo-labeling
Pseudo labelling is where, during training, model predictions are converted into a one hot label. Instead of manually labeling the unlabeled data, we give our model approximate labels on the basis of the labelled data. Let’s explain pseudo-labeling.
- We train a model with labelled data.
- We use the trained model to predict labels for unlabeled data, which creates pseudo labeled data.
- We retrain the model with the pseudo labeled and labeled data together.
- This process happens iteratively as the model improves and is able to perform with a greater degree of accuracy.
Self-Training
Self-training is a variation of pseudo labeling. The difference with self-training is that we accept only the predictions that have a high confidence, and we iterate through this process several times.
- We pick a small amount of labeled data, and we use this dataset to train a base model with the help of ordinary supervised methods.
- Then we apply pseudo labeling. when you take the partially trained model and use it to make predictions for the rest of the database which is unlabeled, the labels generated thereafter are called pseudo.
- From this point, we take the most confident predictions made with the model. If any of the pseudo labels exceed this confidence level, we add them to the labeled dataset and create a new, combined input to train an improved model.
- The process can go through several iterations with more pseudo labels being added every time.
Label Propagation
Label propagation is a graph-based method to infer pseudo labels for unlabeled data. Unlabeled data points iteratively adopt the label of the majority of their neighbors based on the labelled datapoints.
Label propagation workflow is as follows:
- All of the nodes have soft labels assigned based on the distribution of labels.
- Labels of a node are propagated to all nodes through edges.
- Each node will update label iteratively based on the maximum number of nodes in neighbourhood.
- The label of a node is persisted from the labeled data, making it possible to infer a broad range of traits that are assortative along the edges of a graph.
- The label propagation algorithm stops when every node for the unlabeled datapoint has the majority label of its neighbor or the number of iterations defined is reached.
Assumptions
It uses any of the following assumptions.
- Continuity Assumption
- The objects near each other tend to share the same group or label. This assumption is also used in supervised learning. But in semi supervised, the decision boundaries are added in the low-density boundaries.
- Cluster assumptions
- Data are divided into different discrete clusters. Further, datapoints in the same cluster share the output label.
- Manifold assumptions
- This helps to use distances and densities, and this data lie on a manifold of fewer dimensions than input space.
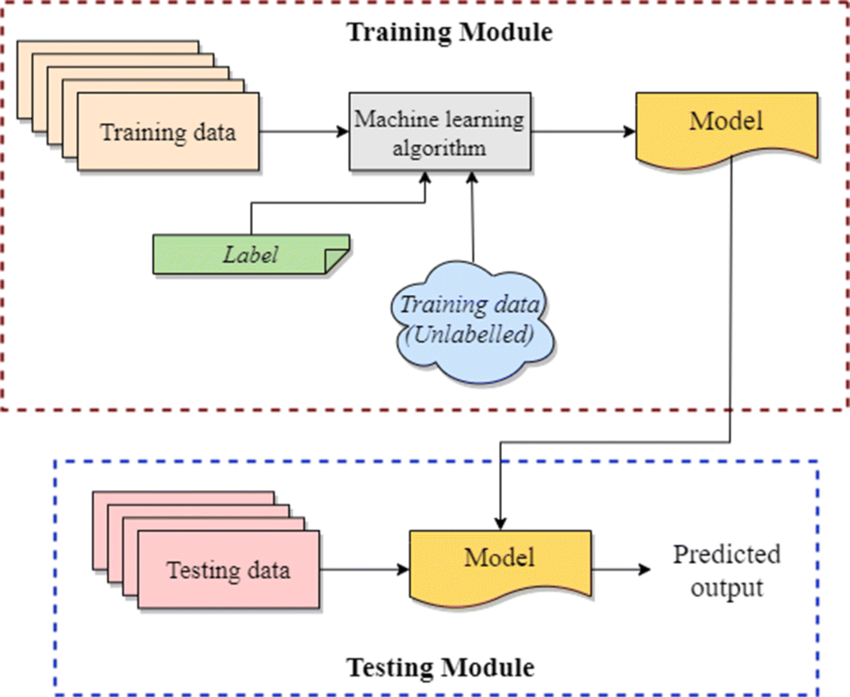
How does Semi Supervised Learning works?
It uses pseudo labeling to train the model with less labeled training. Here’s how it works.
- Train the model with the small amount of labeled training dataset, until it gives the good results.
- Then use it with unlabeled training data to predict the outputs, which are pseudo labels since they may not be quite accurate.
- Link the labels from labeled training data with the pseudo labels created in the previous step.
- Link the data inputs in labeled training data with inputs in the unlabeled data.
- Finaly, train the model as you did with the labeled set in the beginning in order to improve the model’s accuracy.
When does Semi Supervised Learning work?
The goal is to harness unlabeled data for the construction of better learning procedures. Its models are becoming more popular in the industries. Some of the main applications are as follows.
- Speech Analysis
- Since, labeling the audio data is the most impassable task that requires many human resources, this problem can be naturally overcome with the help of applying a semi supervised learning model.
- Web content classification
- Labeling each page on the internet can be reduced through Semi-Supervised learning algorithms.
- Text document classifier
- It would be very unfeasible to find a large amount of labeled text data, so semi supervised learning is an ideal method to overcome this problem.
But it doesn’t apply well to all tasks. If the portion of labeled data isn’t representative of the entire distribution.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Deep Learning vs Machine Learning
Concepts of Data Science

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained