Spectral Clustering has become one of the most popular clustering algorithms. It is simple to implement, and very often outperforms traditional clustering algorithms such as the k-means algorithm. The goal of this post is to give some intuition on this algorithm.
What Is Clustering ?
Clustering is the process of separating different parts of data set based on common characteristics. Disparate industries including business, finance or healthcare use clustering techniques for various analytical tasks.
Python offers many useful tools for performing cluster analysis. The best tools to use depends on the problem at hand and the type of data available. There are many widely used techniques for how to form clusters in Python.
What is Spectral Clustering ?
Spectral clustering is a method used for cluster analysis on high dimensional and complex data. It works by performing dimensionality reduction on the input and generating clusters in the reduced dimensional space. It treats each data point as a graph node and thus transforms the clustering problem into a graph partitioning problem. An implementation consists of three steps:
1- Building the Similarity Graph: This step builds the Similarity Graph in the form of an adjacency matrix (A). The adjacency matrix can be built in the following manners:
- Epsilon Neighbourhood Graph: The epsilon is fixed beforehand. Then, each point is connected to all the points which lie in it’s epsilon-radius. If all the distances between any two points are similar in scale then typically the weights of the edges are not stored since they do not provide any additional information. Thus, the graph built is an undirected and unweighted graph.
- K-Nearest Neighbours (KNN): The (k) parameter is fixed beforehand. Then, for two vertices u and v, an edge is directed from u to v only if v is among the KNN of u. Note that this leads to the formation of a weighted and directed graph.
2- Projecting data onto a lower-dimensional Space: This step is done to account for the possibility that members of the same cluster may be far away in the given dimensional space. Thus the dimensional space is reduced so that those points are closer in the reduced dimensional space and thus can be clustered together by a another clustering algorithm.
3- Clustering: This process mainly involves clustering the reduced data by using any traditional clustering technique like K-Means. First, each node is assigned a row of the normalized of the Graph Laplacian Matrix. Then this data is clustered using detemined traditional technique. To transform the clustering result, the node identifier is retained.
Spectral Clustering is a class of clustering methods, drawn from linear algebra, and a promising alternative that has recently emerged in a number of fields.
Advantages of Spectral Clustering
- Scalability: It can handle large and high-dimensional datasets , as it reduces the dimensionality of the data before clustering.
- Flexibility: It can be applied to non-linearly separable data, as it does not rely on traditional distance-based clustering algorithms.
- Robustness: Spectral clustering can be more robust to noise and outliers in the dataset, as it considers the global structure of the dataset, rather than just local distances between data points.
Disadvantages of Spectral Clustering
- Complexity: It can be computationally expensive for large datasets, as it requires the calculation of eigenvectors and eigenvalues.
- Model selection: Choosing the right number of clusters and the right similarity matrix can be challenging, and require expert knowledge.
Difference between Spectral Clustering and Conventional Clustering
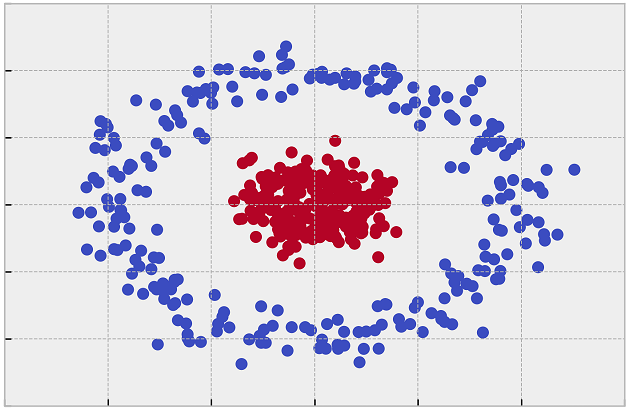
Spectral clustering is flexible and allows us to cluster non-graphical dataset as well. It makes no assumptions about the form of the clusters. Conventional Clustering techniques, like K-Means, assume that the points assigned to a cluster are spherical about the cluster centre. This is a strong assumption and may not always be relevant. In such cases, Spectral Clustering helps create more accurate clusters. It can correctly cluster observations that actually belong to the same cluster, but are farther off than observations in other clusters, due to dimension reduction.
The data points in Spectral Clustering should be connected, but may not necessarily have convex boundaries, as opposed to the conventional clustering techniques, like K-Means, where clustering is based on the compactness of data points. Although, it is computationally expensive for large datasets, since eigenvalues and eigenvectors need to be computed and clustering is performed on these vectors.
In summary
In order to solve the problem that the traditional clustering algorithm is time and resource consuming when applied to large-scale dataset, resulting in poor clustering effect or even unable to cluster, this post proposes a spectral clustering algorithm.
This algorithm changes the construction method of the similarity matrix. Based on the size of the similarity matrix is greatly reduced, and the construction of the similarity matrix is more reasonable. Experimental results show that the proposed algorithm achieves better speedup ratio, less memory consumption and stronger anti noise performance while achieving similar clustering results to the traditional clustering algorithm.
Recommended for you:
K-Mean Clustering Algorithm
Naive Bayes Algorithm
Spectral clustering – Wikipedia


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained