
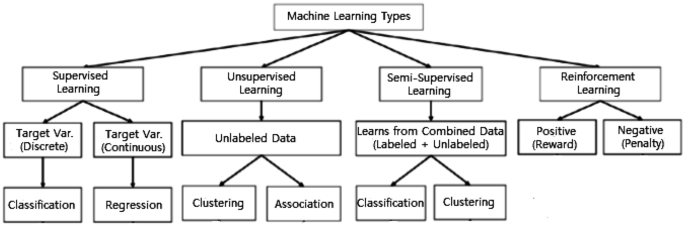
Machine Learning techniques are mainly divided into four categories: Supervised learning, Unsupervised learning, Semi-supervised learning, and Reinforcement learning as shown in in the following Figure.
Supervised learning is typically a machine learning technique to learn a function that maps an input to an output based on sample input-output pairs. It uses labeled training data and a collection of training examples to infer a function. Supervised learning is carried out when certain goals are identified to be accomplished from a certain set of inputs, i.e., a task-driven approach.
The most common supervised tasks are ‘classification’ that separates the ‘discrete data’, and ‘regression’ that fits the ‘continuous data’.
What is Supervised Machine Learning?
Supervised Machine Learning is a technique that learns from labeled training data to help you predict outcomes for unseen data. In supervised learning, you train the machine using data that is labeled. It means some data is already tagged with correct answers.
It can be compared to learning in the presence of a supervisor. In this technique, we have labeled data, which means each piece of data comes with a special label. Machine learning model can learn from these labeled examples and make predictions on new data.
An example of supervised learning is email spam detection program. Here, the model is trained on a dataset where each email is labeled as either “spam” or “not spam”. By learning from these labeled examples, the model can generalize its knowledge and accurately classify incoming emails as spam or not.
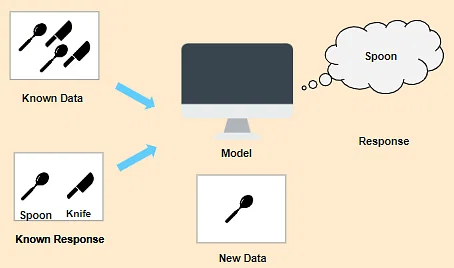
Figure source: simplilearn.com
Discrete and Continuous Labels
Discrete is a statistical term, referring to outcomes that can only take on a finite number of values. Discrete labels are used when the target variable falls into a number of distinct categories or classes. These labels are also known as nominal or categorical labels. A categorical label has a discrete set of possible values, like ‘is a car’ or ‘is not a car’. Discrete labels are associated with classification problems, where the aim is to assign a category or class to a given input.
Continuous labels are used when the target variable represents a continuous quantity. These labels can take on any numeric value within a certain range. This means that a continuous label doesn’t have a discrete set of possible values. These labels are also known as numerical labels. Continuous labels are associated with regression problems, where the aim is to predict a continuous value.
Type of labels determines the type of machine learning problem you are dealing with.
Classification and Regression
In regression problems, the goal is to predict a continuous value. For example, predicting the price of a house based on its features, such as the number of bedrooms, square footage, and location.
Classification means to group the output inside a class. In classification problems, the goal is to assign input data to one of several predefined classes (e.g., identifying whether an image is a cat or a dog). If the model tries to label input into two distinct classes, it is called binary classification. Selecting between more than two classes is referred to as multiclass classification.
Importance of Supervised Learning
- Learning algorithm iteratively makes predictions on the training dataset and is corrected by the supervisor, and the learning process stops when the algorithm achieves an acceptable level of performance.
- Supervised Learning gives experience to the algorithm which can be used to output the predictions for new unseen data.
- Experience also helps in optimizing the hyperparameters of the model.
Advantages of Supervised Learning
- Supervised machine learning allows you to produce a data output from the previous experience.
- It helps you to optimize performance criteria using experience.
- Supervised machine learning helps you to solve various types of real-world computational problems.
Disadvantages of Supervised Learning
- Lots of good examples need to be used to train the model.
- Time cost is very large for supervised learning.
- Unwanted data could reduce the accuracy.
- Preprocessing step of data is essential.
- Classifying big data can be a challenge.
Applications of Supervised Learning
- Speech Recognition
- This is the application where you teach the algorithm about your voice and it will be able to recognize you.
- Spam Detection
- This application is used where spam email is to be blocked. Microsoft smartscreen has an algorithm that learns the different keywords which could be fake such as “you are the winner” and so forth and blocks those emails directly.
- Risk Assessment
- Supervised learning is used to assess the risk in financial domains in order to minimize the risk portfolio of the companies.
- Image Classification
- It is one of the main use cases of demonstrating supervised machine learning. For example, social medias can recognize your friend in a picture from an album of tagged photos.
- Fraud Detection
- To identify whether the transactions made by the user are authentic or not.
Supervised Learning Algorithms
The most commonly used algorithms are:
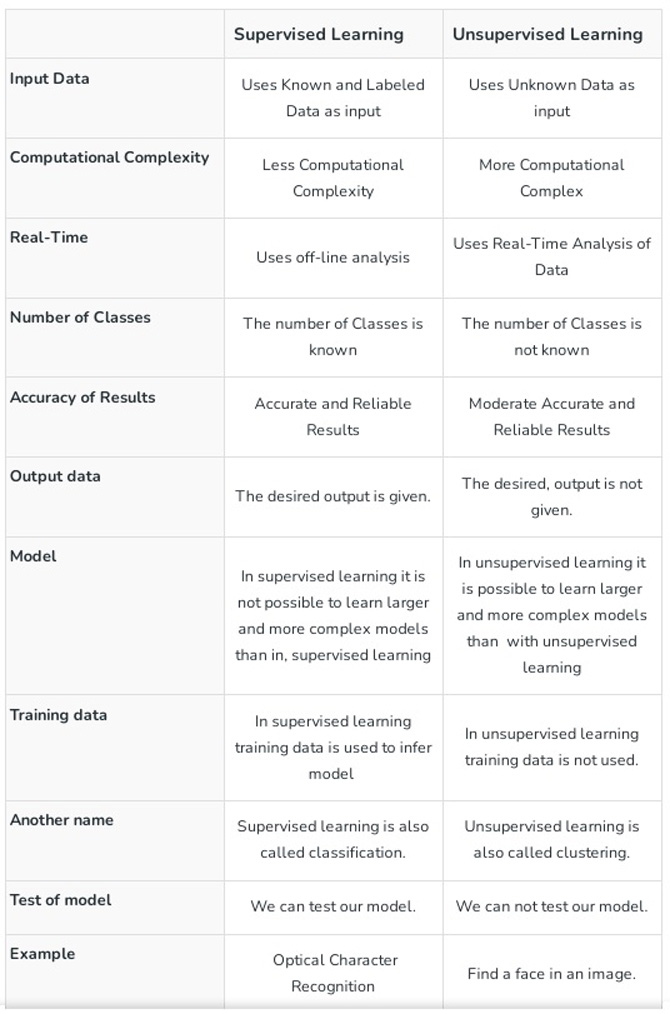
Supervised vs. Unsupervised Machine Learning
Supervised machine learning algorithms utilize the information on the class membership of each training instance, that allows algorithms to detect pattern. In unsupervised learning algorithms, unlabeled instances are used.
Recommended for you:
- Gradient Boosting Algorithm Explained
- Semi Supervised Machine Learning
- Multi Task Learning in Machine Learning


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained