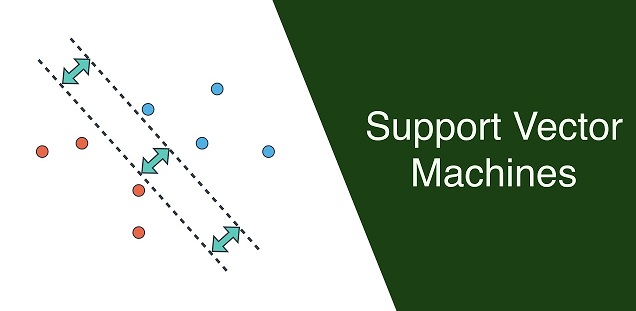
Support Vector Machines (SVM), a fast and dependable algorithm that performs very well with a limited amount of data to analyze. SVM uses supervised learning models to solve complex classification, regression, and outlier detection problems by performing optimal data transformations that determine boundaries between data points based on predefined classes, labels, or outputs. In this post, you’ll learn the basics of SVM, and how to use.
What is Support Vector Machines?
A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. Also can be used for regression challenges. However, it is mostly used in classification problems, such as text classification. In the SVM algorithm, we plot each data item as a point in n-dimensional space (where n is the number of features you have), with the value of each feature being the value of a particular coordinate. Then, we perform classification by finding the optimal hyperplane that differentiates the two classes very well.
Compared to newer algorithms like neural networks, they have two main advantages: higher speed and better performance with a limited number of samples. This makes the algorithm very suitable for text classification problems, where it’s common to have access to a dataset of at most a couple of thousands of tagged samples.
Definition the main terms of SVM
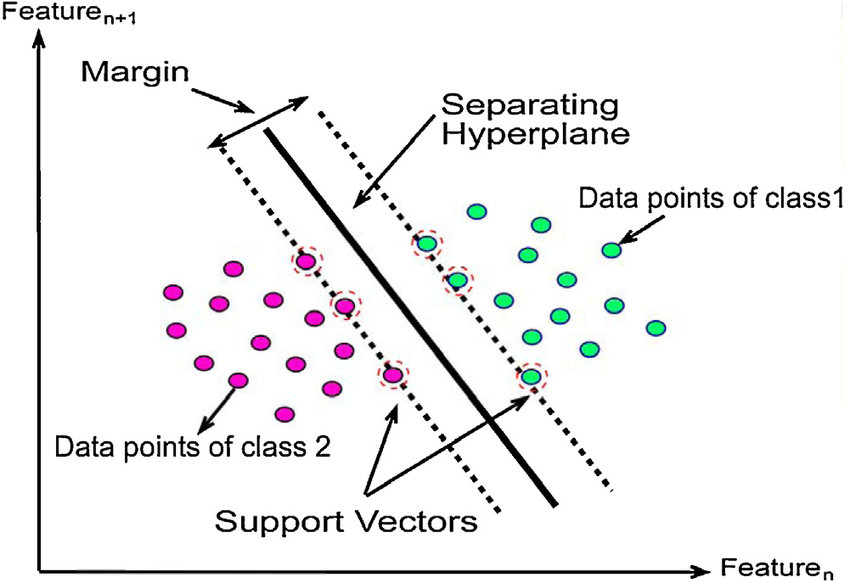
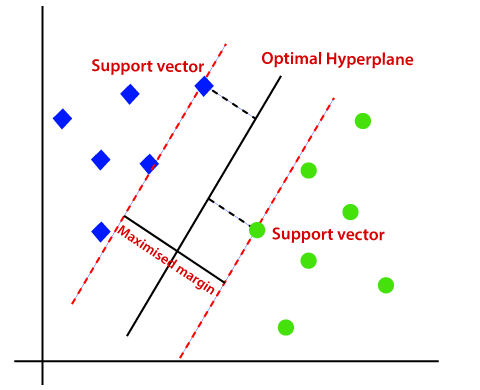
- Support Vectors:
- These are the points that are closest to the hyperplane. A separating line will be defined with the help of these data points.
- Margin:
- It is the distance between the hyperplane and the observations closest to the hyperplane (support vectors). In SVM large margin is considered a good margin.
Types of Support Vector Machine
- Linear SVM
- When the data is perfectly linearly separable only then we can use Linear SVM. Perfectly linearly separable means that the data points can be classified into 2 classes by using a single straight line.
- Non-Linear SVM
- When the data is not linearly separable then we can use Non-Linear SVM, which means when the data points cannot be separated into 2 classes by using a straight line then we use some advanced techniques like kernel tricks to classify them.
How does Support Vector Machine work?
Linear SVM
SVM is defined such that it is defined in terms of the support vectors only, whereas in logistic regression the classifier is defined over all the points. Let’s understand the working of SVM using an example. Suppose we have a dataset that has two classes (green and blue).
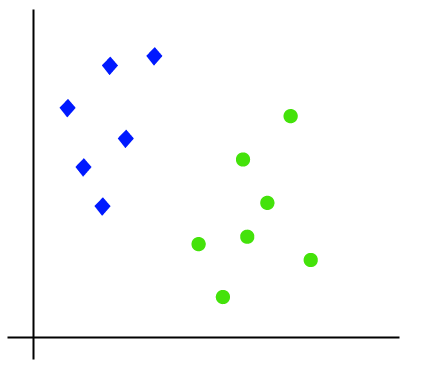
Image Source: www.analyticsvidhya.com
To classify these points, we can have many decision boundaries, but the question is which is the best and how do we find it?
Since we are plotting the data points in a 2D graph we call this decision boundary a “straight line” but if we have more dimensions, we call this decision boundary a “hyperplane”.
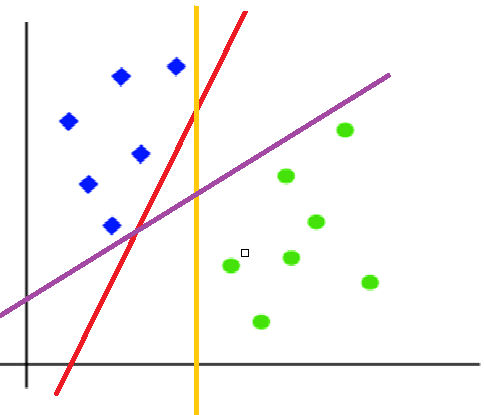
Adding Decision boundries to our seperate Blue and Green datapoints
The best hyperplane is, that has the maximum distance from both the classes, and this is the main aim of SVM. This is done by finding different hyperplanes which classify the labels in the best way then it will choose the one which is farthest from the data points or the one which has a maximum margin.
Nonlinear SVM
Non-linear data that cannot be segregated into distinct categories with the help of a straight line is classified using nonlinear SVM. Take a look at this case:
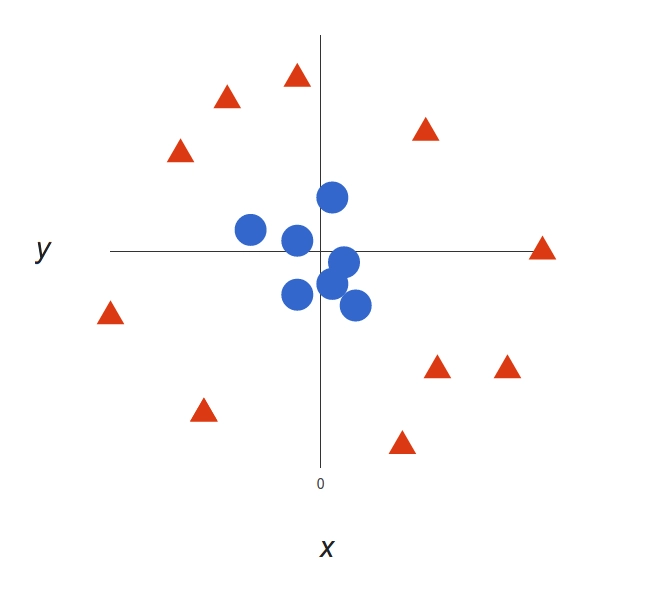
A more complex dataset
It’s pretty clear that there’s not a linear decision boundary. However, the vectors are very clearly segregated and it looks as though it should be easy to separate them. So we will add a third dimension. Up until now we had two dimensions: x and y. We create a new z dimension, and we rule that it be calculated a certain way that is convenient for us: z = x² + y².
This will give us a 3D space. Taking a slice of that space, it looks like this:
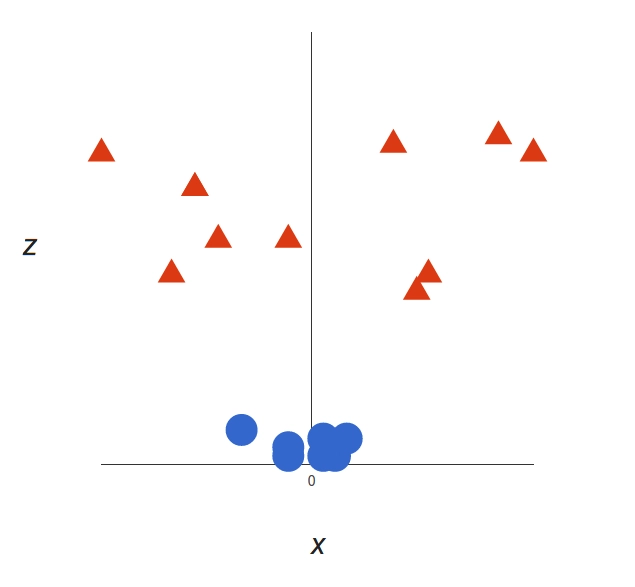
From a different perspective, the data is now in two linearly separated groups
What can SVM do with this? Let’s see:
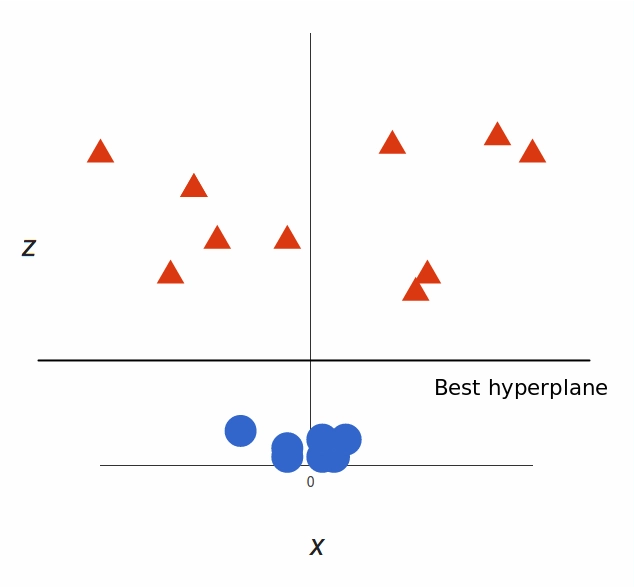
Note that since we are in three dimensions now, the hyperplane is a plane parallel to the x axis at a certain z (let’s say z = 1).
What’s left is mapping it back to two dimensions:
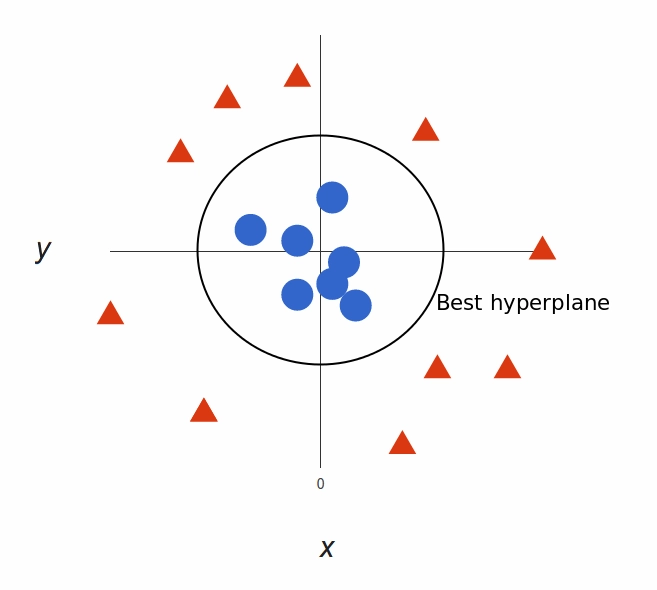
Back to our original view, everything is now neatly separated
Our decision boundary is a circumference of radius 1, which separates both tags using SVM.
Hard Margin vs. Soft Margin
The difference between a hard and a soft margin in SVM lies in the separability of the data. If our data is linearly separable, we go for a hard margin.
In the presence of the data points that make it impossible to find a linear classifier, we would have to be more lenient and let some of the data points be misclassified. In this case, a soft margin SVM is appropriate.
And sometimes, the data is linearly separable, but the margin is so small that the model becomes prone to overfitting. So in this case, we can opt for a larger margin by using soft margin SVM in order to help the model generalize better.
Advantages of SVM
- The SVM is an effective tool in high-dimensional spaces, which is particularly applicable to document classification and sentiment analysis.
- Since only a subset of the training points are used in the actual decision process of assigning new members, only these points need to be stored in memory and calculated upon when making decisions.
- Class separation is often highly non-linear. The ability to apply new kernels allows substantial flexibility for the decision boundaries, leading to greater classification performance.
- It works really well with a clear margin of separation.
- It is effective in high-dimensional spaces.
- It is effective in cases where the number of dimensions is greater than the number of samples.
Disadvantages of SVM
- In situations where the number of features for each object exceeds the number of training data samples, SVMs can perform poorly.
- If the high-dimensional feature space is much larger than the samples, then there are less effective support vectors on which to support the optimal linear hyperplanes, leading to poorer classification performance as new unseen samples are added.
- It doesn’t perform well when we have a large data set because the required training time is higher.
- It also doesn’t perform very well when the data set has more noise, i.e., target classes are overlapping.
Applications of Support Vector Machines
Here, we’ll look at some of the top applicatins of SVMs:
- Cancer detection
- Protein remote homology detection
- Data classification
- Facial detection
- Expression classification
- Surface texture classification
- Text categorization
- Handwriting recognition
- Speech recognition
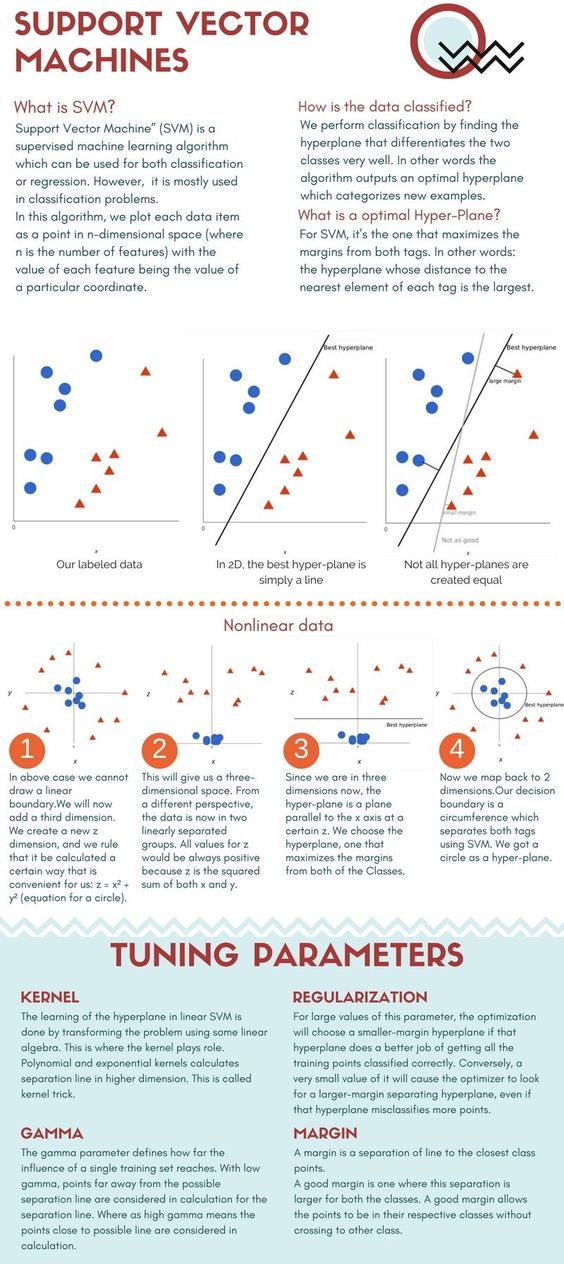
Infographic
Recommended for you:
Text Mining Algorithms
Reinforcement Learning in Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained