Machine learning uses programmed algorithms that receive and analyze data to predict values within an acceptable range. As new data is fed to these algorithms, they learn and optimize their operations to improve performance, developing intelligence over time. There are four types of machine learning algorithms: supervised, semi-supervised, unsupervised and reinforcement.
What is Machine Learning Algorithm?
A machine learning algorithm refers to a code (math or logic) that enables professionals to study, analyze, comprehend, and explore datasets. Each algorithm follows a series of instructions to accomplish the objective of making predictions or categorizing information by learning, and discovering patterns embedded in the data.
The range of possible applications for machine learning algorithms is quite broad and comprehensive. Image and audio detection, natural language processing, recommendation systems, & autonomous cars are just some of the applications that can make use of these technologies.
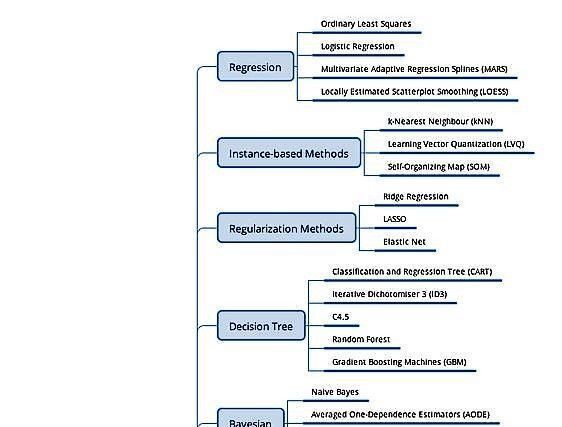
Machine learning algorithm is the fundamental building block for machine learning model. Here are ten algorithms you need to know in your machine learning career.
Linear Regression Algorithm
Linear regression is a supervised learning algorithm used to predict and forecast values within a continuous range, such as sales or prices.
Linear regression gives a relationship between input (x) or independent variables and an output variable (y) or dependent variables.
Linear regression in machine learning is a kind of algorithm, where the relationship between independent and dependent variables is established by fitting them to a regression line. This line has a mathematical representation given by the linear equation y = mx + c, where y represents the dependent variable, m = slope, x = independent variable, and b = intercept.
The objective of linear regression is to find the best fit line that reveals the relationship between variables y and x.
Logistic Regression Algorithm
Logistic regression is a supervised learning algorithm used for binary classification, such as deciding whether an image fits into one class or another class.
Logistic regression technically predicts the probability that an input can be categorized into a single primary class. In practice, this can be used to group outputs into one of two categories (“the primary class” or “secondary class”). This is achieved by creating a range for binary classification, such as any output between 0 – 0.49 is put in one group and any between .50 – 1.00 is put in another.
Mathematically, logistic regression is represented by the equation: y = e^(b0 + b1x) / (1 + e^(b0 + b1x))
x = input value, y = predicted output, b0 = bias or intercept term, b1 = coefficient for input (x).
As a result, the binary outcomes of logistic regression facilitate faster decision-making as you only need to pick one out of the two alternatives.
Naive Bayes Algorithm
Naive Bayes is a probabilistic machine learning algorithm based on the Bayesian probability model and is used to address either binary or multi-classification. The fundamental assumption of the algorithm is that features under consideration are independent of each other and a change in the value of one does not impact the value of the other.
mathematical representation of the algorithm:
If X, Y = probabilistic events, P (X) = probability of X being true, P(X|Y) = conditional probability of X being true in case Y is true.
Then, Bayes’ theorem is given by the equation:
P (X|Y) = (P (Y|X) x P (X)) /P (Y)
A naive Bayesian approach is easy to develop and implement. It is useful for making real-time predictions. Its applications include spam filtering, sentiment analysis and prediction, and others.
Decision Tree Algorithm
Decision tree is a supervised learning algorithm used for classification and regression problems.
Resembling a graphic flowchart, a decision tree begins with a root node, which asks a specific question of data and then sends it down a branch depending on the answer. These branches each lead to an internal node, which in turn asks yet another question of the data before directing it toward another branch depending on the answer. This continues until the data reaches an end node, also called a leaf node, that doesn’t branch any further.
Based on the values of the features, they divide the data in a recursive manner into smaller subsets. Decision tree is common in machine learning because they can handle complex data sets with relative simplicity.
Random Forest Algorithm
Random forest algorithm uses an ensemble of decision trees to make predictions.
In a random forest, many decision trees (hundreds or even thousands) are each trained using a random features of the training set a method known as “bagging”. Afterward, puts the same data into each decision tree in the random forest and tally their end results. The most common result is then selected as the most likely outcome for the data set.
Although they can become complex and require significant time, random forest corrects the common problem of overfitting that can occur with decision tree. Overfitting is when an algorithm coheres too closely to its training data set, which can negatively impact its accuracy when introduced to new data later.
Random forest is utilized extensively in fields like natural language processing and computer vision due to their high accuracy and stability.
K-Nearest Neighbor Algorithm
K-Nearest Neighbors (KNN) is a straightforward and efficient machine learning algorithm for both regression and classification problems.
It works by making a prediction based on the labels or values of the “K” closest neighbors to a given test example. For example, if an output is closest to a cluster of green points on a graph rather than a cluster of red points, then it would be classified as a member of the green group. This approach means that KNN algorithm can be used to either classify known outcomes or predict the value of unknown ones.
KNN is frequently used in fields like image classification and recommendation systems.
K-Means Algorithm
K-Means is a distance-based unsupervised algorithm used for accomplishes clustering tasks.
K-Means uses the proximity of an output to a cluster of data points to identify it. Each of the clusters is defined by a centroid or a real center point for the cluster. K-Means is useful on large data sets, especially for clustering, though it can falter when handling outliers.
The clusters under K-Means are formed using these steps:
- Initialization: The K-Means algorithm selects centroids for each cluster (‘K’ number of clusters).
- Assign objects to centroid: Clusters are formed with the closest centroids (K clusters) at each data point.
- Centroid update: Create new centroids based on existing clusters and determine the closest distance for each data point based on new centroids. Here, the position of the centroid also gets updated whenever required.
- Repeat the process till the centroids do not change.
Support Vector Machine Algorithm
Support vector machine algorithm is a supervised machine learning algorithm, used to accomplish both classification and regression tasks. That plot each piece of data in the n-dimensional space (n referring to the number of features). Each feature value is associated with a coordinate value, making it easier to plot the features.
Under SVM, vectors map the relative disposition of data points in a dataset, while support vectors delineate the boundaries between different groups, features.
Classification is further performed by distinctly determining the hyper plane that separates the two sets of support vectors or classes. A good separation ensures a good classification between the plotted data points.
At low feature levels, the SVM is two-dimensional, but where there’s a higher recognized number of groups or types, it becomes three-dimensional.
Artificial Neural Networks
Artificial neural networks (ANNs) are machine learning algorithm that mimic the human brain to solve complex problems. ANN has three or more interconnected layers in its computational model that process the input data.
- The first layer is the input layer or neurons that send data to deeper layers.
- The second layer or hidden layer. The components of this layer change or tweak the information received through various previous layers by performing a series of data transformations. These are also called neural layers.
- The third layer is the output layer that sends the final output data for the problem.
ANN algorithms find applications in smart home devices and computational vision, specifically in detection systems and autonomous vehicles.
Recurrent Neural Networks
Recurrent neural networks (RNNs) refer to a specific type of artificial neural networks that processes sequential data.
Here, the result of the previous step acts as the input to the current step. This is facilitated via the hidden state that remembers information about a sequence. It acts as a memory that maintains the information on what was previously calculated. The memory of RNN reduces the overall complexity of the neural network.
Recurrent neural network analyzes time series data and possesses the ability to store, learn, and maintain contexts of any length. RNN is used in cases where time sequence is of paramount importance, such as speech recognition, language translation, video processing, text generation, and image captioning.
Recommended for you:


MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained