Boosting algorithms become mainstream in the machine learning community. Boosting algorithms grant superpowers to machine learning models to improve their prediction accuracy.
Tree boosting is a highly effective machine learning method. In this post, we describe a scalable end to end tree boosting system called XGBoost, which is used widely by data scientists to achieve state of the art results on many machine learning challenges.
Before understanding the XGBoost, we first need to understand the decision tree, Boosting, Gradient Boosting.
What is Decision Tree
Decision tree is a tree-like structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node holds a class label.
A tree can be learned by splitting the source dataset into subsets based on an attribute value test. This process is repeated on each derived subset in a recursive manner called recursive partitioning.
The recursion is completed when splitting no longer adds value to the predictions.
What is Boosting?
Boosting is an ensemble technique that attempts to build a strong learners from the number of weak learners. It is done by building a model by using weak models in series.
First, a model is built from the training data. Then the second model is built which tries to correct the errors present in the first model. This procedure is continued and models are added until either the complete training dataset is predicted correctly or the maximum number of models are added.
Weak learner is one that classifies the data so poorly when compared to random guessing. The weak learners are mostly decision trees, but other models can be used.
What is Gradient Boosting?
Gradient boosting also called Generalization of AdaBoost, is one of the most powerful techniques for building machine learning models. The main objective of Gradient Boost is to minimize the loss function by adding weak learners using a gradient descent optimization algorithm.
Generalization allowed arbitrary differentiable loss functions to be used, expanding the technique beyond binary classification problems to support regression, and multiclass classification.
Loss Function estimate how best is the model in making predictions with the given data.
What is XGBoost?
XGBoost stands for “Extreme Gradient Boosting” and it has become one of the most popular machine learning algorithms due to its ability to handle large datasets, and ability to achieve state of the art performance in many machine learning tasks such as classification and regression.
Gradient boosting is a foundational approach to many machine learning algorithms. These algorithms choose how to build a more powerful model using the gradient of a loss function that captures the performance of a model.
It is an optimized distributed gradient boosting library designed for efficient and scalable training of machine learning models. It is an ensemble learning method that combines the predictions of multiple weak models to produce a stronger prediction.
One of the key features of XGBoost is its efficient handling of missing values, which allows it to handle dataset with missing values without requiring significant preprocessing. Additionally, XGBoost has built-in support for parallel processing, making it possible to train models on large datasets in a reasonable amount of time.
XGBoost is also highly customizable and allows for fine-tuning of various model parameters to optimize performance.
How does XGBoost Algorithm work?
XGBoost is an efficient implementation of the gradient boosted trees algorithm.
When using gradient boosting, the weak learners are trees, and each tree maps an input data point to one of its leafs that contains a continuous score.
XGBoost minimizes a regularized objective function that combines a convex loss function based on the difference between the predicted and target values and a penalty term for model complexity.
The training proceeds iteratively, adding new trees that predict the residuals or errors of prior trees that are then combined with previous trees to make the final prediction. It’s called gradient boosting because it uses a gradient descent algorithm to minimize the loss when adding new models.
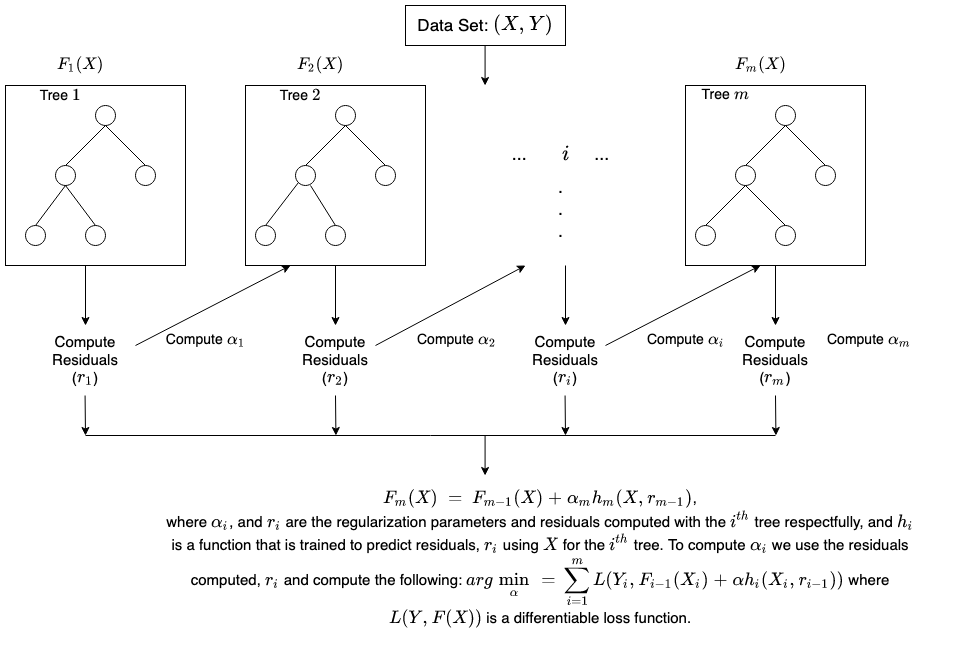
Image source: docs.aws.amazon.com
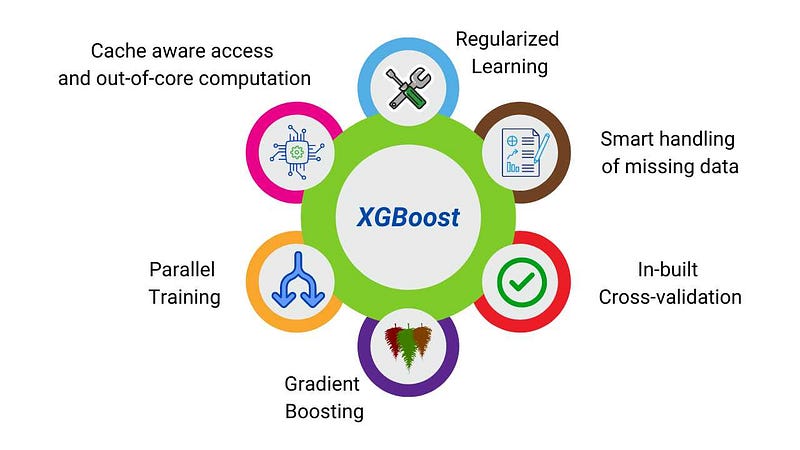
XGBoost Features
- Weighted Quantile Sketch
- XGBoost has built-in distributed weighted quantile sketch algorithm that makes it easier to effectively find the optimal split points among weighted datasets.
- Gradient Tree Boosting
- Tree ensemble model cannot be optimized using traditional optimization methods in Euclidean space. Instead, the model is trained in an additive manner.
- Sparsity Awareness
- shrinkage techniques are used to further prevent overfitting. Shrinkage scales newly added weights by a factor η after each step of tree boosting. Shrinkage reduces the influence of each tree and leaves space for future trees to improve the model.
- Parallel Training
- Parallelization of tree construction using all of your CPU cores during training.
- Cache Aware Access
- XGBoost designed to make optimal use of hardware. This is done by allocating internal buffers in each thread, where the gradient statistics can be stored.
- Out of core Computation
- Blocks for Out-of-core Computation for very large datasets that don’t fit into memory.
- Distributed Computing
- used for training very large models using a cluster of machines.
- Column Block for Parallel Learning
- In order to reduce the cost of sorting, the data is stored in the column blocks in sorted order in compressed format.
- Regularization
- XGBoost uses both Lasso and Ridge Regression regularization to penalize the highly complex model. The regularization term helps to smooth the final learned weights to avoid overfitting.
- Tree Pruning
- XGBoost uses max_depth parameter as specified the stopping criteria for the splitting of the branch, and starts pruning trees backward. This depth-first approach improves computational performance significantly.
- Cross-validation
- XGboost implementation comes with a built-in cross-validation method. This helps algorithm prevents overfitting when the dataset is small.
XGBoost Advantages
- Performance
- XGBoost dominates structured datasets on classification and regression predictive modeling problems.
- Scalability
- XGBoost is designed for efficient and scalable training of machine learning models, making it suitable for large datasets.
- Customizability
- XGBoost has a wide range of hyperparameters that can be adjusted to optimize performance, making it highly customizable.
- Handling of Missing Values
- XGBoost has built-in support for handling missing values.
- Interpretability
- XGBoost provides feature importances, allowing for a better understanding of which variables are most important in making predictions.
- Execution Speed
- XGBoost was almost always faster when compared to the other algorithms.
XGBoost Disadvantages
- Computational Complexity
- It can be computationally, memory-intensive, especially when training large models, making it less suitable for resource-constrained computers.
- Overfitting
- It can be prone to overfitting, when trained on small datasets or when too many trees are used in the model.
- Hyperparameter Tuning
- XGBoost has many hyperparameters that can be adjusted. However, finding the optimal set of parameters can be time-consuming and requires expertise.
We hope we’ve given you good understanding of XGBoost Algorithm.
We are always open to your questions and suggestions.
You can share this post on LinkedIn, Facebook, Twitter, so someone in need might stumble upon this.
Recommended for you:
Adaptive Boosting Algorithm Explained
Gradient Descent Machine Learning

MOST COMMENTED
Tutorial
Important Methods in Matplotlib
Machine Learning
Bias and Variance Tradeoff Machine Learning
Tutorial
Multiclass and Multilabel Classification
Machine Learning
Reinforcement Learning in Machine Learning
Deep Learning
Alexnet Architecture Code
Machine Learning
Machine Learning Models Explained